人工智能聊天机器人在背痛建议的准确性方面可与医生媲美
人工智能聊天机器人(例如 ChatGPT)可能几乎与向医生寻求有关腰痛的建议一样有效。
该研究由一个国际团队进行,揭示了人工智能在解决世界上导致残疾的主要原因之一方面的潜力。
研究合著者、悉尼科技大学 (UTS) 物理治疗主任 Bruno Tirotti Saragiotto 副教授表示
人工智能聊天机器人(例如 ChatGPT)可能几乎与向医生寻求有关腰痛的建议一样有效。
该研究由一个国际团队进行,揭示了人工智能在解决世界上导致残疾的主要原因之一方面的潜力。
研究合著者、悉尼科技大学 (UTS) 物理治疗主任 Bruno Tirotti Saragiotto 副教授表示

日本科学家利用人工智能在秘鲁纳斯卡沙漠发现了 303 处新蚀刻,使大约 2,000 年前前印加文明已知的地质符号数量增加了一倍。
传说中的纳斯卡线条是沙漠地面上一系列巨大的切口,描绘了动物、植物、想象中的生物和几何图形,自从大约一个世纪前首次被发现以来,它们就一直让科学家们着迷
食道每天大约 600 次将口腔中的食物输送到胃中。这通常是单向路线,但有时胃酸会逸出胃并返回。这会损害食道内壁的细胞,促使它们因遗传错误而重新生长。
在美国,每年约有 22,370 次此类错误最终导致癌症。
如果在食道癌深入或扩散到其他器官之前发现并治疗,它是可以治愈的。但这种情况很少发生。

最伟大的发现不仅仅来自观察,而且来自思考。爱因斯坦通过思想实验发展了相对论,伽利略通过心理模拟得出了关于引力的见解。
9 月 18 日发表在《认知科学趋势》杂志上的一篇评论表明,这种思维过程并非人类独有。人工智能也能够通过“思考学习”进行自我修正并得出新的结论。
最近有一些人工智能的演示

想象一下,只需告诉您的车辆“我很着急”,它就会自动带您走最有效的路线到达您需要去的地方。
普渡大学的工程师发现,自动驾驶汽车 (AV) 可以在 ChatGPT 或其他聊天机器人的帮助下做到这一点,这些聊天机器人是通过称为大语言模型的人工智能算法实现的。
该研究报告发表在预印本服务器arXiv上

新的研究揭示了一种有前景的方法,即利用机器学习在大流行期间或任何治疗药物短缺的情况下更有效地分配医疗治疗。
发表在《JAMA 健康论坛》上的研究结果发现,使用机器学习来帮助分发药物并使用 COVID-19 大流行来测试模型时,预期住院治疗会显着减少。事实证明,与实际和观察到的护理相比,该模型可相对减少约 27%
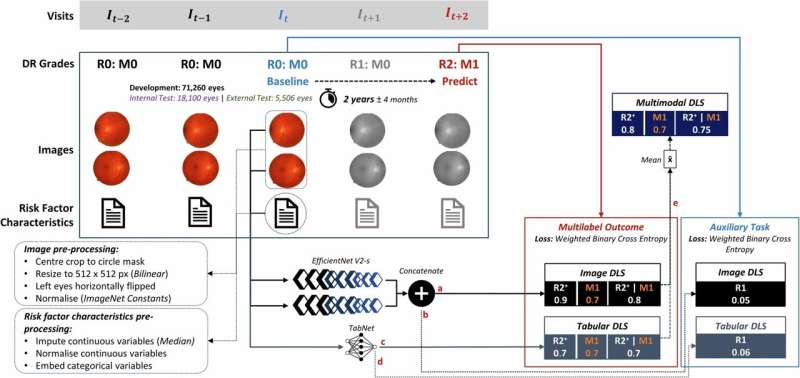
伦敦国王学院的研究人员使用来自超过 100,000 名糖尿病患者的匿名 NHS 眼部数据建立了一个 AI 模型,该模型可以提前三年准确预测谁有可能患上威胁视力的糖尿病视网膜病变 (DR)。
该研究发表在《通讯医学》杂志上。
DR 是一种眼部疾病,约三分之一的糖尿病患者受到影响,也是工作年龄成年人视力丧失的主要原因
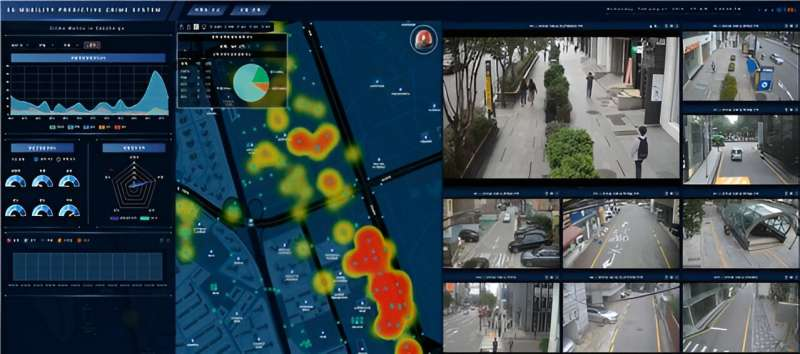
研究团队成功开发了一种技术,可以利用实时闭路电视和人工智能技术检测和预测犯罪活动的迹象。借助这项新技术,闭路电视现在正在超越其最初的监视作用,发挥其作为“预防”犯罪的有效方式的潜力。
电子电信研究所(ETRI)最近宣布,他们已经完成了“Dejaview”的开发,这是一项利用闭路电视录像、犯罪相关统计数据、定位技术等来检测潜在犯罪信号并预测的创新技术

技术进步使得各种电子设备的开发成为可能,这些电子设备旨在提高人们的生活质量并帮助他们完成日常活动。大多数现有设备都是通过触摸屏、键盘、鼠标垫和其他手动界面进行操作。
新加坡国立大学的研究人员开发了一种智能护齿套,可以让人们用嘴而不是手指来操作设备。 《自然电子》杂志上的一篇论文介绍了这种新设备

配音演员从中看到了希望和危险
在长达六十多年的演艺生涯中,詹姆斯·厄尔·琼斯的声音成为他作为表演者作品中不可磨灭的一部分。
琼斯于周一去世,享年 93 岁。在银幕上,琼斯在《梦想之地》中再现了一位隐居的作家,在《梦想之地》中重新回到聚光灯下,在《来到美国》中再现了一位虚构土地上傲慢的国王。

赫特福德郡大学的研究人员开发了一种新算法,可以让机器人更直观地发挥作用,即利用环境作为指导做出决策
其原理是,通过算法,机器人代理创建自己的目标
该算法第一次将不同的目标设定方法统一在一个与物理学直接相关的概念下,而且它还使计算透明,以便其他人可以研究和采用它。
该算法的原理与著名的混沌理论有关