EXIF图库:基于 Nuxt 的 EXIF 照片画廊
exif-gallery-nuxt 是一个基于 Nuxt.js 构建的照片画廊应用,支持解析和展示照片的 EXIF 元数据。该项目结合了 Vue.js 和 Nuxt.js 的优势,为用户提供一个动态、高效的照片管理和浏览体验。
exif-gallery-nuxt 是一个基于 Nuxt.js 构建的照片画廊应用,支持解析和展示照片的 EXIF 元数据。该项目结合了 Vue.js 和 Nuxt.js 的优势,为用户提供一个动态、高效的照片管理和浏览体验。
在人工智能迅速发展的今天,智能聊天助手正在成为提升团队协作和工作效率的重要工具。HiveChat 是一款开源的 AI 聊天应用,专为 中小型团队 设计,旨在提供更智能、高效的沟通方式。
语言障碍和字幕制作的高成本限制了全球观众对优质视频内容的获取。
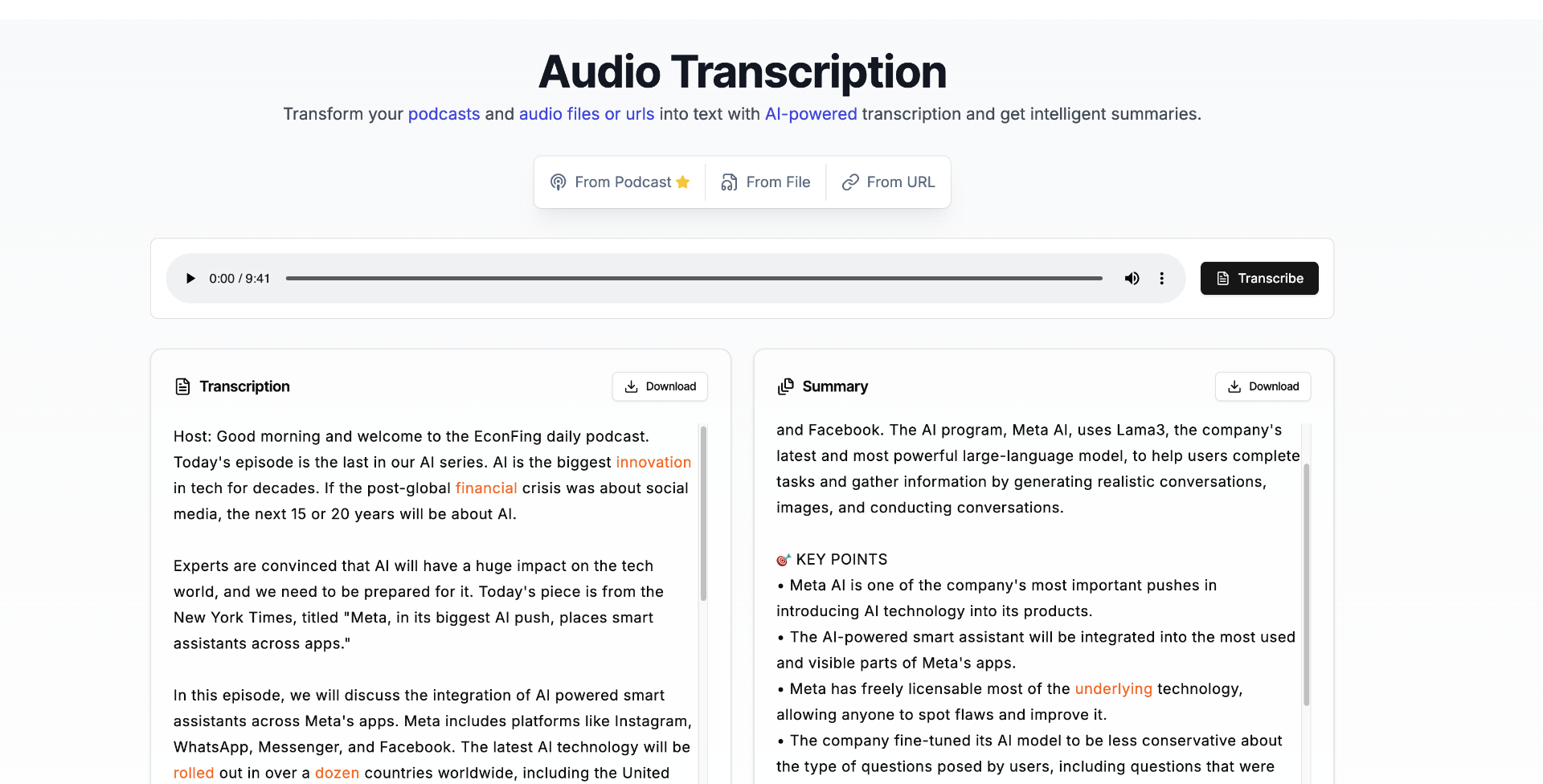
为了解决这一难题,隆重推出 VideoLingua
:一个基于 Next.js 和 OpenAI Whisper API 的播客转录应用,支持音频文件转录和智能摘要生成。
支持音频文件上传和 URL 输入两种方式、支持小宇宙播客音频转录、支持转录文本和摘要的下载,内置音频播放器,现代化的 UI 设计。
SQLChat 是一个开源的 SQL 聊天助手,旨在帮助用户通过自然语言与数据库交互,使 SQL 查询变得更加直观和高效。它能够理解用户的意图,并自动生成相应的 SQL 语句,适用于数据库管理、数据分析等场景。
Private-ASR 是一个基于开源项目 FunClip 修改的本地部署工具,集成了自动语音识别(ASR)、说话人分离、SRT 字幕编辑以及基于大型语言模型(LLM)的总结功能。
Storyboarder 是由 Wonder Unit 开发的一款开源分镜绘制工具,旨在帮助电影制片人、动画师和故事创作者快速绘制和编辑故事板。该工具提供简洁直观的界面,支持手绘、时间轴管理以及与其他绘图软件(如 Photoshop)的无缝集成
Video_note_generator 是一个由 GitHub 用户 whotto 开发的开源项目,旨在将视频内容一键转换为优质的小红书笔记,并自动优化内容和配图。
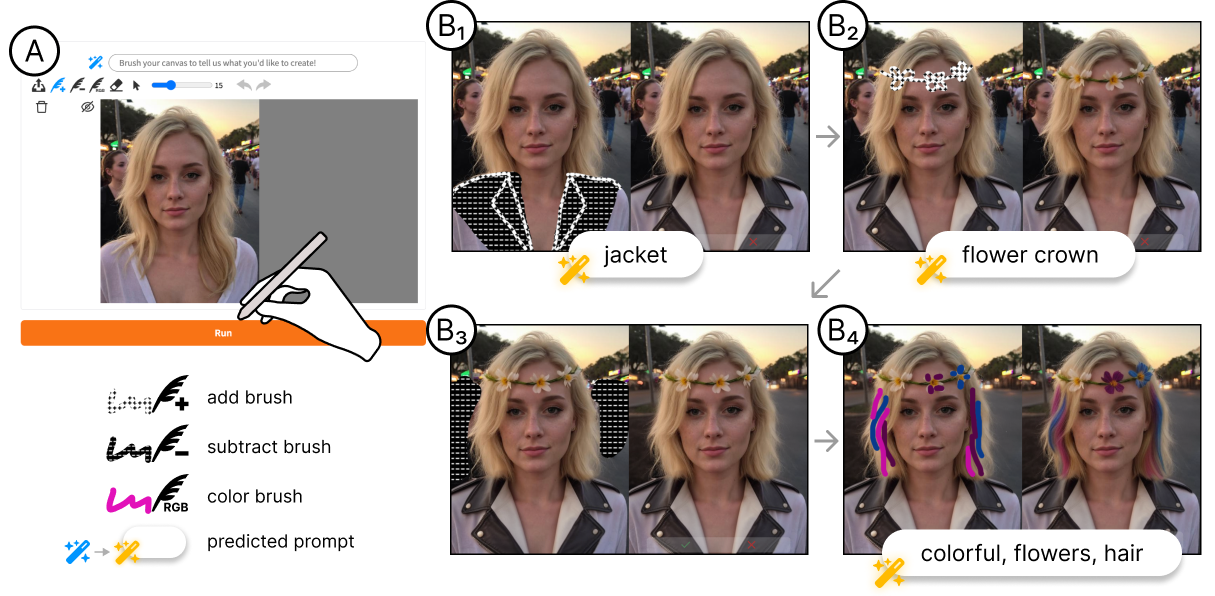
PhotoDoodle 是由 ShowLab 开发的开源图像编辑工具,旨在通过人工智能技术为照片添加艺术化的涂鸦元素。用户只需输入简单的文本提示,如“为猫添加光环和翅膀”,即可在保持原始照片背景完整性的同时,生成与之自然融合的艺术元素
AdvancedLivePortrait-WebUI 是一个基于深度学习的图像生成与编辑平台,用户通过直观的 Web 界面能够实时创建和调整个性化人像。项目结合图像处理、深度学习与前端技术,为用户提供了一个流畅且富有互动性的体验。
WanX 2.1 是由阿里巴巴通义万相团队开发的前沿视频生成模型,代表了 AI 驱动视觉内容创作的重大突破。它不仅支持高质量的文本到视频和图像到视频生成,还在物理模拟、多语言支持和视觉一致性方面表现出色。通过其开源计划,WanX 2.1 将为全球开发者提供强大的工具,助力创意内容生产、教育培训、娱乐和营销等多个领域的应用创新。
Google Whisk 是一款创新的图像生成工具,用户无需输入复杂的文本提示,只需上传参考图片,即可快速生成符合预期的图像。
该工具结合了 Gemini 和 Imagen 3 模型,提供直观且高效的创作体验,适用于多种创作需求。