
类似 ChatGPT 的模型可以诊断癌症
类似 ChatGPT 的模型可以诊断癌症
指导治疗选择、预测多种癌症类型的生存率
哈佛医学院的科学家设计了一种类似于 ChatGPT 的多功能 AI 模型,能够执行多种癌症的一系列诊断任务。
研究人员表示,9 月 4 日在《自然》杂志上描述的新人工智能系统比当前许多癌症诊断人工智能方法更进一步。
类似 ChatGPT 的模型可以诊断癌症
指导治疗选择、预测多种癌症类型的生存率
哈佛医学院的科学家设计了一种类似于 ChatGPT 的多功能 AI 模型,能够执行多种癌症的一系列诊断任务。
研究人员表示,9 月 4 日在《自然》杂志上描述的新人工智能系统比当前许多癌症诊断人工智能方法更进一步。

就像心脏起搏器一样,植入神经刺激装置可发送电脉冲以激发全身神经的活动。这些电刺激装置已用于治疗和控制许多疾病,包括心脏病、癫痫、抑郁症和类风湿性关节炎。
但有许多变量会影响神经对刺激的反应,使得神经刺激疗法的开发和使用变得困难和复杂。
杜克大学的神经工程师设计了一种计算机模型,可以更轻松地模拟神经对电刺激的反应。

评估 ChatGPT-4 Vision 性能的研究人员发现,该模型在基于文本的放射学考试问题上表现良好,但很难准确回答与图像相关的问题。该研究结果发表在《放射学》杂志上。
Chat GPT-4 Vision 是第一个可以解释文本和图像的大型语言模型版本。
新的研究发现,使用类人服务机器人的英国酒店和餐馆可以通过提供舒适的环境条件(包括灯光、气味和声音)并在机器人的表面添加英国国旗图案等当地提示,让单独的客人在与这些机器人互动时感觉更舒服。身体。
英国酒店业的服务机器人通常被拟人化,旨在执行通常由人类员工处理的任务。其中包括餐厅中的送餐机器人

芬太尼疫苗预计将于明年年中的某个时候进入临床试验,有望成为解决致命危机的突破性解决方案。
该疫苗在动物研究中取得了成功,旨在阻止高度成瘾的阿片类药物进入大脑并导致用药过量。生物制药初创公司 Ovax 于 2023 年 11 月获得了生产和测试该疫苗的许可证,并于 6 月份为此筹集了超过 1000 万美元。

统计数据显示,挪威 8 月份电动汽车销量占据了 94% 的市场份额,创下了新的世界纪录,而欧洲其他地区的销量却停滞不前。
挪威道路联合会 (OFV) 表示,在特斯拉 Model Y(占销量的 18.8%)以及现代汽车的 Kona 和日产的 Leaf 的推动下,电动汽车占新车注册量的 94.3%。

但人们担心这对人类劳动力意味着什么?
肯尼亚内罗毕的一家机器人咖啡馆里,机器人服务员为顾客提供服
在肯尼亚首都一家繁忙的餐馆里,当年轻人用智能手机拍摄机器人在内置托盘上端着一盘新鲜烹制的饭菜,将其送到食客手中时,孩子们咯咯地笑起来。

食品自动化与其他任何事情的自动化不同。食物是生命的基础——滋养身体和灵魂——因此食物的获取、准备和消费方式可以从根本上改变社会。
自动化厨房并不是《杰森一家》或《星际迷航》中的科幻愿景。该技术是真实的、全球性的。目前,机器人被用来翻转汉堡、炸鸡、制作披萨、制作寿司、准备沙拉、提供拉面、烤面包、调制鸡尾酒等等。
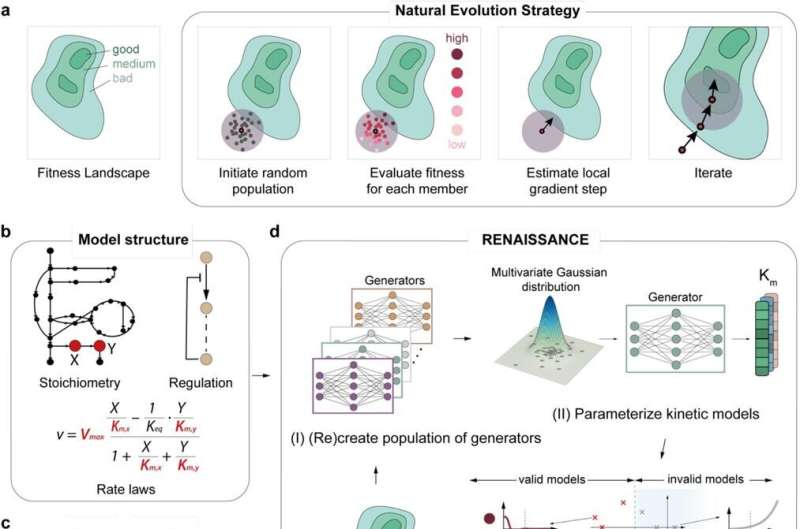
细胞如何处理营养物质并产生能量(统称为新陈代谢)对于生物学至关重要。现代生物学生成有关各种细胞活动的大型数据集,但整合和分析有关细胞过程的大量数据以确定代谢状态是一项复杂的任务。
动力学模型提供了一种通过提供细胞代谢的数学表示来解码这种复杂性的方法。它们充当详细的地图

來自南加州美國宇航局噴氣推進實驗室的工程師們擠在一起,凝視著厚厚的海冰層中的一個狹窄的洞。在他們下方,一個圓柱形機器人在寒冷的海洋中收集測試科學數據,透過繩索將其連接到將其放入鑽孔的三腳架上。
這次測試讓工程師有機會在北極操作他們的原型機器人。

研究推動了機器人領域的進步,而研究又嚴重依賴有效的平台來測試機器人控制和導航的演算法。儘管在過去幾十年中已經開發了許多機器人平台,但其中大多數都存在限制其在研究環境中使用的缺點。
加州大學柏克萊分校的研究人員最近開發了Berkeley Humanoid ,這是一個新的機器人平台,可用於訓練和測試人形機器人控制演算法。這種新型人形機器人是在預印本伺服器arXiv上發布的一篇論文中介紹的,它解決並克服了先前引入的機器人研究平台的一些限制。
