谷歌:个人健康大语言模型和智能体研究
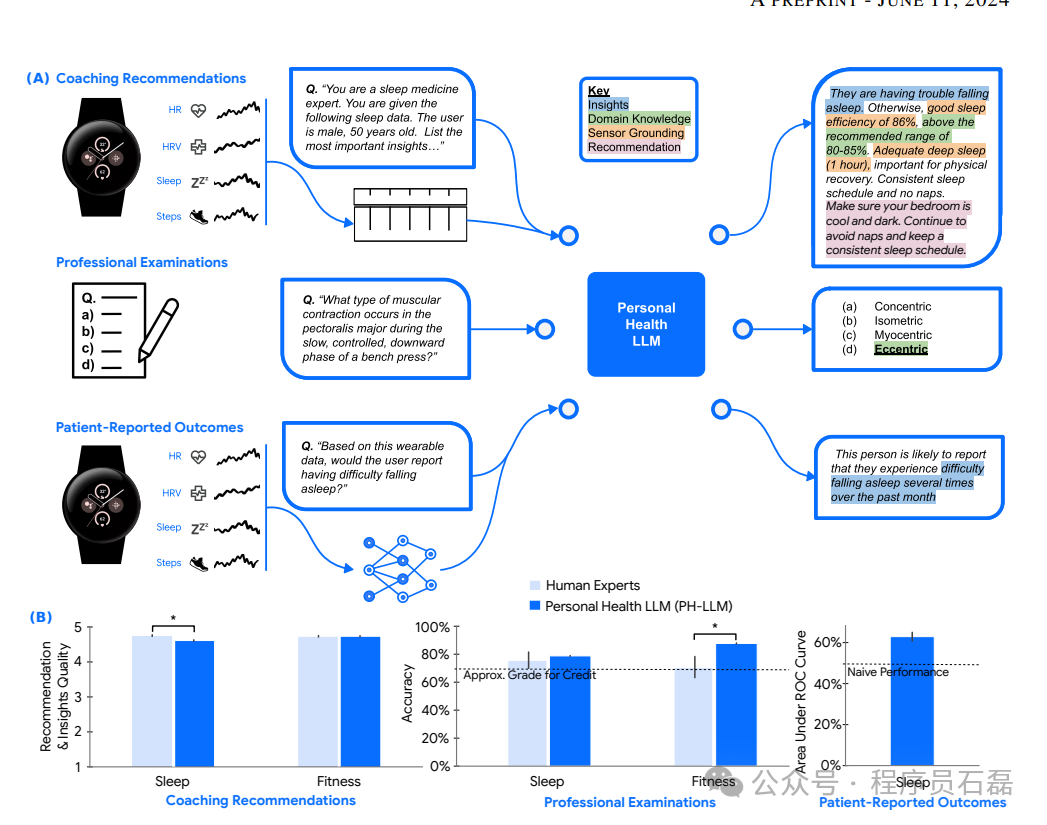
整合到临床任务中的移动和可穿戴设备为个人健康监测提供了丰富、连续和纵向的数据来源。本文提出一个新模型,个人健康大型语言模型(PH-LLM),一个经过微调的Gemini版本,用于对数字时间序列个人健康数据的文本理解和推理,用于睡眠和健身应用。
整合到临床任务中的移动和可穿戴设备为个人健康监测提供了丰富、连续和纵向的数据来源。本文提出一个新模型,个人健康大型语言模型(PH-LLM),一个经过微调的Gemini版本,用于对数字时间序列个人健康数据的文本理解和推理,用于睡眠和健身应用。
一款开源 AI 工具,有望通过将 GPU 使用率降低 20% 来彻底改变 LLM 训练
开发大型语言模型需要大量时间和 GPU 资源投资,这直接转化为高昂的成本。模型越大,这些挑战就越明显。
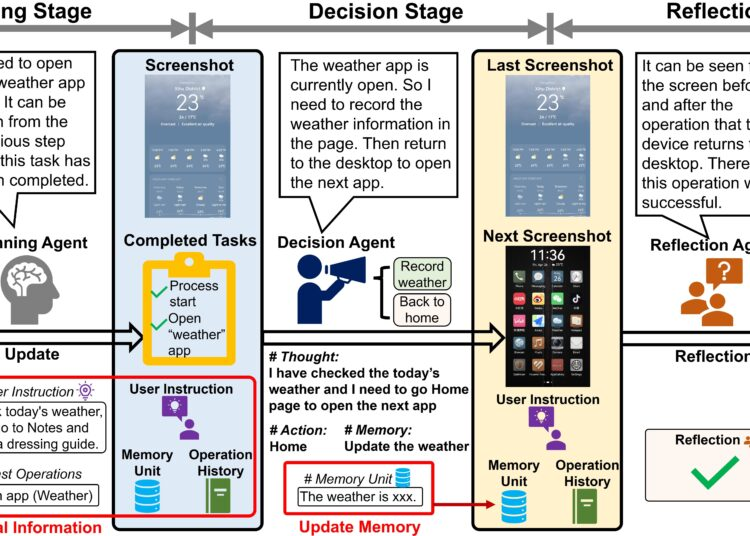
阿里和北交大的Mobile-Agent-v2 发布了Mobile-Agent-v2,一款通过多智能体协作实现有效导航的移动设备操作助手,它通过多代理协作实现了对移动设备的自动化操作和视觉感知功能,让ai可以像真人一样模拟点击、滑动、输入等操作来操控你的手机,从而执行各种任务。
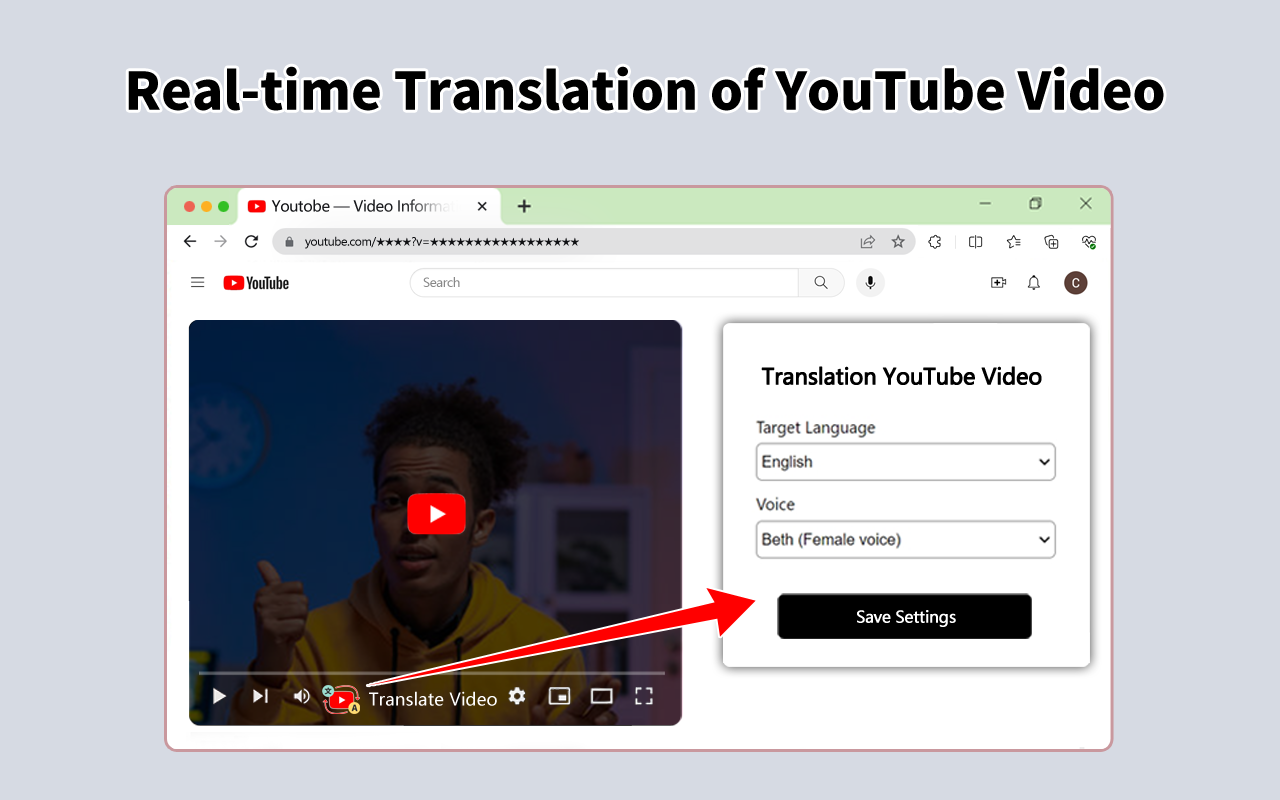
YouTube Dubbing插件,一键将英语视频转换为中文的声音进行播放,非常适合用来看国外教程类的视频,
目前支持Youtube 和Udemy 。PC,Android ,IOS 都支持。
ChatGPT Edu,这是 ChatGPT 的一个版本,专为大学打造,旨在负责任地将 AI 部署到学生、教师、研究人员和校园运营中。ChatGPT Edu 由 GPT-4o 提供支持,可以跨文本和视觉进行推理,并使用数据分析等高级工具。
直接在网络浏览器中实现实时语音识别长期以来一直是一个备受追捧的里程碑。 Hugging Face 工程师(昵称“Xenova”)开发的 Whisper WebGPU 是一项突破性技术,利用 OpenAI 的 Whisper 模型实现浏览器内实时语音识别。这一显着的发展是与人工智能驱动的网络应用程序交互的巨大转变。
2、肠镜(日本):1950年,日本医生宇治达郎成功发明软式胃镜的雏形:胃内照相机,成为现代胃镜的起源。
1、抗生素(英国):1929年,英国细菌学家弗莱明在培养皿中培养细菌时,发现从空气中偶然落在培养基上的青霉菌长出的菌落周围没有细菌生长,他认为是青霉菌产生了某种化学物质,分泌到培养基里抑制了细菌的生长。 这种化学物质便是最先发现的抗生素:青霉素。
Luma AI 刚刚推出了一款类似 Sora 的 AI 视频生成器,名为 Dream Machine。
但与 Sora 或 KLING 不同的是,它完全向公众开放。
用 MLX 把你的 iPhone、iPad 还有 Mac 在本地连接起来组成一个大号 GPU 来用!Nvidia 在数据中心做超级 GPU,Apple 说我 Edge Devices 多,用这种廉价方式串联 GPU 也行
ToonCrafter,这是一种超越传统基于通信的卡通视频插值的新方法,为生成插值铺平了道路。传统方法隐含地假设线性运动,并且没有像消遮挡这样的复杂现象,经常与卡通中常见的夸张的非线性和带有遮挡的大运动作斗争,导致插值结果难以置信甚至失败。
OpenAI 在命名下一代人工智能模型时可能会放弃数字,至少最近在巴黎举行的一次演讲中是这么建议的。
在 VivaTech 会议上演示 ChatGPT Voice 期间,OpenAI 开发人员体验主管 Romain Huet 展示了一张幻灯片,揭示了未来几年人工智能模型的潜在增长,但 GPT-5 并未出现在其中。
该框架包括一套功能齐全的高端软件分析工具,使用户能够在包括 Windows、macOS 和 Linux 在内的各种平台上分析编译的代码。功能包括反汇编、汇编、反编译、绘图和脚本编写,以及数百种其他功能。
Ghidra 支持多种处理器指令集和可执行格式,并且可以在用户交互和自动化模式下运行。用户还可以使用 Java 或 Python 开发自己的 Ghidra 扩展组件和/或脚本。
Studio,免费的本地 WordPress 开发环境,现在可用于 Windows。
最近推出了 Studio,这是适用于 MacOS 的免费开源本地 WordPress 开发环境,Windows 版本的 Studio 现已推出!
提醒一下,将 Studio 构建为本地构建 WordPress 网站的最快、最简单的方法。