机器人技术即将迎来它的ChatGPT时刻
机器人初创公司@Figure_robot 发布了一段视频
他们家的Figure-01机器人现在可以自己煮咖啡了
这是一个使用了端到端的人工智能系统,仅通过观察人类制作咖啡的录像,10小时内学会了制作咖啡的技能。
机器人初创公司@Figure_robot 发布了一段视频
他们家的Figure-01机器人现在可以自己煮咖啡了
这是一个使用了端到端的人工智能系统,仅通过观察人类制作咖啡的录像,10小时内学会了制作咖啡的技能。
报道披露了 OpenAI 和微软与人形机器人公司 Figure 的融资谈判。
此轮融资对Figure的估值接近$2B。
想象一下,仅凭你的思维就能与亲人交流、上网浏览、甚至玩游戏的愉悦体验。
这一切,得益于在你大脑负责规划动作的区域植入一个既微小又不易察觉的装置。
将其与 Google Sheets 结合起来,实现数据处理的自动化。
向您展示如何使用 Bard 来管理没有公式的电子表格:
使用人工智能制作了一部戏剧、一部动作喜剧、一部纪录片和音乐视频。接下来:“Fragrance by Elle”,一个商业广告。
使用 @midjourney v6、@runwayml gen2、@Magnific_AI 高档制作。
宣称是世界上第三大能力超强的多模态模型,仅次于GPT4-V和Gemini Ultra。
它特别擅长理解用户界面,这意味着可以解释和操作各种软件和应用程序的界面。
能够帮助用户执行各种任务,如自动化流程、响应查询、提供信息等。
DisplayLink 发布可以扩展 Windows 桌面到 iPad 的应用,它可以将 iPad 的大屏幕通过 Wi-Fi 传送信号变成 Windows 7 的第二个显示屏
Google Research团队开发的基于空间时间的文本到视频扩散模型。
它采用了创新的空间时间U-Net架构,能够一次性生成整个视频的时间长度,不同于其他模型那样逐帧合成视频。
确保了生成视频的连贯性和逼真度。
使用的是 @JigSpace 公司的3D to CAD技术!
这个是早前发布会时候的演示,可以模拟真实世界物理规律
MedSAM是一种医学影像分割工具,它能够自动识别和描绘医学影像中的重要区域,比如肿瘤或其他组织的病变。
通过学习大量医学影像和对应的掩模(即正确的分割结果),它能够处理各种不同的医学影像和复杂情况。
它可以帮助医生更快、更准确地诊断疾病。
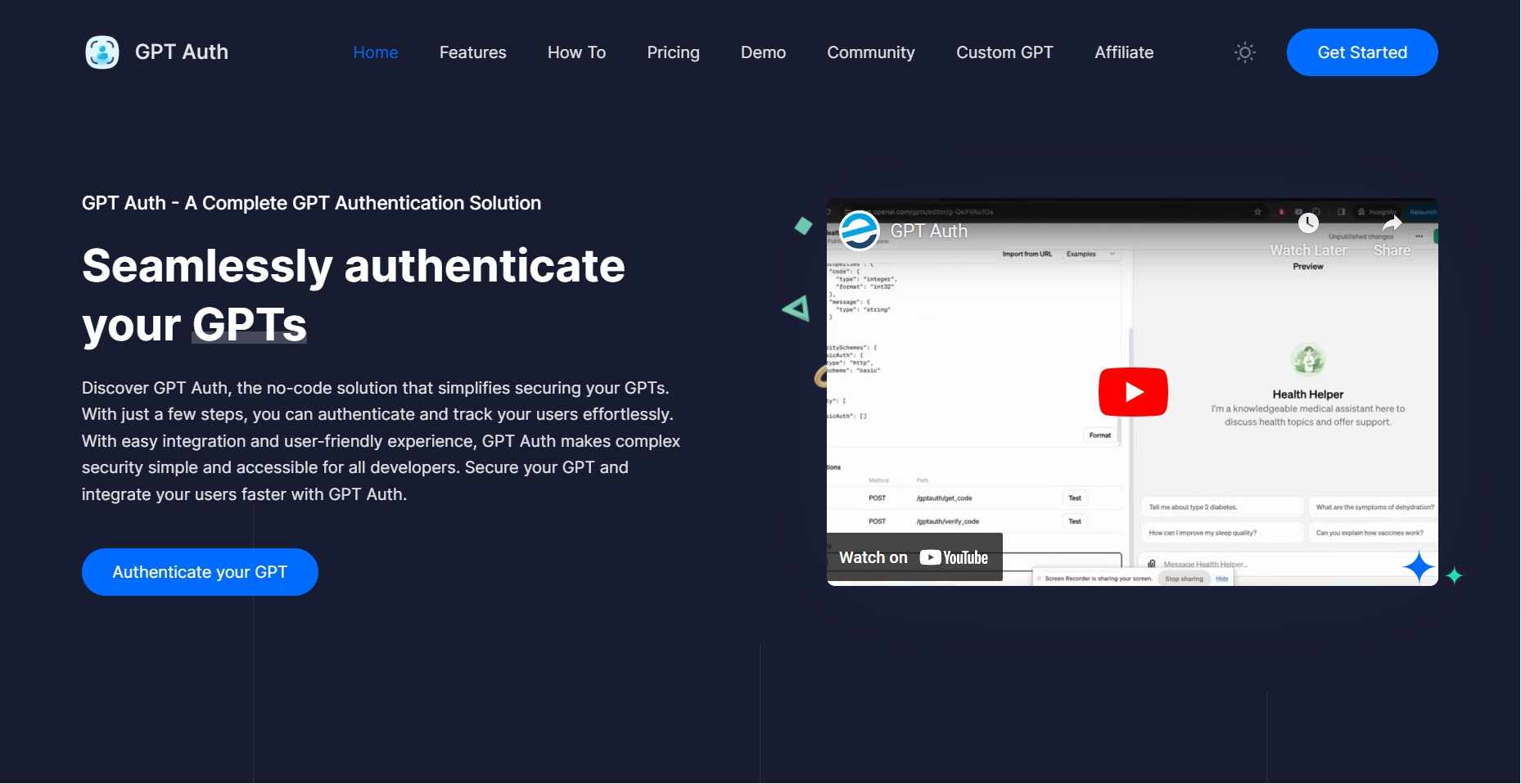
确保只有授权用户才能访问你的GPT应用
还可以针对GPTs应用进行收费,包括订阅、按次使用和一次性购买。
这样你就能对自己的GPTs用户进行收费了!