自动翻译油管语言的插件
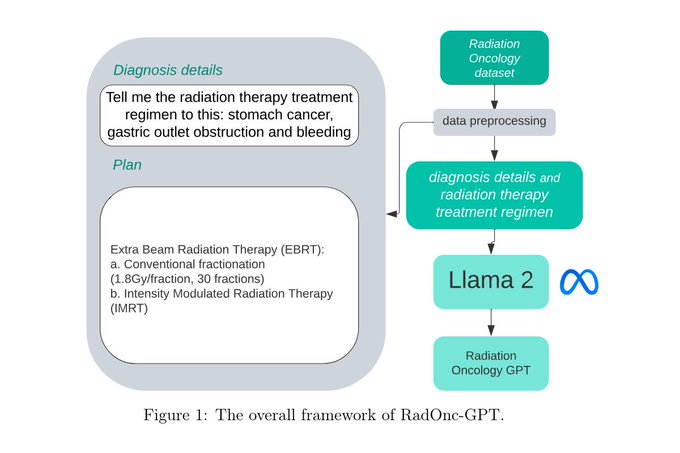
YouTube Dubbing插件,一键将英语视频转换为中文的声音进行播放,非常适合用来看国外教程类的视频,
目前支持Youtube 和Udemy 。PC,Android ,IOS 都支持。
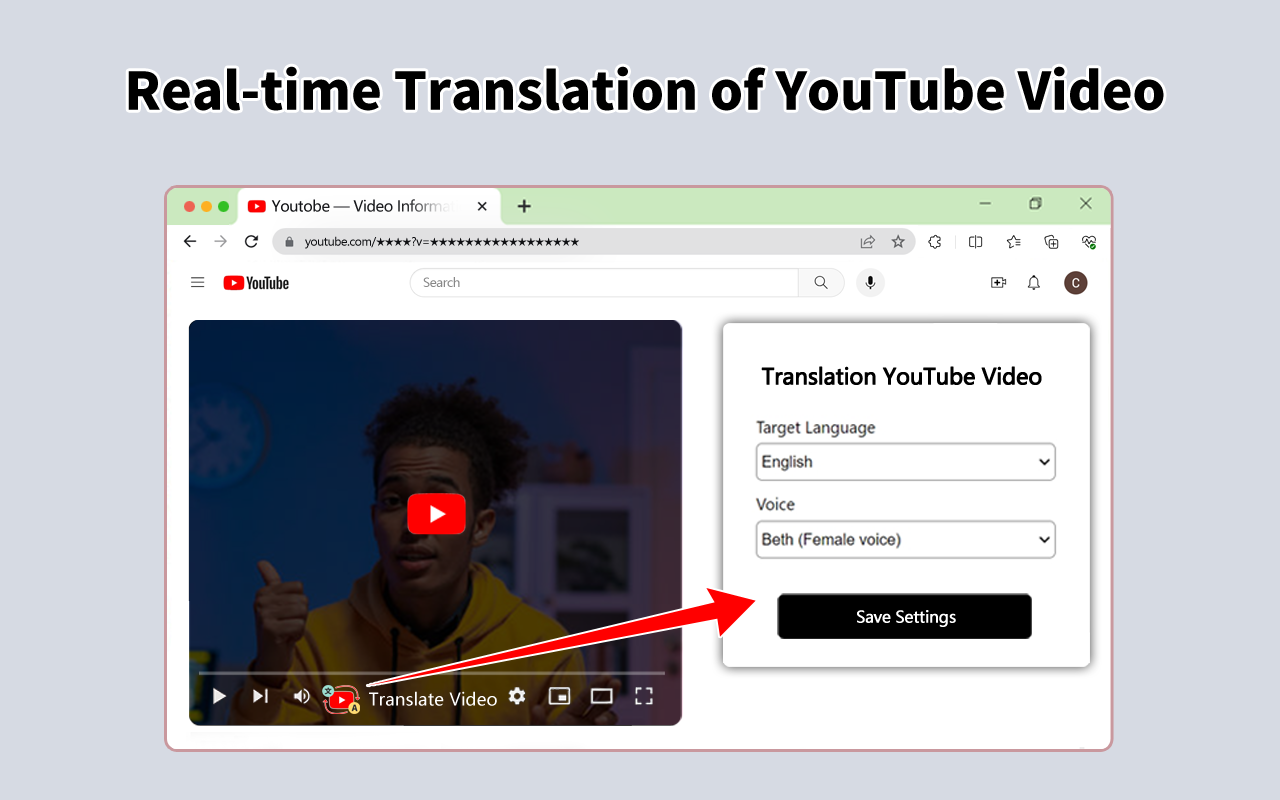
YouTube Dubbing插件,一键将英语视频转换为中文的声音进行播放,非常适合用来看国外教程类的视频,
目前支持Youtube 和Udemy 。PC,Android ,IOS 都支持。
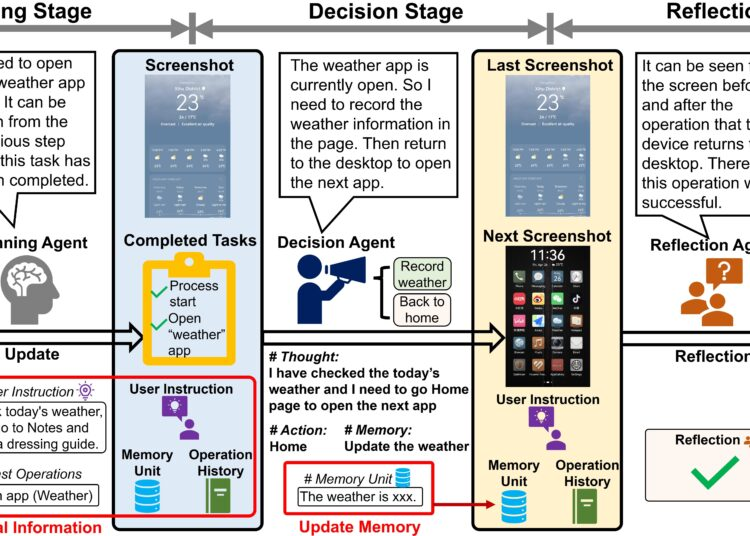
阿里和北交大的Mobile-Agent-v2 发布了Mobile-Agent-v2,一款通过多智能体协作实现有效导航的移动设备操作助手,它通过多代理协作实现了对移动设备的自动化操作和视觉感知功能,让ai可以像真人一样模拟点击、滑动、输入等操作来操控你的手机,从而执行各种任务。

直接在网络浏览器中实现实时语音识别长期以来一直是一个备受追捧的里程碑。 Hugging Face 工程师(昵称“Xenova”)开发的 Whisper WebGPU 是一项突破性技术,利用 OpenAI 的 Whisper 模型实现浏览器内实时语音识别。这一显着的发展是与人工智能驱动的网络应用程序交互的巨大转变。
Luma AI 刚刚推出了一款类似 Sora 的 AI 视频生成器,名为 Dream Machine。
但与 Sora 或 KLING 不同的是,它完全向公众开放。

Truecaller 很自豪地宣布与 Microsoft 建立合作伙伴关系,利用 Microsoft Azure AI Speech 的全新个人语音技术。 Truecaller 的 AI 助手于 2022 年 9 月首次推出,已经融合了多种 AI 技术,可以自动为您接听电话、屏幕呼叫、接收消息、代表您回复或记录通话以供您以后查看。
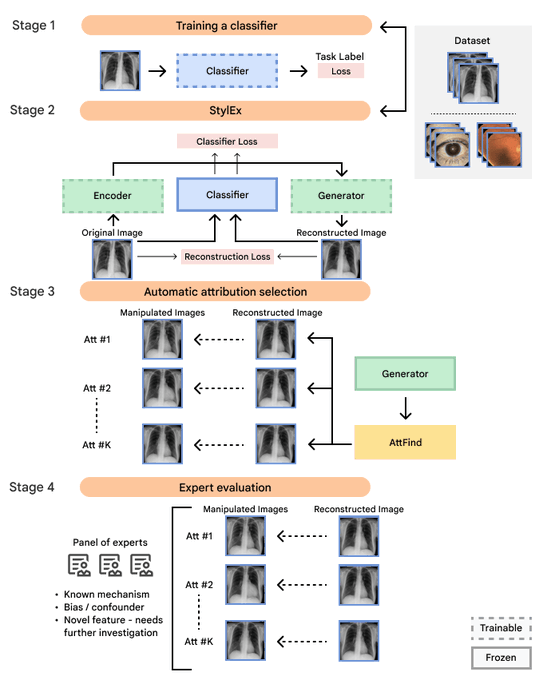
机器学习 (ML) 有潜力彻底改变医疗保健,从减少工作量和提高效率到发现新的生物标志物和疾病信号。为了负责任地利用这些好处,研究人员采用可解释性技术来了解机器学习模型如何进行预测。然而,当前基于显着性的方法突出了重要的图像区域,通常无法解释特定的视觉变化如何驱动机器学习决策。

ChatTTS:专门为对话场景设计的文本到语音TTS模型
该模型经过超过10万小时的训练,公开版本在 HuggingFace 上提供了一个4万小时预训练的模型。
专为对话任务优化,能够支持多种说话人语音,中英文混合等。
Seed-TTS,这是一系列大规模自回归文本转语音(TTS)模型,能够生成几乎与人类语音无法区分的语音。
Seed-TTS作为语音生成的基础模型,在语音上下文学习中表现出色,在说话者相似性和自然性方面的表现与真实人类语音在客观和主观评估中相匹配。
通过微调,我们在这些指标上获得了更高的主观评分

可以将你直播说话时候的声音变声其他各种角色和性别的声音。
还能调整音调、音调动态和混响等参数,塑造个性化的声音。
也可以将你声音与任何角色的声音以任意比例混合,创造出新的声音 。
Audio Native 是一个嵌入式音频播放器,可以自动为网页内容生成语音
只需插入一段简短的代码,即可插入到任何网页和内容中,自动为内容生成语音旁白。
您现在正在阅读的这一行的上方有一个播放按钮。按播放键,您可以收听由 ElevenLabs 语音自动生成的这篇文章的旁白。我们将这种嵌入式语音播放器称为“Audio Native”。
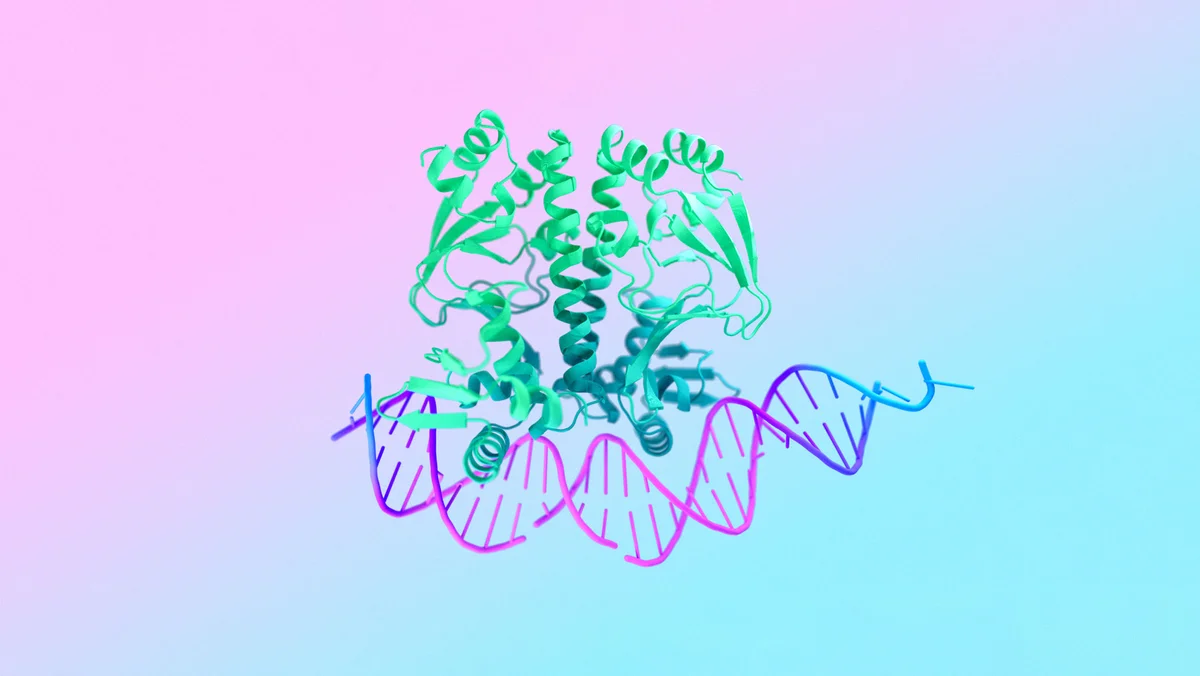
能够预测所有生命分子结构和相互作用 AI 模型
该模型能够生成蛋白质、DNA 和其他分子的 3D 结构,并揭示它们如何组合在一起。
该模型还能够模拟影响细胞健康的化学变化,并检测可能导致疾病的异常。
AlphaFold 3 将为全球科学研究人员和机构免费开放。它的高精度和新一代架构可支持药物发现和生物学的突破性进展。