AI开源项目:AI Math Notes
AI Math Notes 是一个互动绘图应用程序,用户可以在画布上绘制数学方程。
绘制完方程后,应用程序会使用多模态大语言模型 (LLM) 计算结果,并在等号旁显示。
该应用程序使用 Python 编写,图形用户界面采用 Tkinter 库,图像处理使用 PIL 库。
AI Math Notes 是一个互动绘图应用程序,用户可以在画布上绘制数学方程。
绘制完方程后,应用程序会使用多模态大语言模型 (LLM) 计算结果,并在等号旁显示。
该应用程序使用 Python 编写,图形用户界面采用 Tkinter 库,图像处理使用 PIL 库。
苹果新出的翻译 API,不需要联网,完全使用本机大语言模型。
使用翻译框架提供应用内翻译。您可以使用内置 UI,让系统代表您向用户提供翻译。或者您可以使用该框架来定制翻译体验。
要提供内置系统翻译体验,请将视图修饰符锚定到包含要翻译的文本的 SwiftUI 视图。当您希望显示内置系统翻译 UI 时,将 isPresented 设置为 true。将要翻译的文本传递给 text 参数。
@niceaunties
作者介绍:“Niceaunties”的灵感来自于阿姨文化中荒唐又可爱的行为。 TED 演讲者。奖学金 http://daily.xyz 艺术家。
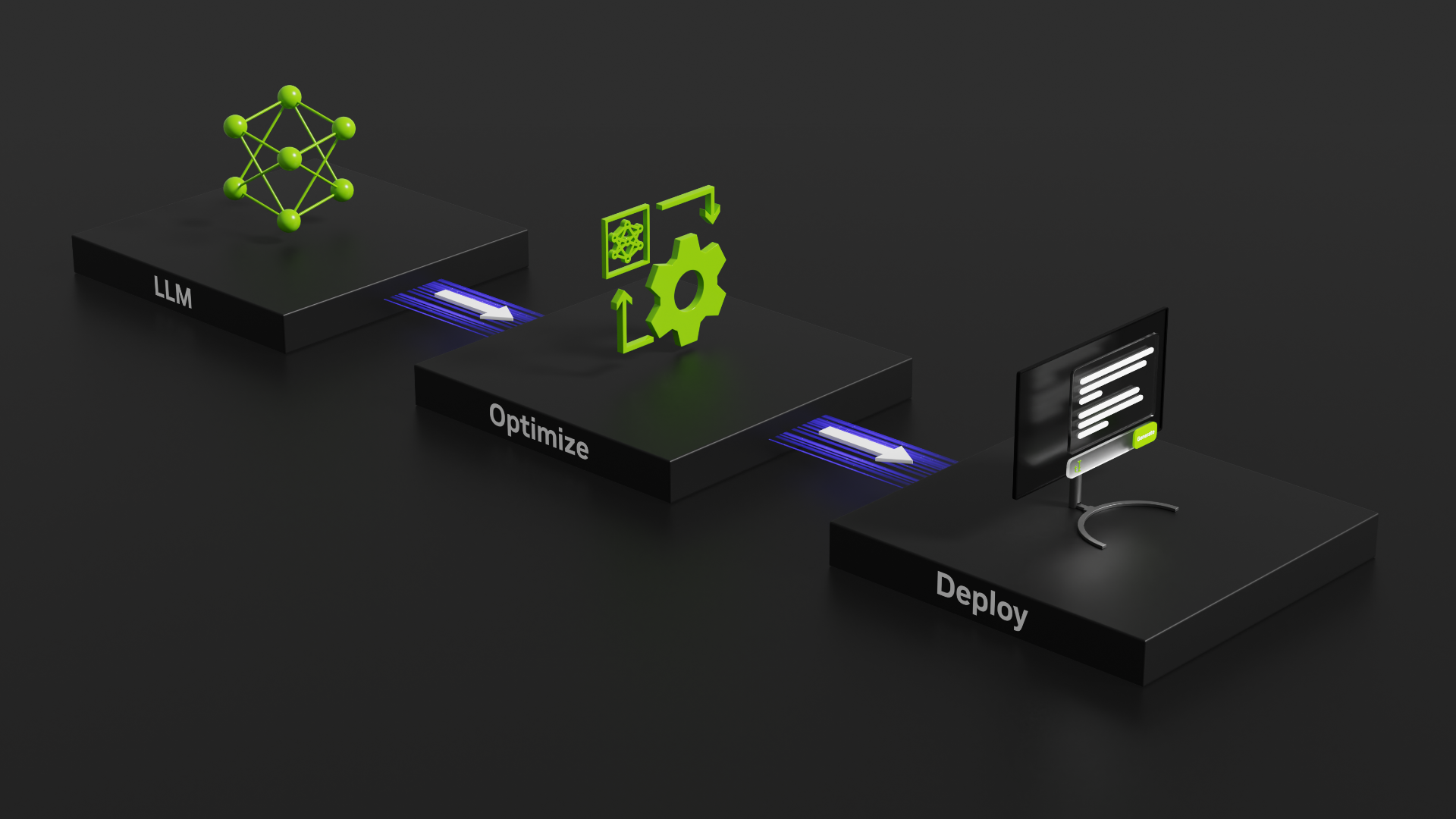
Nemotron-4 340B,一个优化用于NVIDIA NeMo和NVIDIA TensorRT-LLM的模型家族,包括最先进的指令模型和奖励模型,以及用于生成式AI训练的数据集。
NVIDIA今天宣布推出Nemotron-4 340B,这是一组开源模型,开发人员可以使用这些模型生成用于训练大语言模型(LLMs)的合成数据,以应用于医疗、金融、制造、零售等各个行业的商业应用。
NVIDIA ACE(Avatar Cloud Engine)是一套可協助開發人員使用生成式AI將數位化身變為現實的技術。透過 ACE,非玩家角色 (NPC) 可以轉變為動態的互動式角色,能夠發起對話,或提供遊戲知識來幫助玩家完成任務。
在 CES 2024 上,我們宣布推出ACE 產品級微服務 ,提供頂尖數位化身開發人員NVIDIA Audio2Face (A2F) 和 NVIDIA Riva 自動語音辨識 (ASR)。
Refuel AI 最近推出了两个新版本的大语言模型 RefuelLLM-2 和 RefuelLLM-2-small。
RefuelLLM-2 和 RefuelLLM-2-small 是专门为数据标注、清洗和丰富任务而设计的语言模型。
用途: RefuelLLM-2 主要用于自动化数据标注、数据清洗和数据丰富,这些任务是处理和分析大规模数据集时的基础工作,尤其是在需要将非结构化数据转换为结构化格式的场景中。
升级到V 2版本
与之前专注于英文文本版本相比
Glyph-ByT5-v2能够支持10种不同语言的准确拼写,显著提升了多语言文本渲染的准确性和广泛性。
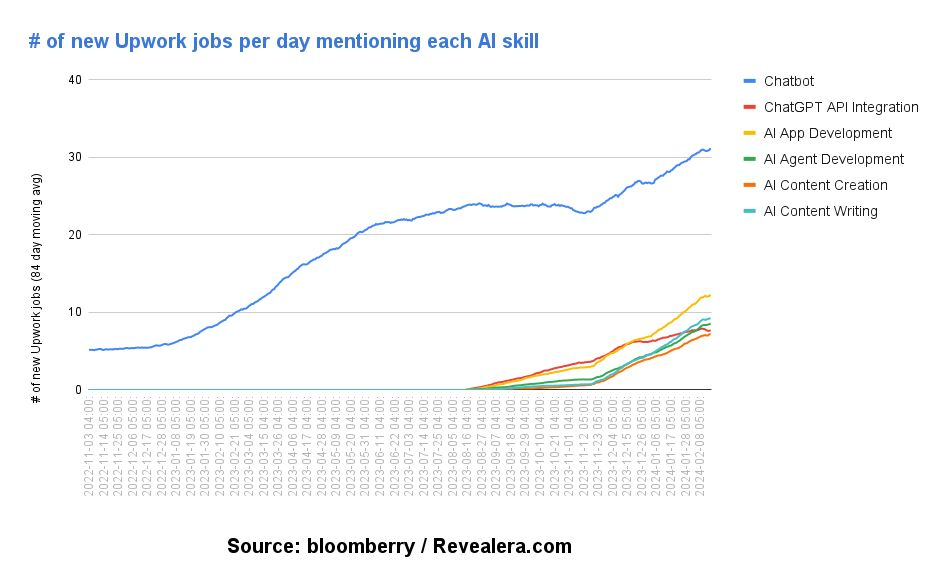
分析了 Upwork 上 2022/11 到2024/02的职位数据,看哪些工作数量下降,哪些工作数量上升,哪些工作时薪下降,哪些 AI 技能的工作发布量增加最多。选择2022/11月作为起始点,是因为 ChatGPT 发布时间是 2022/11/30,而这视为生成式 AI 的起点。
这是一家领先的实时分析数据库公司,提供世界级的数据索引和查询能力。
OpenAI称通过这次收购,OpenAI计划将Rockset的技术集成到其产品中,以增强其检索基础设施,使AI能够更好地利用和访问实时数据。
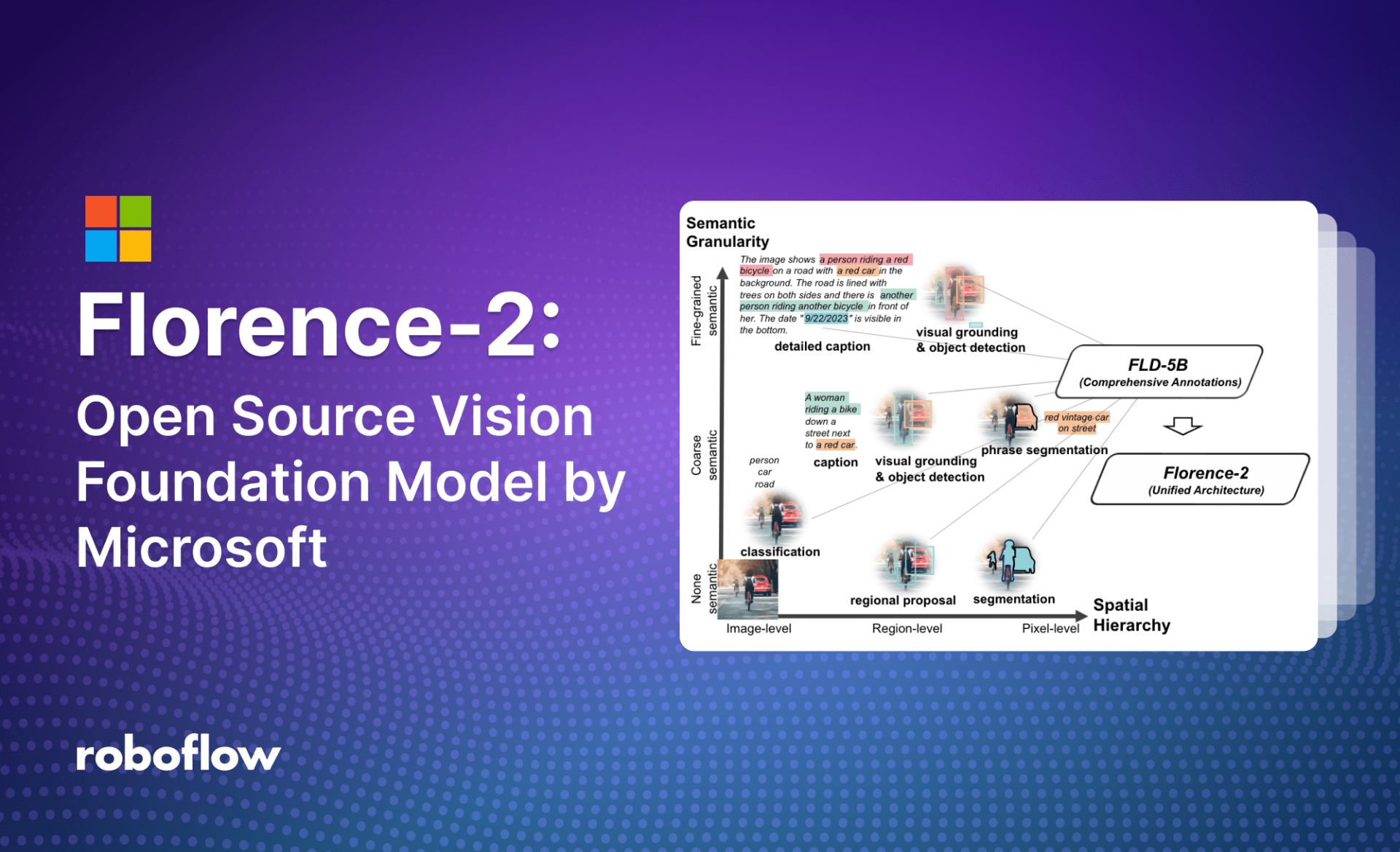
Florence-2 是 Microsoft 在 MIT 许可下开源的轻量级视觉语言模型。该模型在字幕、对象检测、接地和分割等任务中展示了强大的零样本和微调功能。
尽管尺寸很小,但它所取得的结果与大许多倍的模型(如 Kosmos-2)相当。该模型的优势不在于复杂的架构,而在于大规模的 FLD-5B 数据集,其中包含 1.26 亿张图像和 54 亿个综合视觉注释。
支持从图片生成提示词和指定位置的蒙版。
从图片生成提示词支持三个详细等级,内容会越来越多,蒙版生成类似 SAM 输入区域的单词就行。
提示词推理比 WD14 快非常多,也比较准确。
提供了 Colab 笔记,直接运行就可以,不需要摆弄麻烦的 Comfyui 流程和一堆模型了。
Diffutoon 能够以动漫风格渲染出细节丰富、高分辨率和长时间的视频。它还可以通过一个附加模块根据提示编辑内容。
可实现多人、多语言的实时对话翻译
用户可以通过蓝牙耳机连接应用,将手机放进口袋,与他人进行实时语言转换的对话,应用会自动翻译并播报对方的语言。
Gen-3 Alpha是Runway的反击之作。Gen-3 Alpha的一大特点是生成的视频具有高精细度,它可以理解并生成复杂的场景和运动画面,还能胜任多种电影艺术手法。
麻省理工学院的研究人员(麻省理工学院简介)创建了一个 聊天机器人 感动于 人工智能 (AI) 它模拟用户以前的“自我”并提供观察和建议。 目标是鼓励人们今天更多地思考他们明天想成为的人。
高中机器人团队开发的世界上最小、最便宜的网络交换机 — Murex Robotics 使硬件完全开源
高中生可以节省 90% 以上的价格,并减少专业解决方案的占用空间。