GPT 4最低 Google垫底
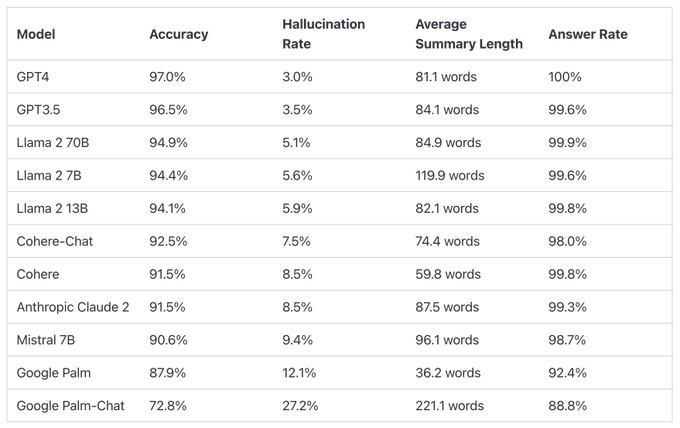
榜单比较了不同大语言模型在总结短文档时产生幻觉(hallucination)的表现。
GPT-4的准确率为97.0%,幻觉率为3.0%,回答率为100.0%。
Google Palm 的两款表现垫底,其中Palm Chat 2的准确率为72.8%,幻觉率高达27.2%,回答率为88.8%。
这个排行榜是由@vectara 的幻觉评估模型计算得出的,该模型评估了LLM在总结文档时引入幻觉的频率。排行榜的数据会随着模型和LLM的更新而定期更新。
排行榜上的数据包括不同模型的准确率、幻觉率、回答率和平均总结长度(词数)。例如,GPT-4的准确率为97.0%,幻觉率为3.0%,回答率为100.0%,平均总结长度为81.1词。而GPT-3.5、Llama 2 70B、Llama 2 7B等其他模型也有类似的数据。
为了确定这个排行榜,Vectara训练了一个模型来检测LLM输出中的幻觉,使用了来自对总结模型的事实一致性研究的各种开源数据集。然后,他们通过公共API向上述LLM提供了1000个短文档,并要求它们总结每个文档,仅使用文档中呈现的事实。在这1000个文档中,只有831个文档被每个模型总结,其余文档由于内容限制被至少一个模型拒绝。使用这831个文档,他们计算了每个模型的总体准确率(无幻觉)和幻觉率(100 – 准确率)。
该模型已在Hugging Face上开源供商业使用,网址为:https://huggingface.co/vectara/hallucination_evaluation_model
GitHub:https://github.com/vectara/hallucination-leaderboard