Tarogo Cloud

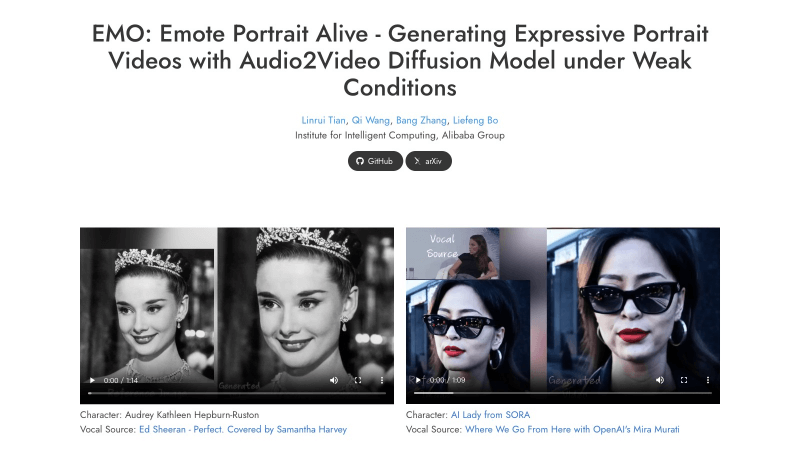
阿里巴巴的EMO: 情感肖像活灵活现
提出了 EMO,一个能够根据单张参考图片和声音(如说话或唱歌)生成充满表情的肖像视频的框架。这种方法不仅能够捕捉到丰富的面部表情和多样的头部姿势,还能根据声音的长度自由调整视频的持续时间。

ChatMusician: 能够理解和生成音乐的大语言模型
通过根据给定的文本提示、和弦序列、旋律线索、音乐主题或形式等条件。
ChatMusician能自动生成结构完整、风格多样的音乐作品。
包括单声部旋律、和声编配,乃至完整的乐曲结构设计。
同时它还能理解和分析音乐理论的各个方面。
MeloTTS:由MyShell AI开发的一个高质量的多语言文本到语音(TTS)库
支持英语、西班牙语、法语、中文、日语和韩语等多种语言。
速度非常快,支持中英混合的发音,能生成清晰、自然的语音输出。
即使在普通的在CPU上也能实现实时语音合成。

STORM:是一个创新的写作系统
挑战:维基百科样式的文章要求深入研究和计划,包括广泛收集参考资料和精心制作大纲。现有的生成维基百科文章的工作往往绕过了这一写作前阶段。
解决方案:STORM通过模拟人类写作过程中的预写、起草和修订阶段,特别是在预写阶段,通过有效的问题提问来自动化这一过程。

Chrome好的扩展介绍
1. ScribeHow / @ScribeHow
2. GoFullPage
3. Color Zilla
4. Fonts Ninja
5. Mail tracker
6. Loom


Move AI推出Move API
Move API提供的功能和灵活性为开发者创造了广泛的应用可能性,从增强现实(AR)应用、游戏开发到影视动画制作,都能够从中受益。通过提供易于集成的API和SDK,Move AI使得将高质量的3D运动数据集成到各种项目中变得更加简单和高效。


ChatGPT代码库进行了一些变动
与英语语言/翻译文件、图像生成样式图像、工作区设置.groups、ReadAloud / AudioPlayer等相关的一些内容发生了更改!
ChatGPT 数据分析 V2 显然使用了名为“gpt-4-ada-v2”(高级数据分析 V2)的新 GPT-4 模型。

StabilityAI推出图像提升增强工具:CreativeUpscaler
1、分辨率提升:将图像升级到4K分辨率,无论原始图像的大小如何。
2、细节创造:不仅放大图像,还能“幻想”出原始图像中不存在的新细节,通过结合输入图像与文本提示,创造出清晰、高质量的图像效果。
3、创造力调整:用户可以调整创造力水平,让AI在保持接近原始图像的基础上,创造出更多或更少的新细节。高创造力设置允许升级器创造出原本不存在的新细节。

YOLOv9:实时对象检测,能够快速准确地在图像或视频中识别和定位多个对象
之前的YOLO系列模型相比,YOLOv9在不牺牲性能的前提下实现模型的轻量化,同时保持更高的准确率和效率。
这使得它可以在各种设备和环境中运行,如移动设备、嵌入式系统和边缘计算设备。
YOLOv9通过改进模型架构和训练方法,提高了对象检测的准确性和效率

YOLO-World&EfficientSAM&Stable Diffusion 能干啥?
实时检测视频中的特定对象,然后分割对象,使用自然语言来对特定的对象进行替换、修改、风格化等!
是不是很熟悉?科幻片里面的场景就实现了!
这意味着你可以对任意图像和视频里面的内容进行实时的替换和修改,甚至换掉视频中的某个人物。
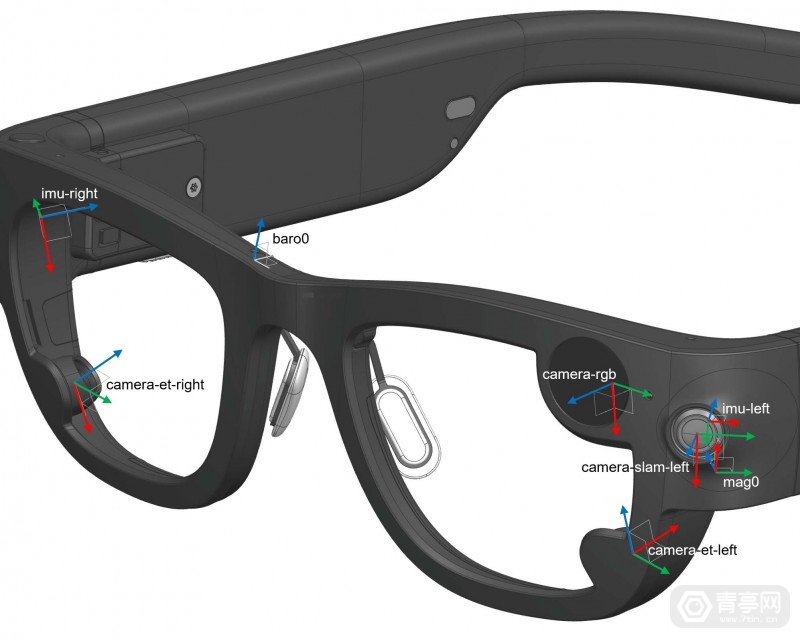
AEA 数据集:由Meta团队开发
一个基于 Project Aria AR眼镜记录的第一人称多模态开放数据集。
它包含了143个由多个佩戴者在五个地理位置记录的日常活动序列。
这些记录包含了通过Project Aria眼镜记录的多模态传感器数据,同时还提供了机器感知数据。
包括高频全球对齐的3D轨迹、场景点云、 每帧的3D眼动向量和时间对齐的语音转写。
提供了丰富的多模态感知信息和先进的机器感知输出,为 AI 和 AR 研究提供支持。