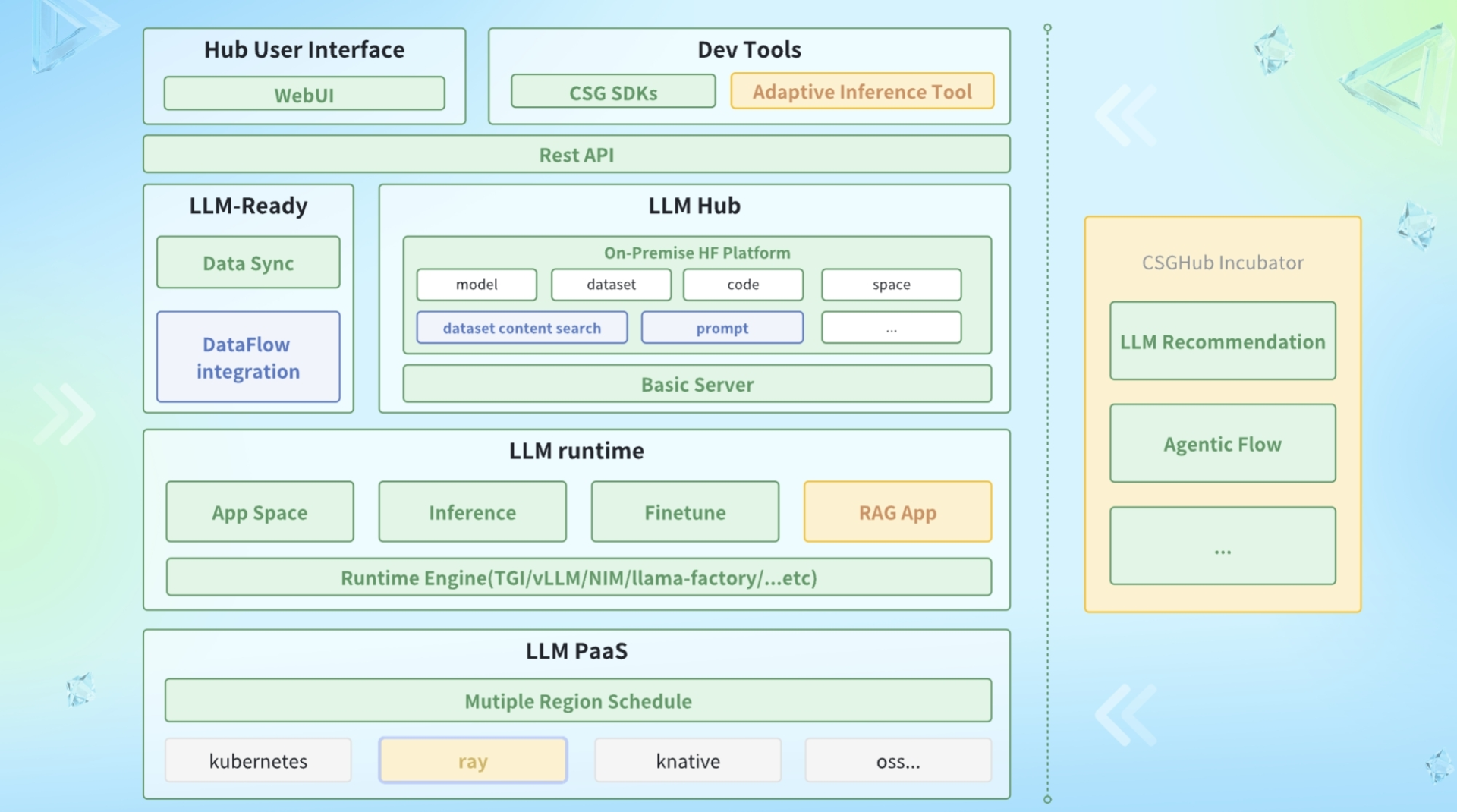
MistralAI开源全球首个(可能)基于MoE(Mixture of Experts)技术的大模型
有趣的事实:
- 以 87 GB 种子形式发布
- 似乎是 GPT-4 的缩小版
- 于 X 发布,无新闻稿且拒绝详细说明
专家混合 (MoE) 是LLM中使用的一种技术,旨在提高其效率和准确性。这种方法的工作原理是将复杂的任务划分为更小、更易于管理的子任务,每个子任务都由专门的迷你模型或“专家”处理。
- 专家层:这些是较小的神经网络,经过训练,在特定领域具有高技能。
2.门控网络:这是MoE架构的决策者。
延伸资料:
MoE技术简介:混合专家(MoE)是一种在大型语言模型(LLMs)中用于提高效率和准确性的技术。它通过将复杂任务分解为更小、更易管理的子任务来工作,每个子任务由一个专门的小型模型或“专家”处理。
MoE的组成部分:专家层:这些是训练有素的小型神经网络,擅长特定领域。每个专家以符合其特殊化的方式处理相同的输入。
门控网络:这是MoE架构的决策者。它评估哪个专家最适合给定的输入数据。网络计算输入与每个专家之间的兼容性得分,然后使用这些得分来确定每个专家在任务中的参与程度。
Mistral的MoE与GPT-4的比较:Mistral 8x7B使用与GPT-4非常相似的架构,但规模较小:共8个专家而不是16个(减少了2倍),每个专家有7B参数而不是166B(减少了24倍),总共约42B参数而不是1.8T(减少了42倍),与原始GPT-4相同的32K上下文。
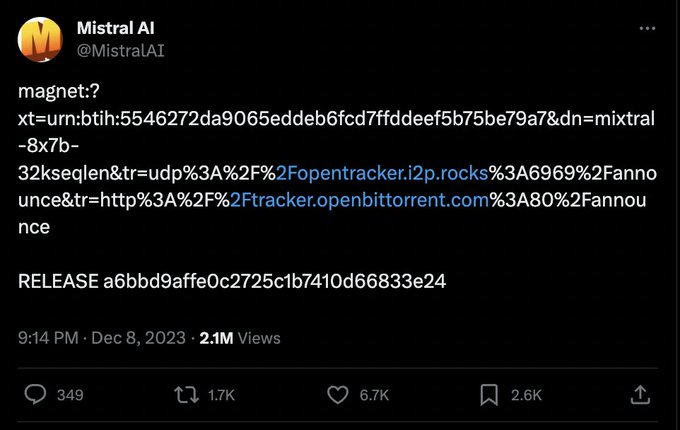
下载链接(磁力链接):
magnet:?xt=urn:btih:5546272da9065eddeb6fcd7ffddeef5b75be79a7&dn=mixtral-8x7b-32kseqlen&tr=udp%3A%2F%http://2Fopentracker.i2p.rocks%3A6969%2Fannounce&tr=http%3A%2F%https://t.co/g0m9cEUz0T%3A80%2Fannounce
RELEASE a6bbd9affe0c2725c1b7410d66833e24
MoE 8x7B在线体验,由@mattshumer_ 提供:https://replicate.com/nateraw/mixtral-8x7b-32kseqlen