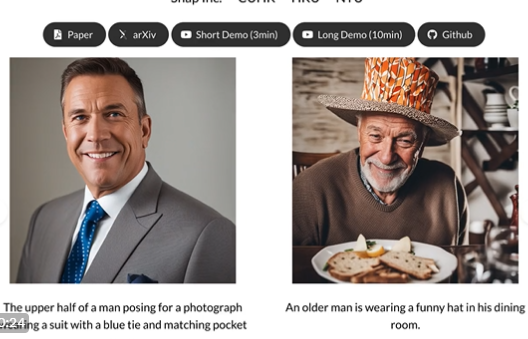
能生成逼真的人像图像。
该模型生成的人体图像不仅逼真,而且具有高度的三维结构感,它能理解图像背后的三维结构。就像你不仅看到一个人,还能感知他站立的方式、面部的轮廓等。
HyperHuman在一个包含了3.4亿张图像和全面的注释,如人体姿势、深度和表面法线的数据集上进行训练。
生成的人体图像不仅逼真,而且具有高度的三维结构感,这在游戏、电影制作或者虚拟现实中有很高的应用价值。你可以通过简单的描述或者骨架图来生成各种各样的人体图像,无需专业的图像设计技巧。
主要特点:
人类宇宙数据集(HumanVerse Dataset):这是一个大规模的以人为中心的数据集,包含了3.4亿张图像和全面的注释,如人体姿势、深度和表面法线。这为模型提供了丰富的训练数据。
潜在结构扩散模型:这是一个能同时去噪深度和表面法线以及合成的RGB图像的模型。这意味着它不仅仅是生成图像,还能理解图像的三维结构。
结构引导的精炼器(Structure-Guided Refiner):这是一个用于进一步提高图像质量的组件。它接受潜在结构扩散模型的输出,并进行精炼,以生成更高分辨率和更逼真的图像。
项目及演示:https://snap-research.github.io
论文:https://arxiv.org/abs/2310.08579
GitHub:https://github.com/snap-research/HyperHuman
工作原理:
1、数据准备阶段:首先,使用人类宇宙数据集进行模型的训练。这个数据集包含了大量的人体图像以及与之相关的注释,如深度、表面法线和姿势。
2、潜在结构扩散模型:在这个阶段,模型接受文本描述和姿势骨架作为输入。这些输入通过一个编码器-解码器架构进行处理,生成一个去噪的图像、深度和表面法线。这一步是非常关键的,因为它不仅生成了图像,还生成了与图像相关的三维结构信息。
3、结构引导的精炼器:这个组件进一步提高了图像的质量。它接受潜在结构扩散模型的输出,并使用一个专门设计的神经网络进行精炼。这样,输出的图像不仅分辨率更高,而且更加逼真。