Minipic:高效的在线图像转换和压缩工具
它的目标是帮助用户以最小的图片文件大小,保留尽可能高的图像质量,从而加快网页加载速度、节省存储空间,并优化整体用户体验。支持将图像转换为现代格式,如WebP、AVIF、PNG、JPEG和JPEGXL。
它的目标是帮助用户以最小的图片文件大小,保留尽可能高的图像质量,从而加快网页加载速度、节省存储空间,并优化整体用户体验。支持将图像转换为现代格式,如WebP、AVIF、PNG、JPEG和JPEGXL。
ImageToPrompt.site 是一个免费的在线工具,可以将图像转换为详细的文本描述(提示),以便用于AI艺术生成。
无需注册即可使用该工具,支持多种图像格式(如PNG、JPG和WEBP),最大文件大小为4MB。
一个完整的照片相册解决方案,集成了人工智能智能处理、浏览器图像压缩等多种功能。
可以通过该项目上传和展示图片,支持多种图像格式,并利用云存储服务进行数据管理。
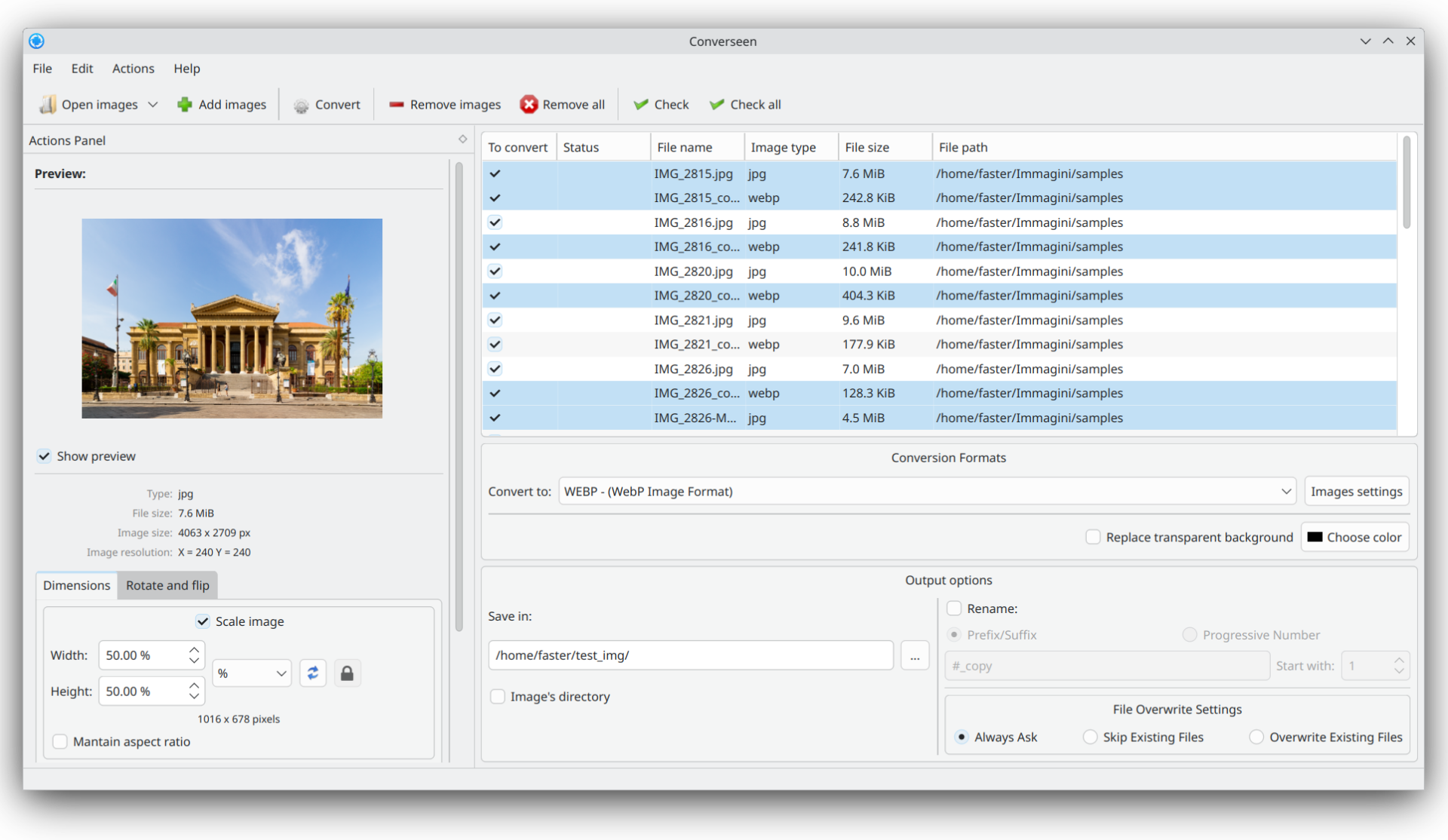
一款免费的跨平台批量图像处理软件,通过单击鼠标一次,转换、调整大小、旋转和翻转无限数量的图像。
还可以将整个PDF文档转换为一组具有用户自定义特征的图像。可以选择超过100种格式,设置图像的大小、分辨率和文件名。
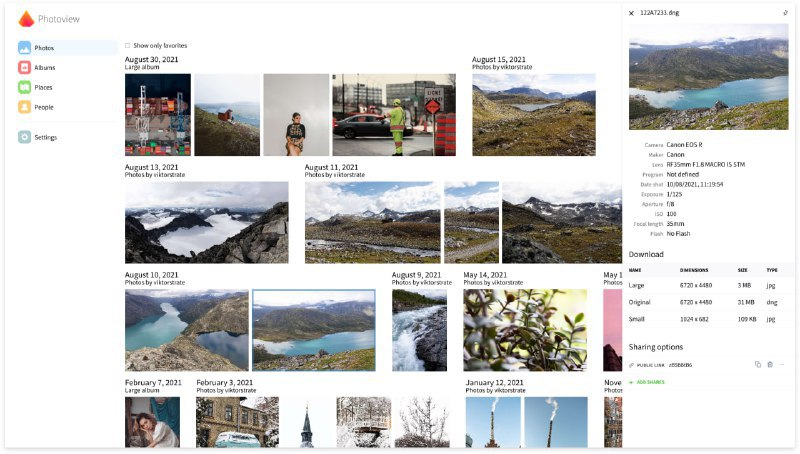
可以通过配置Photoview来扫描本地文件系统中的媒体文件,系统会自动生成缩略图以加快浏览速度。
扫描完成后,媒体文件会在网页上以与文件系统相同的方式进行组织,可以轻松访问和分享相册及单个媒体文件
Hertz-dev 是由 Standard Intelligence 公司开发的首个会话音频开源模型。hertz-dev 是一个全双工、仅支持音频的 Transformer 基础模型。
一个高效的开源视觉语言模型,提供强大的图像理解能力,同时具有极小的资源占用。
提供了两个模型变体:Moondream 2B,拥有20亿参数,适用于一般图像理解任务,如图像描述、视觉问答和物体检测。
一个关于无限画布的教程,帮助开发者理解和实现无限画布的概念与功能。
无限画布是一种允许用户以非线性方式自由组织内容的界面,支持缩放、直观编辑基本图形(如移动、分组和修改样式)等功能。”
经常做自媒体的小伙伴们,水印移除一直是图片处理的难题,最近发现一款完全开源免费的 AI 水印移除工具:WatermarkRemover-AI。
一个开源的换脸项目,名字叫做 MagicMirror。它是由 GitHub 用户 idootop 开发的轻量化人脸替换工具,目标是通过图像处理技术将一张脸无缝替换到另一张图片中。
FreeAI 是一个开源的 AI 应用平台,基于 Pollinations.AI 提供的 API,旨在为用户提供免费且无限制的 AI 聊天助手、图像生成和语音合成服务。
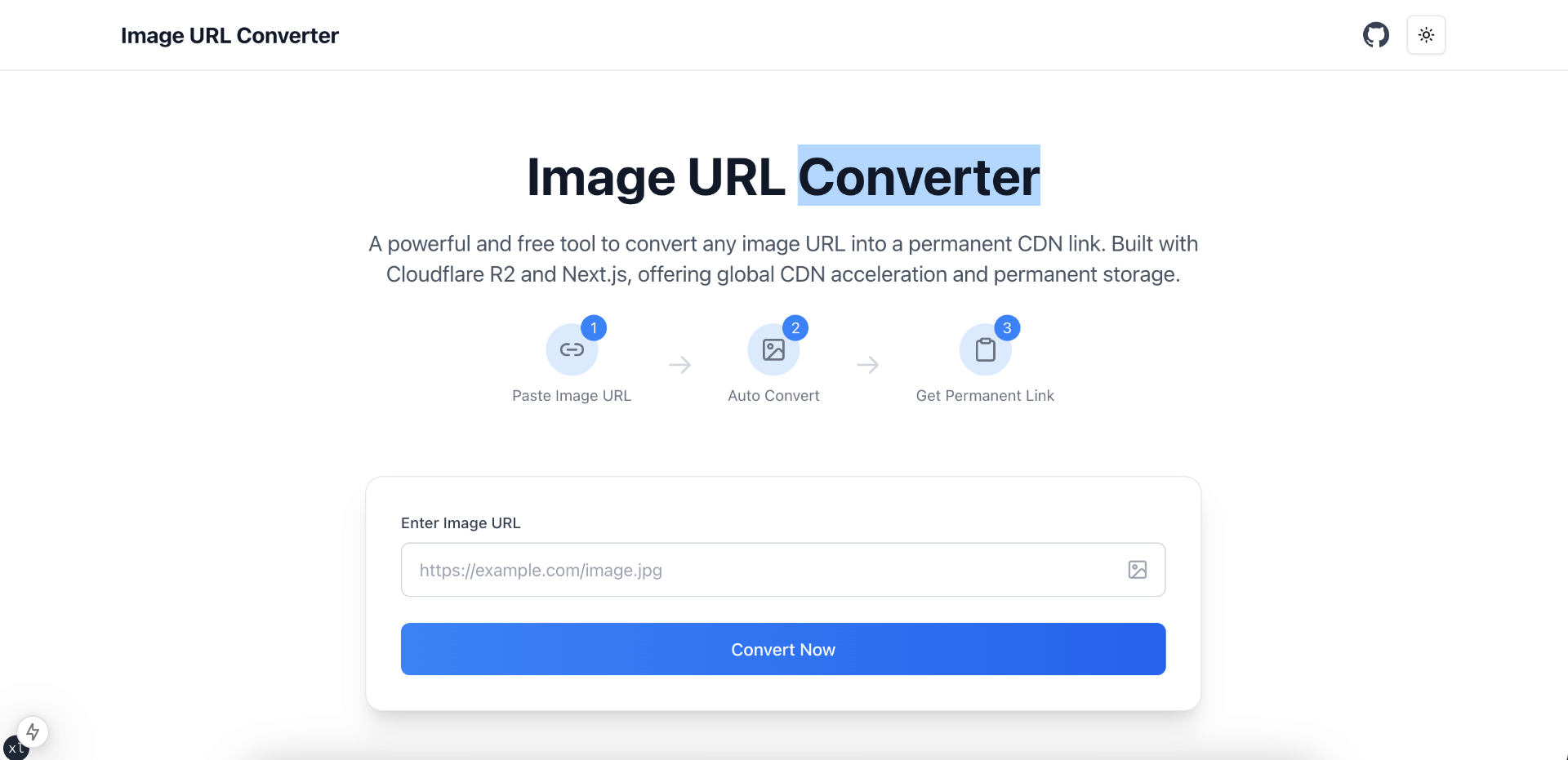
image-url-converter,这是由 GitHub 用户 weijunext 开发的一个基于 Node.js 的命令行工具,它的主要功能是:将 HTML 文件中使用的本地图片路径,批量转换为线上图片 URL
AimeBox是一款基于Langchain和Electron开发的多平台桌面聊天客户端,旨在为用户提供全离线、本地可执行的智能代理体验。该项目支持本地知识库、工具调用以及多个智能代理的集成,满足用户在不同场景下的多样化需求。
Saber-Translator是一款专为漫画爱好者设计的AI翻译工具,旨在帮助用户轻松跨越语言障碍,享受原汁原味的日文漫画。该工具利用先进的AI技术,智能检测漫画中的对话气泡,精准识别日文文本,并快速翻译成流畅自然的中文。