AudioSep可以从任何混合的音频信号中提取出特定的声音成分并分离出来。与传统的声音分离模型不同,AudioSep允许用户通过自然语言描述来指定他们想要分离的声音。例如,用户可以简单地输入“分离出钢琴声”或“去除背景噪音”等指令。
AudioSep专为使用自然语言查询进行开放领域的声音分离而设计。它在分离音频事件、乐器和增强语音方面表现出色。
AudioSep特点:
1、声音分离能力:AudioSep的核心功能是从复杂的音频环境中分离出特定的声音,这在多种应用场景中都是非常有用的。
2、自然语言查询:与传统的声音分离模型不同,AudioSep允许用户通过自然语言描述来指定他们想要分离的声音,这大大提高了模型的灵活性和易用性。例如,用户可以简单地输入“分离出钢琴声”或“去除背景噪音”等指令。
3、零样本泛化:AudioSep具有很强的零样本泛化能力,这意味着它能够在没有见过的、未标记的数据上表现得相当好。例如,在智能家居环境中,可能有各种各样的声音源(如电视、空调、人声等),一个能够零样本泛化的模型可以更准确地识别和分离这些声音,而无需为每一种声音进行单独的训练。
4、开放领域应用:AudioSep是一个开放领域的声音分离模型,这意味着它不仅限于处理特定类型或类别的声音。无论是日常生活中的噪音,还是专业领域(如医疗、广播)中的特定声音,AudioSep都有可能处理。
项目及演示:https://audio-agi.github.io/Separate-Anything-You-Describe/
论文:https://arxiv.org/abs/2308.05037
GitHub:https://github.com/Audio-AGI/AudioSep
HuggingFace演示:https://huggingface.co/spaces/Audio-AGI/AudioSep
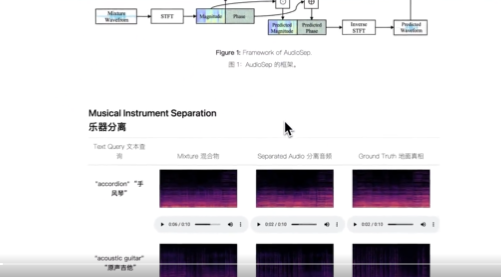
工作原理:
模型架构:
AudioSep主要由两个关键组件组成:文本编码器和声音分离模型。文本编码器负责处理自然语言查询,将其转换为一个固定长度的向量。声音分离模型则负责从混合音频中提取目标声音。
1、文本编码器: 这一部分使用自然语言处理(NLP)技术,通常是某种形式的Transformer模型,来理解用户的自然语言查询。它将文本信息编码成一个高维向量。
2、声音分离模型: 这一部分通常是一个深度神经网络,它接收文本编码器输出的高维向量和混合音频作为输入,然后输出分离后的音频。
数据流与处理:
1、接收查询和音频: 当用户提出一个自然语言查询和一个混合音频时,这两者都会被送入模型。
2、文本编码: 自然语言查询首先通过文本编码器进行处理,转换为一个高维向量。
3、音频分离: 高维向量和混合音频一同输入到声音分离模型中,模型会输出分离后的音频。
4、结果输出: 用户最终会收到分离后的音频,这一过程可以实时进行,也可以是离线处理。
AudioSep模型在多种任务上进行了广泛评估,包括音频事件分离、乐器分离和语音增强。该模型展示了强大的分离性能和令人印象深刻的零样本泛化能力。