
算法让机器人离“凭直觉行动”又近了一步
赫特福德郡大学的研究人员开发了一种新算法,可以让机器人更直观地发挥作用,即利用环境作为指导做出决策
其原理是,通过算法,机器人代理创建自己的目标
该算法第一次将不同的目标设定方法统一在一个与物理学直接相关的概念下,而且它还使计算透明,以便其他人可以研究和采用它。
该算法的原理与著名的混沌理论有关
赫特福德郡大学的研究人员开发了一种新算法,可以让机器人更直观地发挥作用,即利用环境作为指导做出决策
其原理是,通过算法,机器人代理创建自己的目标
该算法第一次将不同的目标设定方法统一在一个与物理学直接相关的概念下,而且它还使计算透明,以便其他人可以研究和采用它。
该算法的原理与著名的混沌理论有关

一台长形机器人进入日本福岛核电站受损的反应堆,开始执行为期两周的高风险任务,首次从底部回收少量熔化的燃料碎片。
机器人进入 2 号机组反应堆是接下来发生的事情的关键第一步——这是一个令人畏惧的、长达数十年的过程,目的是让核电站退役并处理因大规模爆炸而损坏的三个反应堆内的大量高放射性熔化燃料。
今天提出的研究表明,一种名为 DeepGEM 的人工智能工具可能会推动基因组测试的进步,为组织病理学切片预测基因突变提供准确、经济高效且及时的方法。
该研究由来自中国呼吸疾病国家重点实验室、广州医科大学第一附属医院国家呼吸疾病临床研究中心的梁文华教授今天在IASLC 2024 世界肺癌大会上发表
内盖夫本古里安大学的研究人员开发了一种计算方法,通过将医学图像划分为具有对人工智能重要的不同临床解释的组件,使他们能够对人工智能的“决策”进行“逆向工程”。了解人工智能模型的决策机制是破译生物过程和医疗决策的关键。
该研究结果发表在《自然通讯》杂志上。
深度学习使用人工神经网络,是一种基于人工智能的计算方法
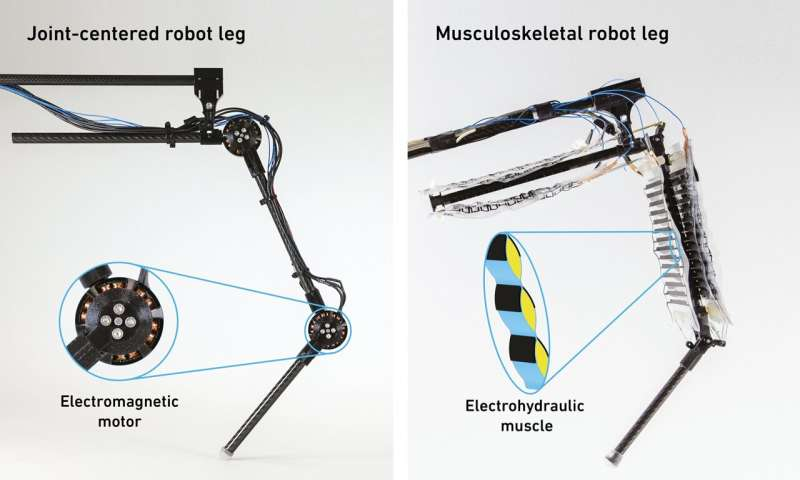
发明家和研究人员开发机器人已有近 70 年的历史。迄今为止,他们制造的所有机器——无论是为工厂还是其他地方——都有一个共同点:它们都由电机提供动力,这是一项已有 200 年历史的技术。即使是行走机器人的手臂和腿也由电机驱动,而不是像人类和动物那样由肌肉驱动。这在一定程度上说明了为什么它们缺乏生物的移动性和适应性。
研究人员创造了纳米级机器人,可用于治疗动脉瘤引起的大脑出血。这一进展可以实现对脑动脉瘤的精确、相对低风险的治疗,脑动脉瘤每年导致全球约 50 万人死亡。这种疾病——脑动脉上充满血液的凸起,可能破裂并导致致命的出血——也可能导致中风和残疾。
研究人员表示,这项研究指出,未来可以远程控制微型机器人

Audible 即将推出新功能,邀请在美国的精选朗读员创建其声音的 AI 生成复制品,以丰富其有声书产品。此举旨在满足日益增长的音频内容需求,因为许多书籍仍未以这种格式提供。参与者将提交语音样本,Audible 将将其转化为高质量的复制品,作者可以在有声书创作交易所 (ACX) 上选择这些复制品用于他们的有声书。

Chai Discovery 获得 3000 万美元融资,用 AI 革新药物发现
Chai Discovery 是一家专注于人工智能的生物科技初创公司,成立仅六个月便从 Thrive Capital 和 OpenAI 筹集了近 3000 万美元的资金。这笔投资使公司的估值达到 1.5 亿美元
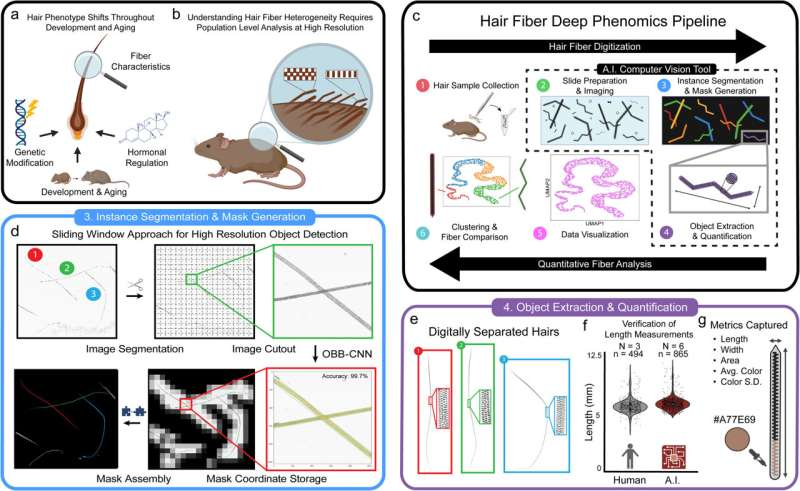
一种使用人工智能的新应用可能会彻底改变科学家研究头发的方式,并可能导致仅基于头发的健康诊断的发展。
人工智能模型加速并简化了头发量化过程,允许显微镜扫描载玻片并一次收集数百根头发的图像。在几秒钟内,它可以捕获大量高分辨率数据,然后使用深度学习算法进行处理,收集每根头发的颜色、形状、宽度和长度。
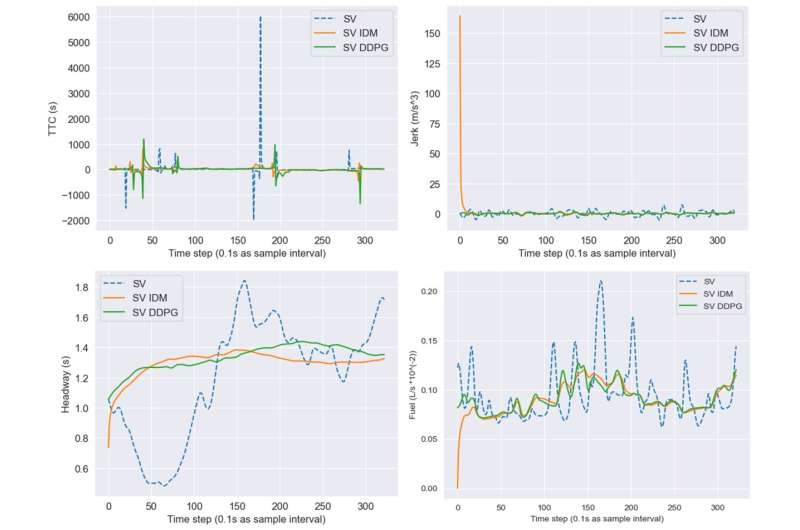
交通部门仍然是地球上空气污染和气候变化的主要来源之一,约占石油消耗的59%和CO 2排放的22%。因此,确定限制车辆燃料消耗的有效策略有助于减少污染,同时解决全球能源短缺问题。
香港科技大学的研究人员最近开始使用基于强化学习的计算模型来应对这一挑战。
该模型在预印本服务器arXiv上发布的一篇论文中概述
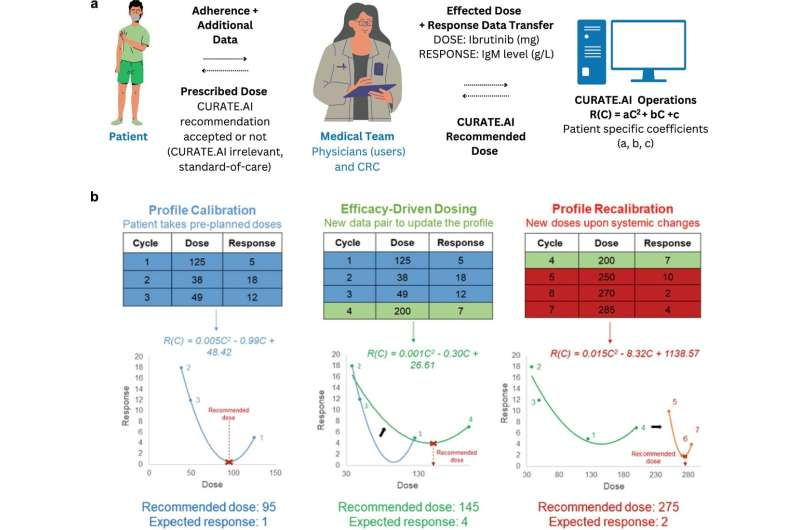
罕见疾病影响的人数不到 2,000 人中的 1 人。然而,由于已经确定了 7,000 多种不同类型,它们的全球影响是巨大的。在亚太地区,约有 2.58 亿人患有罕见病,这一数字是全球最高的,仅东南亚就有超过 4500 万人。这一庞大的数字凸显了治疗方面的重大挑战,因为患者群体的多样性导致了巨大的医疗保健差异
