PhysDreamer:由多所大学合作开发
PhysDreamer:由多所大学(包括麻省理工学院、斯坦福大学、哥伦比亚大学和康奈尔大学)合作开发。
真实的对象交互对于创建沉浸式虚拟体验至关重要,但合成真实的 3D 对象动态以响应新颖的交互仍然是一项重大挑战。与无条件或文本条件动力学生成不同,动作条件动力学需要感知对象的物理材料属性,并将 3D 运动预测建立在这些属性(例如对象刚度)的基础上。
PhysDreamer:由多所大学(包括麻省理工学院、斯坦福大学、哥伦比亚大学和康奈尔大学)合作开发。
真实的对象交互对于创建沉浸式虚拟体验至关重要,但合成真实的 3D 对象动态以响应新颖的交互仍然是一项重大挑战。与无条件或文本条件动力学生成不同,动作条件动力学需要感知对象的物理材料属性,并将 3D 运动预测建立在这些属性(例如对象刚度)的基础上。
ZeST(Zero-Shot Material Transfer)是一种基于零样本的方法
介绍 ZeST,这是一种零样本、免训练的方法,用于
(a) 图像到图像的材料传输。
(b) ZeST 可以轻松扩展以在单个图像中执行多种材质编辑
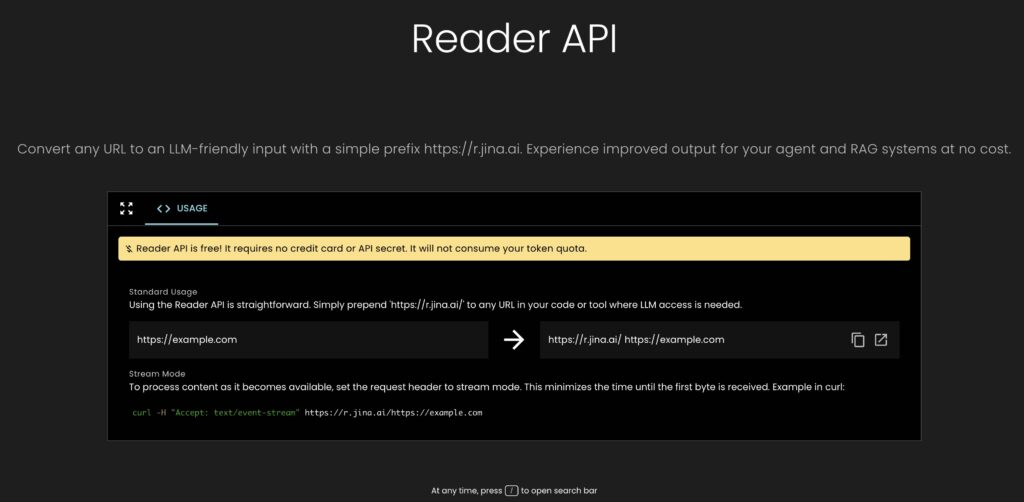
只需要输入任意URL,Jina-ai/Reader就能格式化和清理URL里的内容,确保LLM接收到的输入更加规范和易于处理。
操作非常简单,只需要在任意URL前+前缀 https: //r.jina.ai/ 即可实现转换,并且以流式方式处理数据
Android Studio提供了一站式解决方案,集成了代码编辑、编译、调试和测试的工具,减少了开发者在不同工具间切换的需要。
支持自动编写代码、语法高亮和代码重构
他可以将代码库转化为类似维基百科的文章,使得非专业人士也能理解复杂的代码结构。
而且当源代码发生变化或用户通过指令更新时,文档会自动刷新,确保实时性。
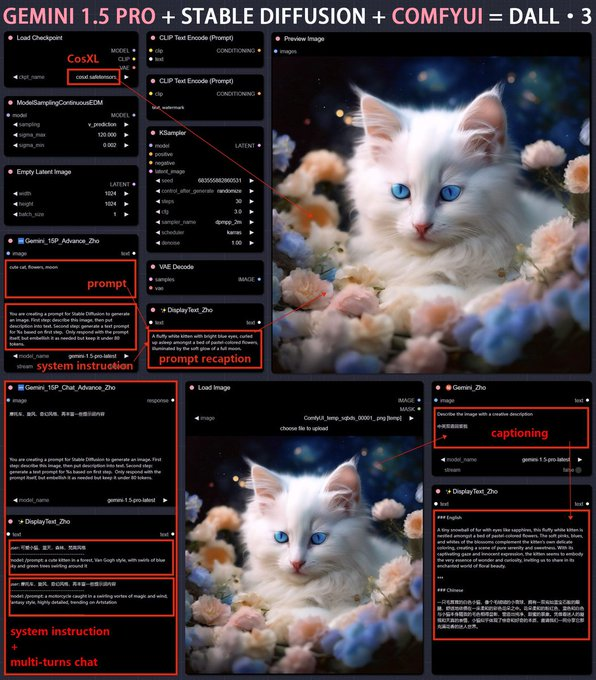
开源社区一直以来的梦想:DALLE3交互和提示词生成能力 + 无数SD模型出图能力,这不巧了嘛
百万上下文、多模态+多轮对话、打标/反推
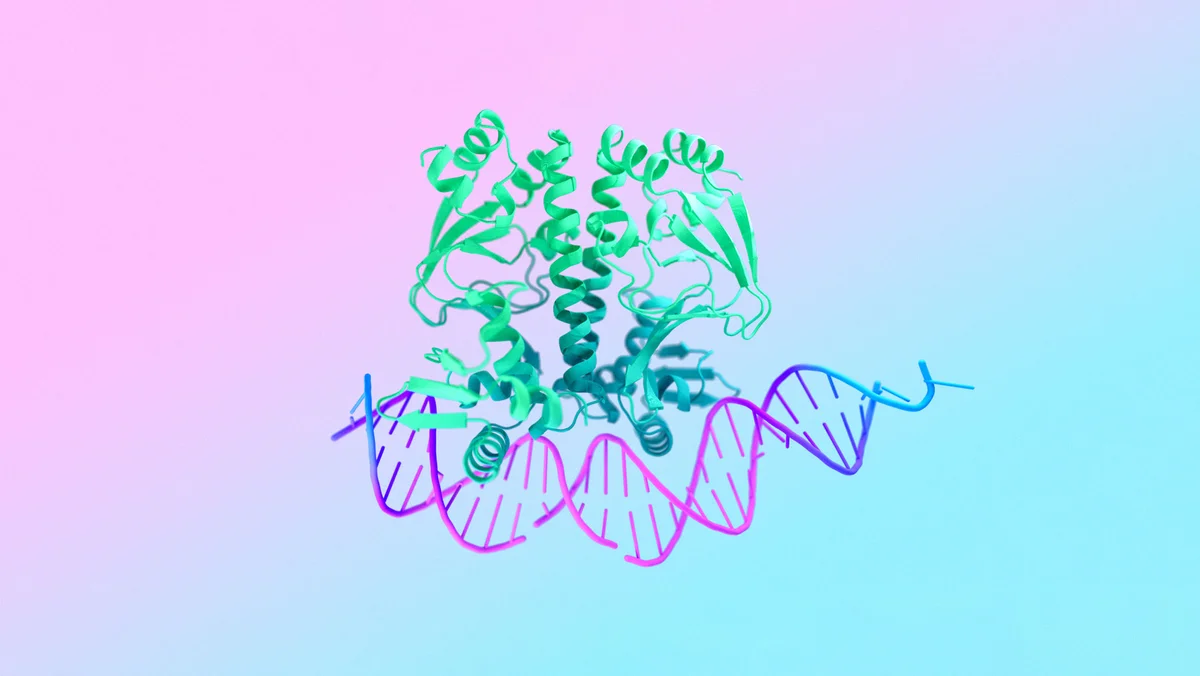
能够预测所有生命分子结构和相互作用 AI 模型
该模型能够生成蛋白质、DNA 和其他分子的 3D 结构,并揭示它们如何组合在一起。
该模型还能够模拟影响细胞健康的化学变化,并检测可能导致疾病的异常。
AlphaFold 3 将为全球科学研究人员和机构免费开放。它的高精度和新一代架构可支持药物发现和生物学的突破性进展。
这项研究的结果表明,个性化的抗生素治疗时间建议模型可以帮助医生更好地决策,避免治疗延迟或过早给药带来的潜在危害,同时降低患者的死亡率和医疗成本。
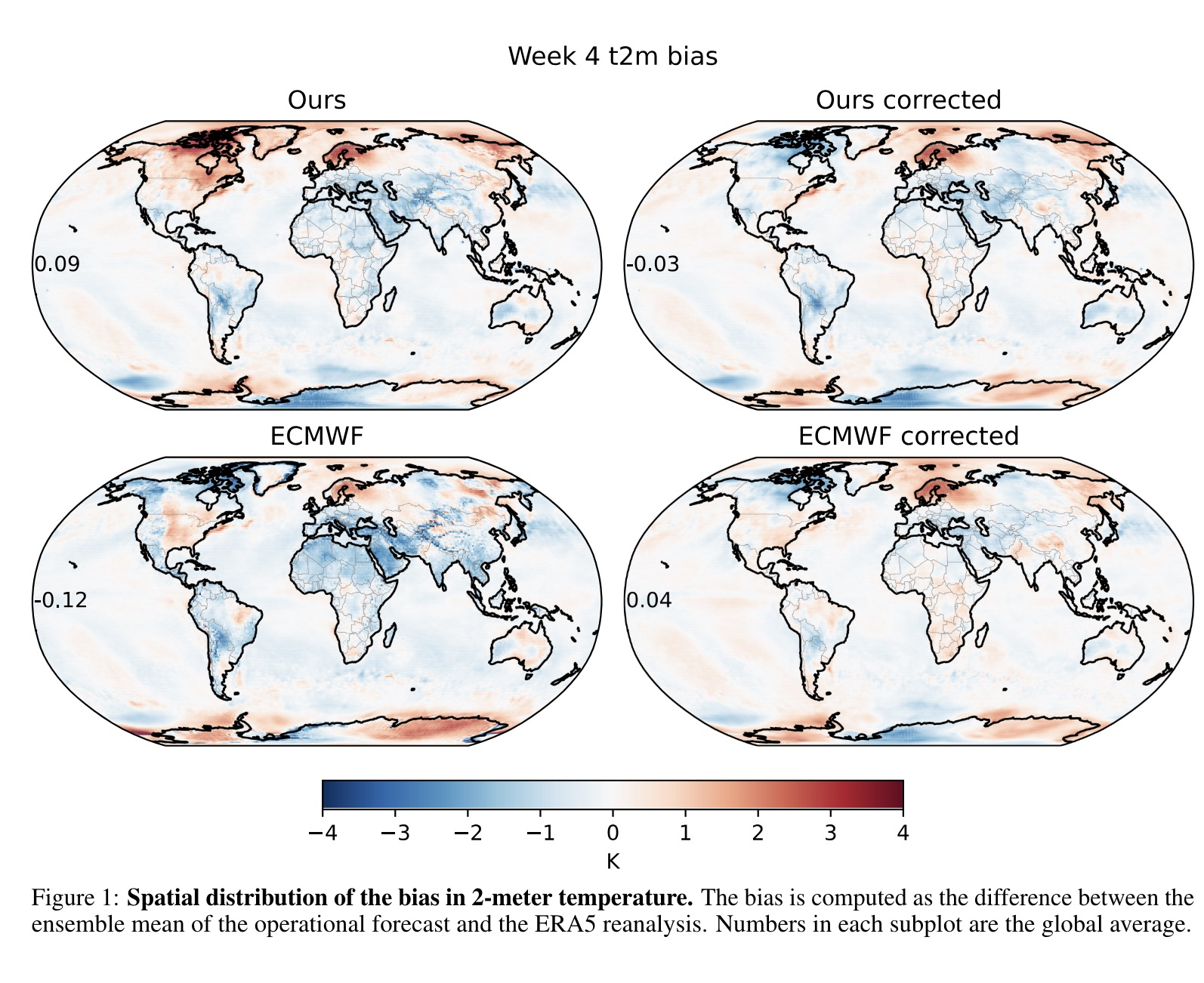
能准确预报未来 30 天天气情况
该模型基于微软 Start 团队近日的最新研究成果,结合了 5 种不同的人工智能模型和 3 种深度学习架构,并利用 了过去数十年的天气数据进行训练,能够准确预测 30 天内的天气预报。
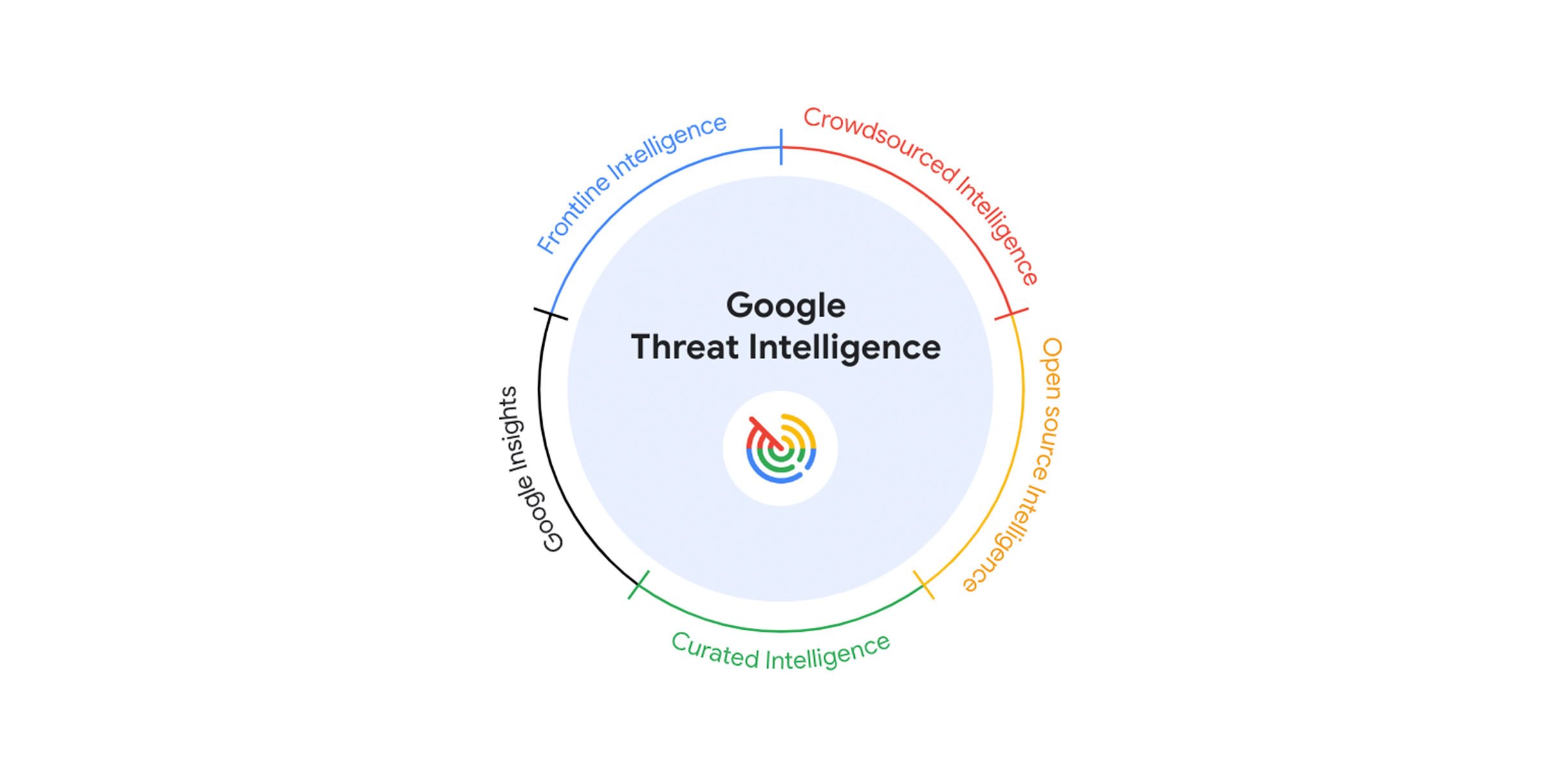
Google 威胁情报的用途示例:
识别和防御网络钓鱼攻击:
假设一家企业遭遇了钓鱼电子邮件攻击,员工可能收到包含恶意链接或附件的电子邮件。
Google Threat Intelligence可以利用其庞大的电子邮件监控网络,检测并阻止这些恶意邮件的传播。
OpenVoice,这是一种多功能的即时语音克隆方法,只需要参考说话者的一个简短的音频剪辑即可复制他们的声音并生成多种语言的语音。除了复制参考说话者的音色之外,OpenVoice 还可以对语音风格进行精细控制,包括情感、口音、节奏、停顿和语调。
CoreNet 是一个深度神经网络工具包,允许研究人员和工程师为各种任务训练标准和新颖的小型和大型模型,包括基础模型(例如 CLIP 和 LLM)、对象分类、对象检测,和语义分割。
Apple 使用 CoreNet 进行的研究工作
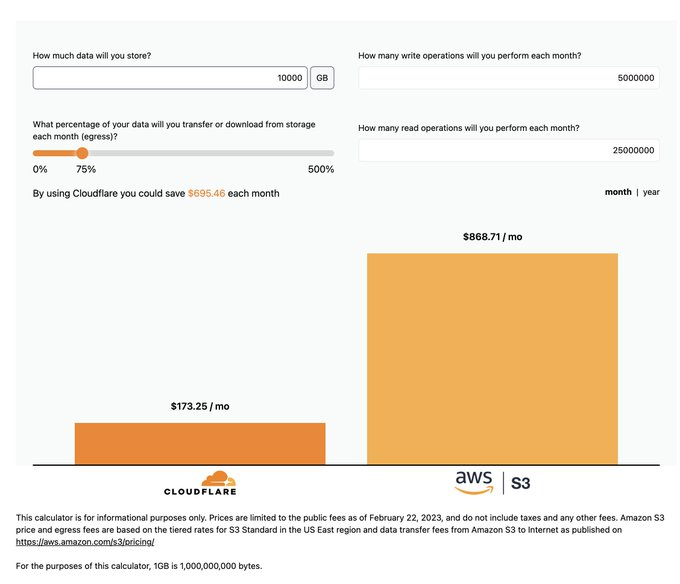
对象存储有时也称为 Blob 存储,可以存储任意的大型非结构化文件。我们常用的有 AWS 的 S3、阿里云的 OSS、腾讯云的 COS、华为云的 OBS,都是对象存储,他们都可以为我们提供延迟一致、持久性高和容量无限的服务,免去了我们本地文件系统的共享、备份等痛点。