AI-Media2Doc(作者:hanshuaikang) :AI 视频图文创作助手是一款 Web 工具, 基于 AI 大模型, 无需登录注册, 前后端本地部署,以极低的成本体验 AI 视频/音频转风格文档服务。
一、项目是什么
从它的 README:
“一键将音视频转化为小红书/公众号/知识笔记/思维导图/视频字幕等各种风格的文档。”
“AI 视频图文创作助手是一款 Web 工具,基于 AI 大模型,一键将视频和音频转化为各种风格的文档”
也就是说,它的核心目的是 把多媒体内容(音频 / 视频)转换成结构化 / 文本 / 文档形式的输出,而且可以输出多种风格(适合公众号、小红书、笔记、思维导图、字幕等)。
它是开源的(MIT 许可)并支持本地部署,也就是说不一定要用云服务或第三方平台。
它包含前端 + 后端 + 部署脚本(Docker)等。
二、主要功能 / 特性
这个项目在其 README 中列出了一些核心功能,我列在下面并做解读:
| 功能 | 解释 / 细节 |
|---|---|
| 完全开源 + 本地部署 | 使用 MIT 许可,用户可以把它部署在自己的服务器或本地机器上,不必依赖外部服务。 |
| 隐私保护 | 不需要登录注册,而且任务记录保存在本地,不上传到外部服务器。 |
| 前端处理 | 使用 ffmpeg wasm 技术,在前端进行多媒体处理,无需用户本地安装 ffmpeg。 |
| 多种文档风格支持 | 支持输出为小红书风格、公众号风格、知识笔记、思维导图、内容总结等形式。 |
| AI 对话 / 问答交互 | 转换完之后可以基于视频内容做二次问答。 |
| 字幕导出 | 可以把结果导出为字幕文件(例如 SRT、VTT 等格式)供视频直接使用。 |
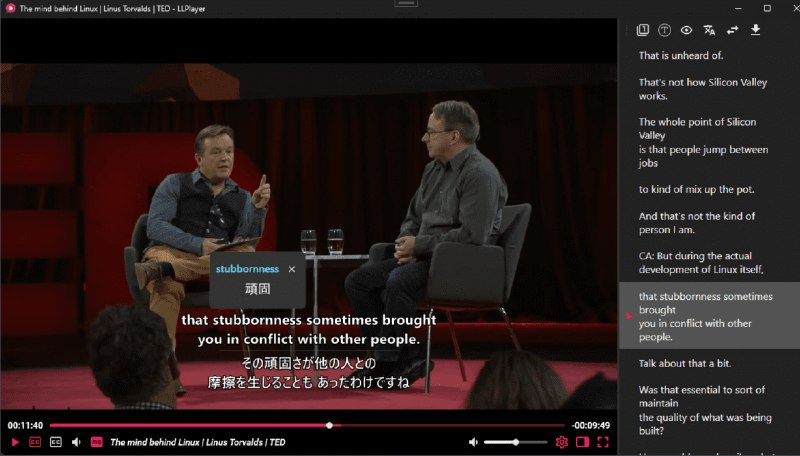
| 智能截图插图 | 根据字幕信息自动抓取“关键帧截图”插入文章里,以生成图文并茂的效果,而不依赖大型视觉模型。 |
| 可自定义 Prompt | 在前端可以对 prompt(提示器)进行定制,以适配不同风格或格式需求。 |
| 一键部署 / Docker 支持 | 提供 Docker 镜像、docker-compose 等,便于快速部署。 |
| 可设置访问密码 | 部署后可为前端设置访问密码,控制访客访问权限。 |
此外,它还在 “未来计划”里提到希望支持 fast-whisper 本地模型 来做音频识别,从而进一步减少对外部服务的依赖和成本。
三、工作流程 / 架构
在 README 里也有一个“处理流程 / 架构”图(architecture)来说明整体流程。 我这里给一个可能的流程逻辑(基于类似项目常见做法 + README 信息):
- 前端接收视频 / 音频上传 / 输入
- 音频 / 视频解码 / 预处理(如分段、格式转换)
- 前端用 ffmpeg wasm 处理一些转换任务
- 语音识别 / 转文字
- 把音频中的语音转换为文本(可能用 Whisper、OpenAI API 等)
- 文本理解 / 摘要 / 分析 / 重组
- 用大语言模型对识别出的文本做摘要、结构化、分段、风格化
- 可能还会做对话问答、补充、润色等
- 插图 / 智能截图
- 根据字幕或关键句位抓取视频关键帧插入文中
- 输出多种格式 / 风格
- 根据目标风格(小红书格式 / 公众号格式 / 笔记 / 思维导图 / 字幕等)对内容排版、重组
- 生成可下载文档、字幕文件、图文组合等
- 前端展示 / 导出 / 交互
- 用户在前端查看结果、做问答、调整风格、导出文件等
后端负责模型调用、文本处理、存储、权限控制等。
四、优点与局限 / 风险
优点
- 一站式:从音视频到多种文档与字幕,一把搞定。
- 本地部署 + 隐私保护:对于不希望将音视频内容上传云端的用户特别有吸引力。
- 风格多样:可输出适应多个平台的文档风格。
- 可交互:AI 二次问答功能增强实用性。
- 自动插图:不用额外图像模型也能生成图文效果。
- 开源 / 可定制:用户可以根据自己需要改 prompt 或扩展功能。
局限 / 风险
- 识别 / 语义错误:语音识别模型或文本理解模块可能出错,尤其在嘈杂音频中。
- 质量受限于模型:输出质量、风格化程度取决于所使用的 LLM 或大模型能力。
- 资源消耗 / 性能:在本地部署时,尤其是处理视频、模型推理可能对 CPU/GPU 有需求。
- 截图 / 关键帧判断误差:自动截图可能抓到不合适画面或者不够语义贴切的图像。
- 风格适配不足:不同风格(特别是平台规范)可能很难完全自动适配。
- 依赖外部模型 / 接口:如果语音识别 / 文本处理依赖云 API 的话,就会有成本与隐私考量。
- 前端兼容 / 浏览器性能限制:使用 wasm、前端处理有性能与环境兼容性挑战。
五、适用场景 & 不适用场景
适用场景
- 内容创作者 / 自媒体运营,希望把视频 / 直播 /音频内容转成文字 / 图文内容,以便在公众号、小红书等平台发表。
- 知识管理 / 笔记整理:把课程视频、访谈音频做成笔记、导图、摘要。
- 想在本地、受控环境下处理媒体内容,不愿意上传到第三方平台的用户。
- 需要快速把视频的字幕 / 文本 /摘要生成出来用于后续编辑加工。
不适用 / 可能表现差的场景
- 音频 / 视频质量很差:噪音大、口音重、重叠说话、多人同时讲话会影响识别与理解。
- 对输出风格 /格式要求极其严格 /定制化:自动化工具可能难以达到精致的排版 /风格标准。
- 对实时性要求极高(如即时直播转文字、实时翻译),这个项目可能延迟高。
- 环境资源极其有限(低配置电脑、没有 GPU)可能无法高效运行。
Github:https://github.com/hanshuaikang/AI-Media2Doc
油管:https://youtu.be/bV4hkLSdMHo