可赋予大语言模型视觉和绘图能力。
该项目由腾讯AILab-CVC团队开发,SEED的主要功能是将图像转换为一系列离散的视觉代码(visual codes)。它就像是一个“翻译器”,能把图片“翻译”成一种特殊的“语言”(视觉代码),这样机器人就能理解并处理它了。
这些代码具有1D因果依赖性和高级语义(SEED将图像信息转换成一串有顺序的代码,这些代码之间有因果关系,就像文本中的字或词。),使得它们能够与文本在同一个模型中进行处理。
项目:https://github.com/AILab-CVC/SEED
论文:https://arxiv.org/abs/2310.01218
演示:即将发布…
【如何工作?】
1、视觉代码生成:首先,SEED会把你给它的图片转换成一串特殊的代码(视觉代码)。这些代码包含了图片的所有重要信息,比如颜色、形状和物体。
2、与文本对齐:这些视觉代码是按照一定的顺序排列的,就像句子中的单词。这样,机器人就能像处理文本一样处理这些代码。
3、高级理解:更厉害的是,这些视觉代码还包含了图片的“意义”。比如,如果图片中有一只狗在跑,那么这些代码就能表达出“狗”和“跑”的概念。
4、多模态任务:一旦机器人通过SEED理解了这些视觉代码,它就能做很多之前做不了的事情,比如描述图片、回答关于图片的问题,甚至根据你的描述生成新的图片。
举例:
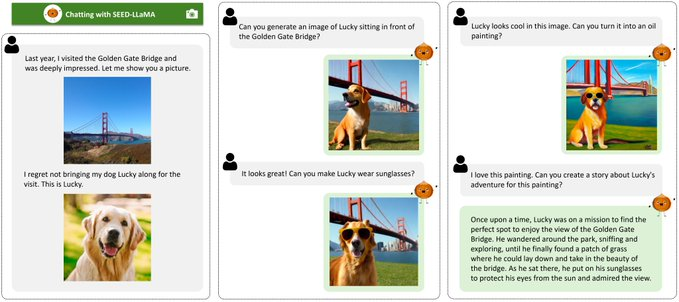
假设你有一张图片,图片中是一只黄色的小狗在草地上玩球。你问机器人:“这张图片是什么?”
没有SEED:机器人会说,“对不起,我看不懂图片。”
有SEED:SEED会先把图片转换成视觉代码,然后机器人会说,“这是一只黄色的小狗在草地上玩球。”
通过SEED,机器人不仅能理解文本,还能理解和生成图像,从而变得更加强大和多功能。
【集成到大型语言模型】
将SEED与大语言模型集成,可以实现多模态的处理能力。这样的模型不仅能处理纯文本任务,还能处理图像标题、图像/视频问题回答、以及文本到图像生成等多模态任务。
SEED-LLaMA:
SEED-LLaMA是一个预训练的大语言模型(LLM),它集成了SEED标记器。该模型在多模态数据上进行预训练,并通过指令调优(进行微调。
功能和性能:
能够处理图像标题、图像/视频问题回答和文本到图像生成等多种任务。
展示了多轮上下文中多模态生成的组合性突现能力。
这意味着SEED不仅能单独处理图像或文本,还能在多轮对话中结合两者生成新的内容。例如,它可以根据文本描述生成图像,然后再根据新的文本输入修改这个图像。
举例:
假设你首先描述了一个“红色的苹果”,SEED生成了一个红色苹果的图像。然后你又说,“加一个绿叶子”,SEED能在原来的红色苹果图像上添加一个绿叶子。
实验结果:
SEED-LLaMA在多个多模态任务上表现出色,包括图像标题、图像/视频问题回答和文本到图像生成等。