如何使用能力较弱的 AI 模型来指导和控制更强大的 AI 模型。
这项研究的目的是为了解决一个问题:未来,当 AI 变得比人类更聪明时,人类如何能够有效地控制这些 AI。
研究结果显示:即使是相对较弱的 AI 模型也能在一定程度上有效地指导和影响更高级的 AI 模型的训练和行为。比如使用 GPT-2(一个较早期的 AI 模型)来帮助训练 GPT-4(一个更先进的 AI 模型)。
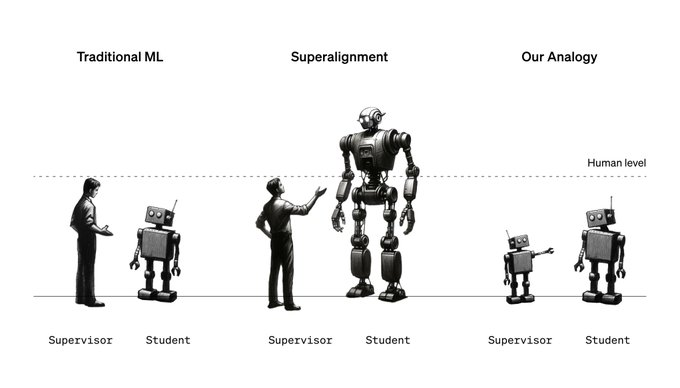
1、弱到强泛化的概念:这项研究探索了“弱到强泛化”(Weak-to-strong generalization)的概念,即利用较弱的 AI 模型来监督和指导较强的 AI 模型。
在这里,“弱”和“强”指的是模型的能力或复杂性。较弱的模型通常是早期开发的、能力有限的模型,而较强的模型则是更先进、更复杂的。
2、实验设置:在这项研究中,OpenAI 使用了 GPT-2 作为较弱的模型来监督 GPT-4 的训练。GPT-2 是一个较早期的 AI 语言模型,而 GPT-4 是一个更先进、更大、更复杂的模型。
通过这种设置,研究人员希望了解一个较弱的模型是否能够有效地影响一个较强模型的学习和行为。
研究人员使用了 GPT-2 的输出来向 GPT-4 传达任务。
3、研究结果:实验结果显示,这种方法使 GPT-4 达到了介于 GPT-3 和 GPT-4 之间的性能水平。这表明GPT-2 能够在某种程度上指导 GPT-4 学习特定的任务或行为。可以使 GPT-4 达到接近其完全潜力的性能水平,即使 GPT-2 的能力远不及 GPT-4。
这意味着一个较弱的 AI 模型(如 GPT-2),在作为监督者的角色时,也能够对一个更强大的 AI 模型(如 GPT-4)产生显著的影响。
4、研究意义:
这一发现对于 AI 对齐和控制具有重要意义:
- 弱监督的有效性:通常,我们认为一个 AI 模型的监督者需要比被监督的模型更强大或至少同等强大,以确保有效的学习和控制。然而,这项研究表明,即使是能力较弱的模型也能有效地指导更强大的模型。
- 对未来 AI 对齐的启示:随着 AI 技术的发展,未来可能出现远超人类智能的 AI 系统。在这种情况下,人类将成为相对弱的监督者。这项研究提供了一种可能的解决方案,即即使是弱监督者也可能有效地引导和控制超级智能 AI。
- 超人类智能的安全管理:这项研究为如何安全地管理和控制超人类智能 AI 提供了新的思路。它表明,通过合适的方法和技术,我们可以期望即使在人类成为弱监督者的情况下,也能保持对高级 AI 系统的有效控制。
为了启动该领域的更多研究,OpenAI公布了开源代码和论文。
GitHub:https://github.com/openai/weak-to-strong
论文:https://cdn.openai.com/papers/weak-to-strong-generalization.pdf
OpenAI还启动了一个价值 1000 万美元的资助计划,支持广泛的超人类 AI 对齐研究,特别是与弱到强泛化相关的研究。申请:https://openai.com/blog/superalignment-fast-grants