
H2O:将人类动作实时转换为机器人动作,实时全身遥控机器人
Human to Humanoid (H2O)由卡内基梅隆大学的研究团队开发,它允许人们通过一个简单的RGB摄像头让机器人实时模仿人的全部动作。
Human to Humanoid (H2O)由卡内基梅隆大学的研究团队开发,它允许人们通过一个简单的RGB摄像头让机器人实时模仿人的全部动作。

能够通过文字提示创造出适用于各种场景的声音和音效
如游戏中的射击和跳跃声音、动画中的雨声环境以及视频中的地铁到站声音等。
设置好语音,点击播放按钮,可以自动朗读GPT生成的内容
ChatGPT 的数据分析Data Analysis 将升级到V2 版本,功能更加强大!

Phoenix是世界上第一个由Carbon驱动的人形通用机器人,这是一个开创性且独特的AI控制系统,可以赋予机器人人类般的智能!
Carbon可以将自然语言转化为现实世界中的行动。可以使机器人可以完成十几个不同行业确定的数百项任务。

之前的YOLO系列模型相比,YOLOv9在不牺牲性能的前提下实现模型的轻量化,同时保持更高的准确率和效率。
这使得它可以在各种设备和环境中运行,如移动设备、嵌入式系统和边缘计算设备。
YOLOv9通过改进模型架构和训练方法,提高了对象检测的准确性和效率

YOLOv8能够在图像或视频帧中快速准确地识别和定位多个对象,还能跟踪它们的移动,并将其分类。
除了检测对象,YOLOv8还可以区分对象的确切轮廓,进行实例分割、估计人体的姿态、帮助识别和分析医学影像中的特定模式等多种计算机视觉任务。

UMI可以将人类在复杂环境下的操作技能直接转移给机器人,无需人类编写详细的编程指令。
也就是通过人类亲自操作演示然后收集数据,直接转移到机器人身上,使得机器人能够快速学习新任务
UMI整合了精心设计的策略接口,包括推理时延匹配和相对轨迹动作表示,使得学习到的策略不受硬件限制,可跨多个机器人平台部署。

它可以根据文字描述来生成视频。但它不是基于扩散模型,而本身就是个LLM,可以理解和处理多模态信息,并将它们融合到视频生成过程中。
不仅能生成视频,还能给视频加上风格化的效果,还可修复和扩展视频,甚至从视频中生成音频。
一条龙服务…
例如,VideoPoet 可以根据文本描述生成视频,或者将一张静态图片转换成动态视频。它还能理解和生成音频,甚至是编写用于视频处理的代码。

该机器人只需要1.5厘米的小切口来进行腹部手术,这比一枚硬币还小,大大减少了手术对患者身体的伤害和术后恢复时间。

该机器人能够完全独立地执行任务,无需人类远程操控或通过预设脚本。
所有动作都是实时通过神经网络计算得出。
机器人基于视觉的端到端神经网络直接从图像中学习如何控制其动作,包括驾驶、操纵手臂和抓取器、控制躯干和头部等。
包括公开预览的Assistants API、新的文本到语音(TTS)功能、即将推出的GPT-4 Turbo和GPT-3.5 Turbo模型更新、新的嵌入模型以及微调API的更新。
与之前的聊天完成API相比,Assistants API能够记住之前的对话内容,创建持久化和无限长的线程。
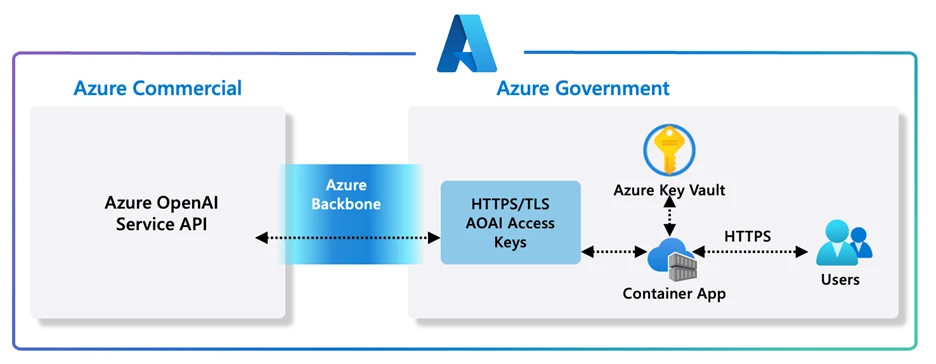
Assistants API 是一项由 Azure OpenAI 提供的新服务,它旨在帮助开发者在他们的应用程序中更容易地创建高质量的人工智能助手体验。
