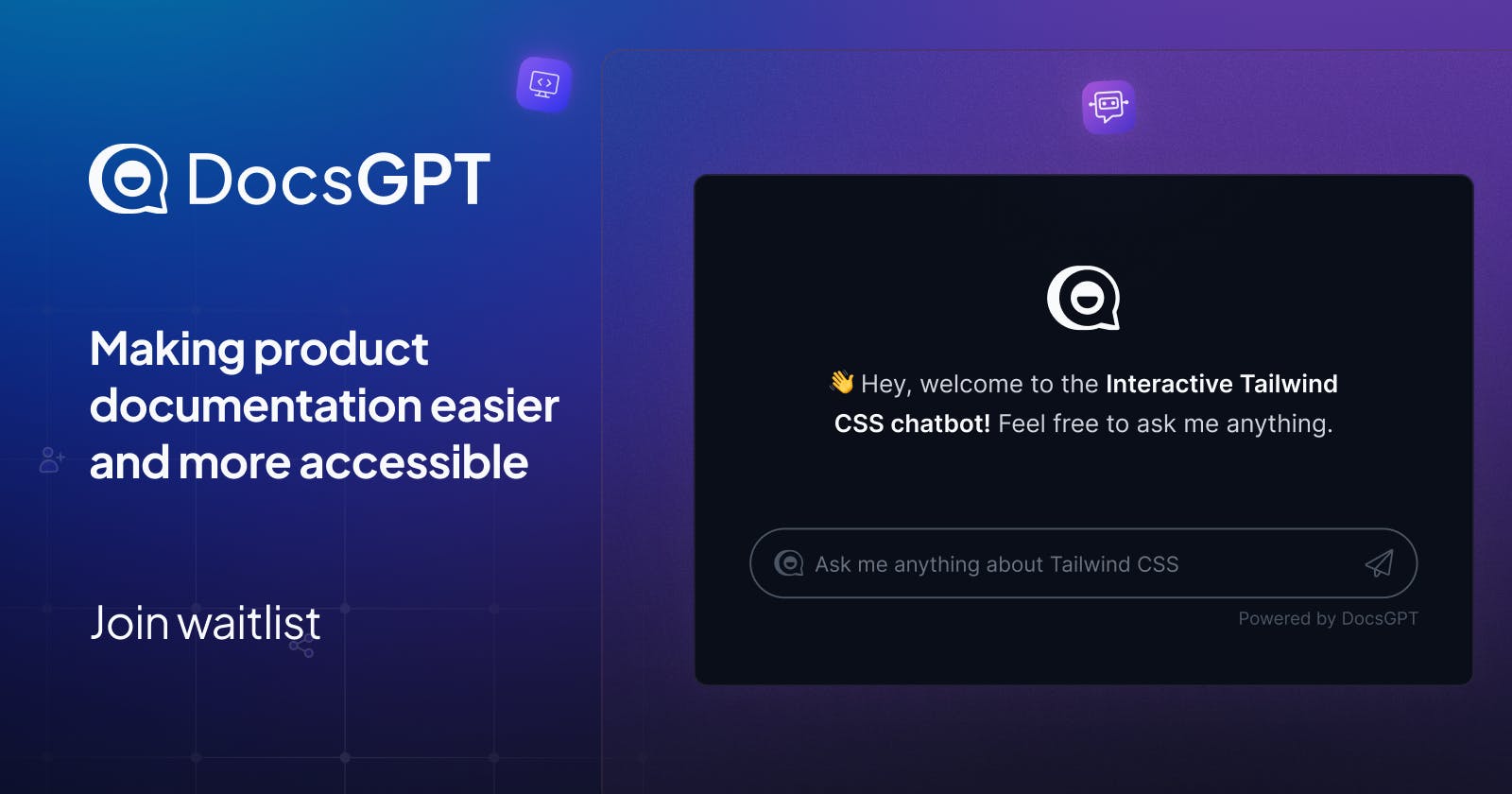
AI-Media2Doc 基于 AI 大模型, 一键将视频和音频转化为各种风格的文档, 无需登录注册, 前后端本地部署,以极低的成本体验 AI 视频/音频转风格文档服务。
项目概览
AI-Media2Doc 是一个完全开源(MIT 许可证)的 Web 工具,旨在将音频和视频内容一键转化为多种风格的文档,如小红书、微信公众号文章、知识笔记、思维导图、视频字幕等。
- 无需登录注册:项目设计强隐私保护,所有任务记录保存在本地。
- 前后端本地部署:支持用户在自己的环境中运行,无需依赖外部服务器。
- 前端采用 ffmpeg-wasm 技术:无需安装本地的 ffmpeg,即可在浏览器中处理音视频文件 。
- 支持丰富文档风格:生成内容包括小红书、微信公众号、知识笔记、思维导图、内容总结等
- AI 二次对话功能:可针对视频内容进行 AI 问答、进一步互动或内容扩展。
- 字幕导出 & 智能截图:
- 支持一键导出字幕文件。
- 能基于字幕信息自动截图,并插入到文章中,实现图文结合,无需视觉大模型 。
- 自定义 Prompt:前端允许用户配置自定义提示词(prompt)
- Docker 一键部署:项目支持使用 Docker 镜像快速部署,方便上手和集成
技术与更新亮点
- 项目由汉数(hanshuaikang)发起,目前已有约 2.2k Stars 和 268 Forks,说明社区关注度较高
- 项目首次创立于 2025 年 4 月 12 日,最近一次更新(v0.5.1)发布于 2025 年 8 月 3 日,添加了包括增强截图精度、多文件处理性能优化、Markdown 表格支持等功能
- 本地部署指南完善,包括 Docker 镜像构建、
variables.env配置与make run启动流程
使用流程概览(高层)
- 本地部署:通过 Docker 构建镜像,配置环境变量后执行
make run,快速启动服务。 - 上传音/视频文件:用户在前端界面上传文件。
- AI 转写与生成文档:系统自动识别音频内容(如使用 Whisper 技术),并生成结构化内容与文档,例如思维导图、笔记、公众号文章等。
- 互动与调整:用户可通过 AI 进行内容询问或调整,同时支持截图嵌入、字幕导出与自定义 Prompt 设置。
- 导出结果:完成后可导出文档、字幕,以及图文混排稿件,提升后续编辑效率。
适用场景与目标用户
- 自媒体创作者:快速将视频内容转为适配不同平台的图文格式。
- 学习者 / 学术记录者:将课程视频快速整理成笔记或思维导图。
- 企业 / 内部分享:用于会议录音转文档,便于归档与分享。
- 隐私敏感用户:愿意在本地部署避免数据上传云平台风险。
未来规划与社区响应
- 长远目标包括使用本地 fast-whisper 大模型进一步提升离线识别效率与准确率。
- 社区也期待更便捷的一键部署面板(1-panel 部署)以降低使用门槛。
总结:
AI-Media2Doc 是一个强隐私、开源、部署简便的工具,将视频和音频内容智能转化为多样化、高质量文档,对自媒体创作、学习笔记整理等场景非常实用。
你若想进一步了解如何部署、使用 Docker 或调试具体功能,也可以告诉我,我可以继续帮你解答!