SAM模型视频分割项目
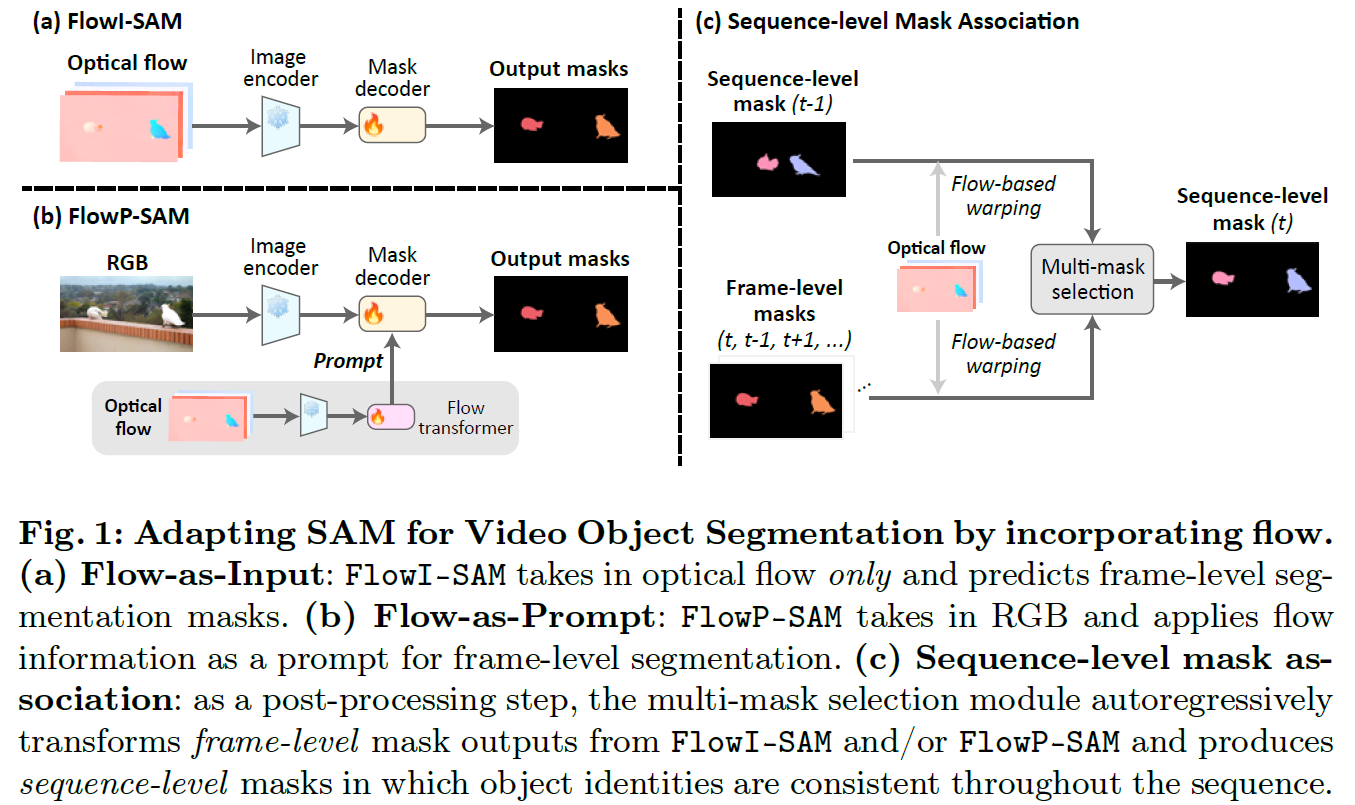
本项目的目标是运动分割——发现并分割视频中的运动对象。这是一个被广泛研究的领域,有许多仔细的、有时甚至是复杂的方法和训练方案,包括:自监督学习、从合成数据集学习、以对象为中心的表示、非模态表示等等。对本文的兴趣是确定 Segment Anything 模型 (SAM) 是否有助于完成此任务。
本项目的目标是运动分割——发现并分割视频中的运动对象。这是一个被广泛研究的领域,有许多仔细的、有时甚至是复杂的方法和训练方案,包括:自监督学习、从合成数据集学习、以对象为中心的表示、非模态表示等等。对本文的兴趣是确定 Segment Anything 模型 (SAM) 是否有助于完成此任务。

来自斯坦福大学、麻省理工学院和 Harvey Mudd 的研究人员设计了一种方法,通过将搜索过程表示为序列化字符串“搜索流”(SoS),来教授语言模型如何搜索和回溯。他们提出了一种统一的搜索语言,并通过倒计时游戏进行了演示。在搜索流上预训练基于 Transformer 的语言模型将准确率提高了 25%,而通过策略改进方法进一步微调则解决了 36% 以前未解决的问题。这表明语言模型可以学习通过搜索解决问题、自我改进并自主发现新策略。
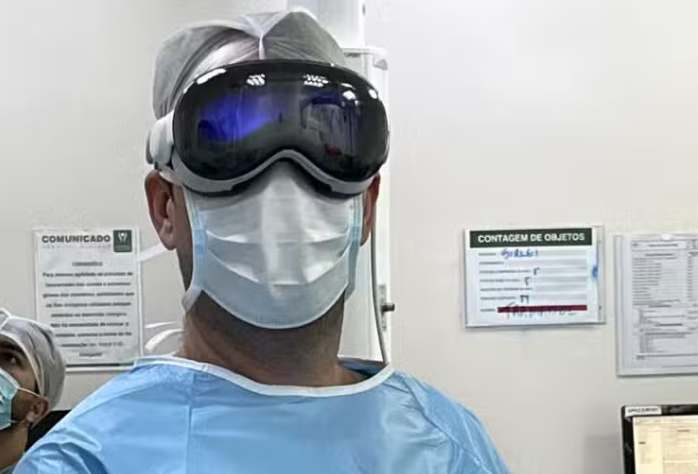
巴西的骨科医生Bruno Gobbato最近使用Vision Pro成功进行了肩袖撕裂的手术。这种手术通常是由于肌腱组织的长期磨损和撕裂造成的。

2023年9月美国空军取得全球首次的突破,他们成功使用一架改装的F-16战斗机(X-62)与一架有人驾驶的F-16战机进行了空中对抗。

阿特拉斯一动不动地俯卧在互锁的健身垫上。唯一的配乐是电动机的呼呼声。确切地说,它并不安静,但与它祖先的液压冲击相比,这算不了什么。

可以用来自己进行机器学习
机器人手臂设计为5自由度(DoF)加夹持器,允许它进行广泛的运动,包括旋转、上下举起、弯曲等。
两个这样的手臂还能够折叠衣服。

哥伦比亚大学的创意机器实验室开发出了一种名为 Emo 的人形机器人头它能够精准恰如其分的模拟面部表情。
Emo装备了26个精密的执行器,可以在 840 毫秒内预测和反映人类的面部表情,包括微笑。

它支持文字、网页链接、PDF、提问等直接转视频
也就是你输入文字、链接NoLang能以视频形式快速回答。
输入PDF文件,会先给你总结内容,然后根据总结的内容在生成一个解答视频。

它可以通过文本提示将数学、物理问题转换成视频内容
它会自动生成包括图表、图示、动画原理,还包含讲解内容的2分钟左右的视频。
能非常直观的帮助你了解一些知识和原理。