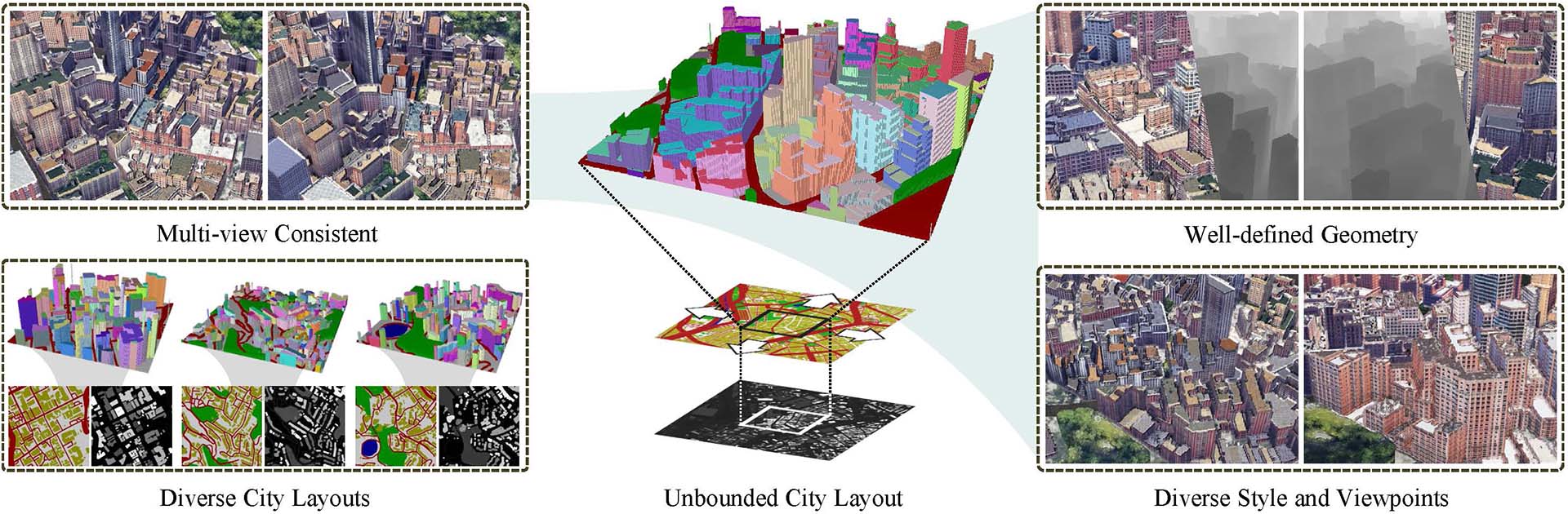
企图通过开源复现SORA的三个项目
Open-Sora
Colossal-AI 团队牵头的项目,目前发布了 1.1 模型,支持 2s~15s,144p 到 720p,任何宽高比文本到图像,文本到视频,图像到视频,视频到视频,无限时间生成的版本。
Open-Sora
Colossal-AI 团队牵头的项目,目前发布了 1.1 模型,支持 2s~15s,144p 到 720p,任何宽高比文本到图像,文本到视频,图像到视频,视频到视频,无限时间生成的版本。
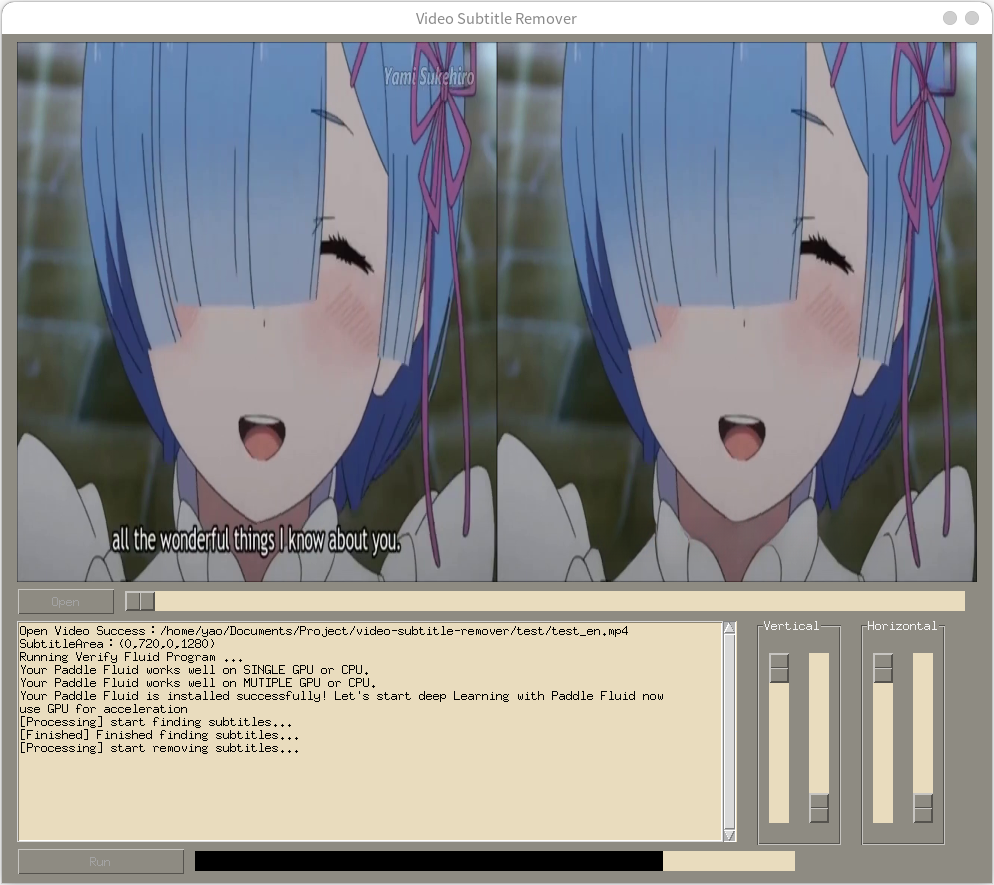
Video-subtitle-remover (VSR) 是一款基于AI技术,将视频中的硬字幕去除的软件。 主要实现了以下功能:
无损分辨率将视频中的硬字幕去除,生成去除字幕后的文件
通过超强AI算法模型,对去除字幕文本的区域进行填充(非相邻像素填充与马赛克去除)
支持自定义字幕位置,仅去除定义位置中的字幕(传入位置)
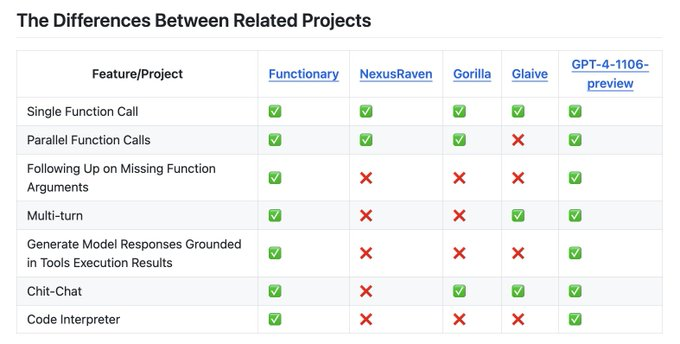
Functionary 是一种可以解释和执行函数/插件的语言模型。
该模型确定何时执行函数,无论是并行还是串行,并且可以理解它们的输出。它仅根据需要触发功能。函数定义以 JSON 架构对象的形式给出,类似于 OpenAI GPT 函数调用。
统一 Bedrock、Azure、OpenAI、Cohere、Anthropic、Ollama、Sagemaker、HuggingFace、Replicate 等 100 多种 LLM 的 API 输入输出、异常处理和负载均衡等操作的开源项目
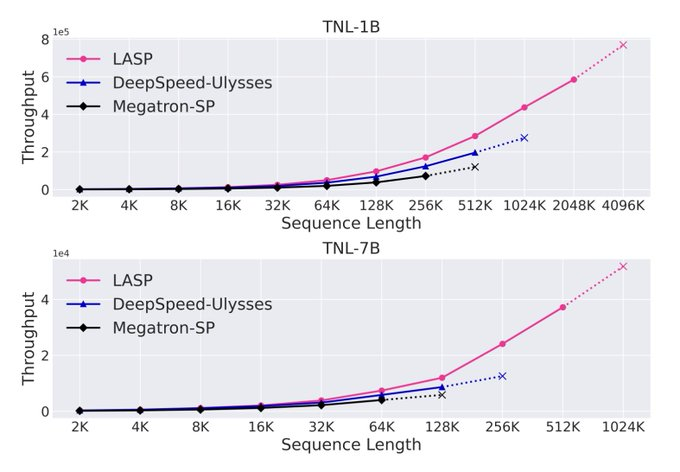
上海人工智能实验室和 TapTap 的研究人员提出了线性注意序列并行 (LASP) 技术,该技术优化了线性 Transformer 上的序列并行性。它采用点对点 (P2P) 通信在节点内或节点间的 GPU 之间进行有效的状态交换。 LASP 最大限度地利用了线性注意力中的右积核技巧。重要的是,它不依赖于注意力头分区,使其适用于多头、多查询和分组查询注意力。
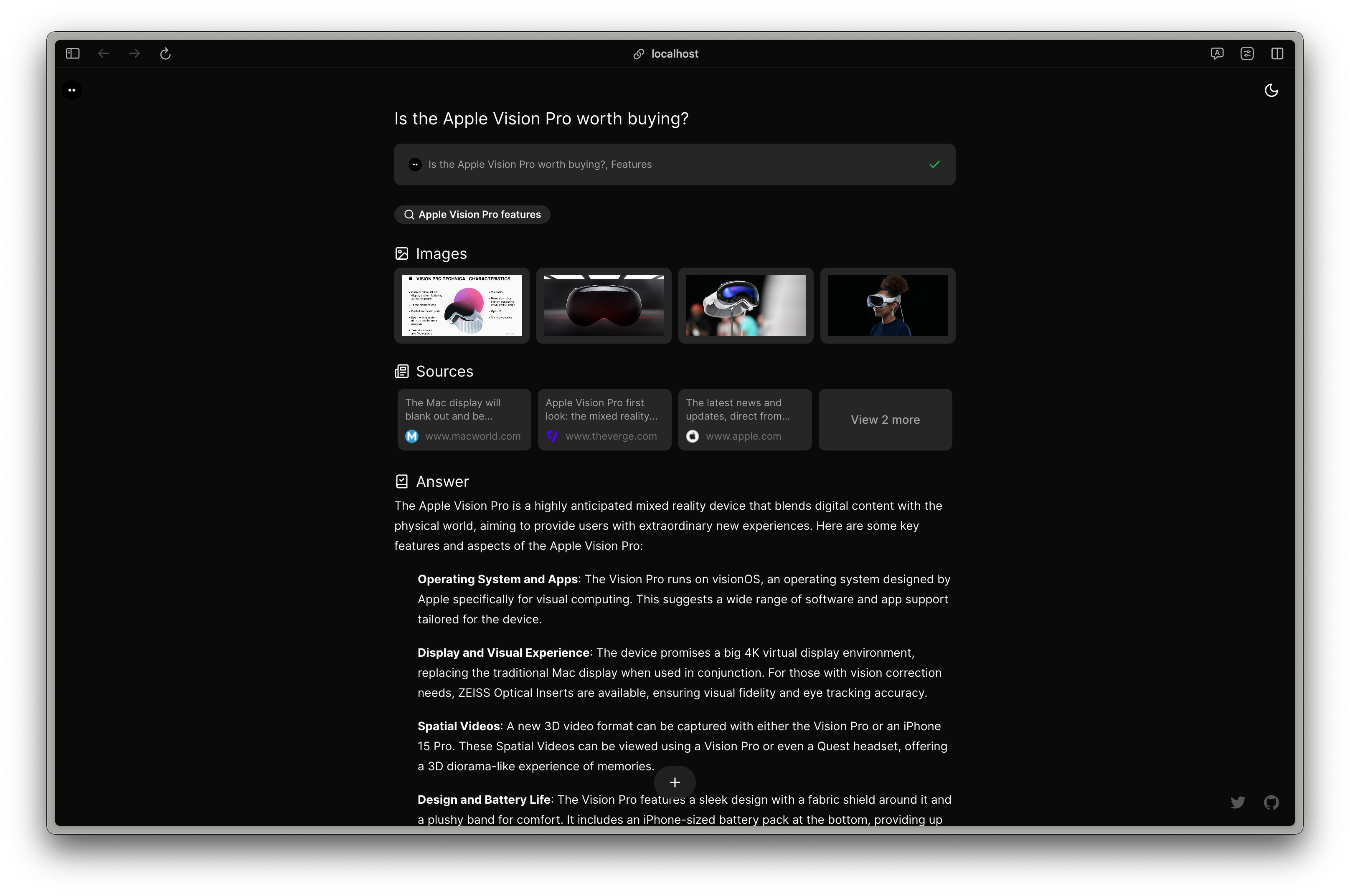
Morphic 只用 OpenAI 与搜索服务 @tavilyai 的 API 就能整得像模像样,换成 Gemini 与 Google Search 的 API 也一样能行。感觉 Perplexity 给大家带了 AI 时代的问答式搜索体验后,这种模式就会被大家学去强化自己的功能了
可以用来自己进行机器学习
机器人手臂设计为5自由度(DoF)加夹持器,允许它进行广泛的运动,包括旋转、上下举起、弯曲等。
两个这样的手臂还能够折叠衣服。
南洋理工大学的S-lab团队开发了一种新型的动画填色桶彩色化技术。
通过仅需对一帧进行手动彩色化,算法便能自动将颜色传播到后续的所有帧。
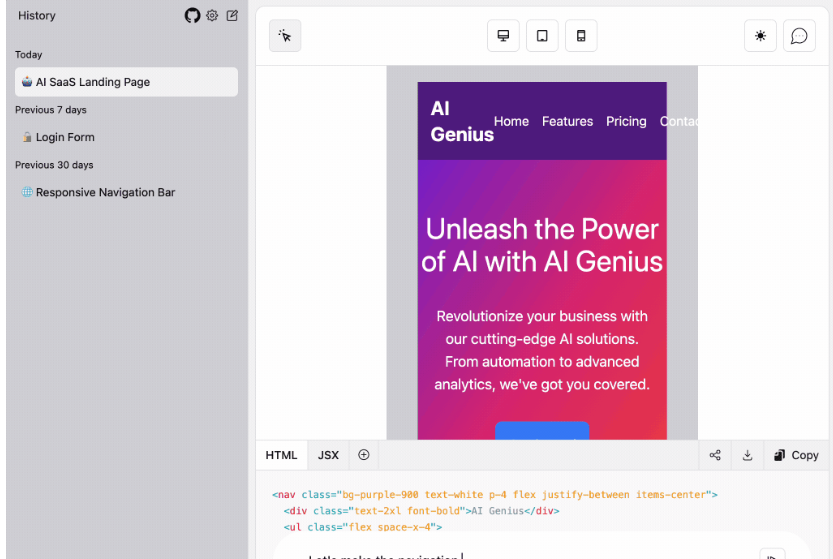
W&B 团队开发的一个开源工具,你可以通过文字来描述你想要的UI界面,OpenUI可以帮你实时进行渲染出效果。
你还可以通过聊天的方式进行任意修改,并将HTML转换为React、Svelte、Web Components等多种前端框架。
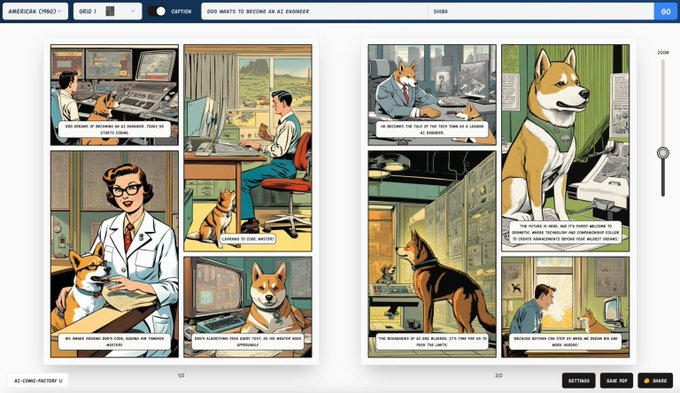
自动生成有情感、有故事性的漫画内容
它使用大语言模型和如SDXL来自动创建漫画面板。
你只需提供一个简单的文本提示,AI Comic Factory就能根据这个提示生成包含人物对话和场景描述的漫画。
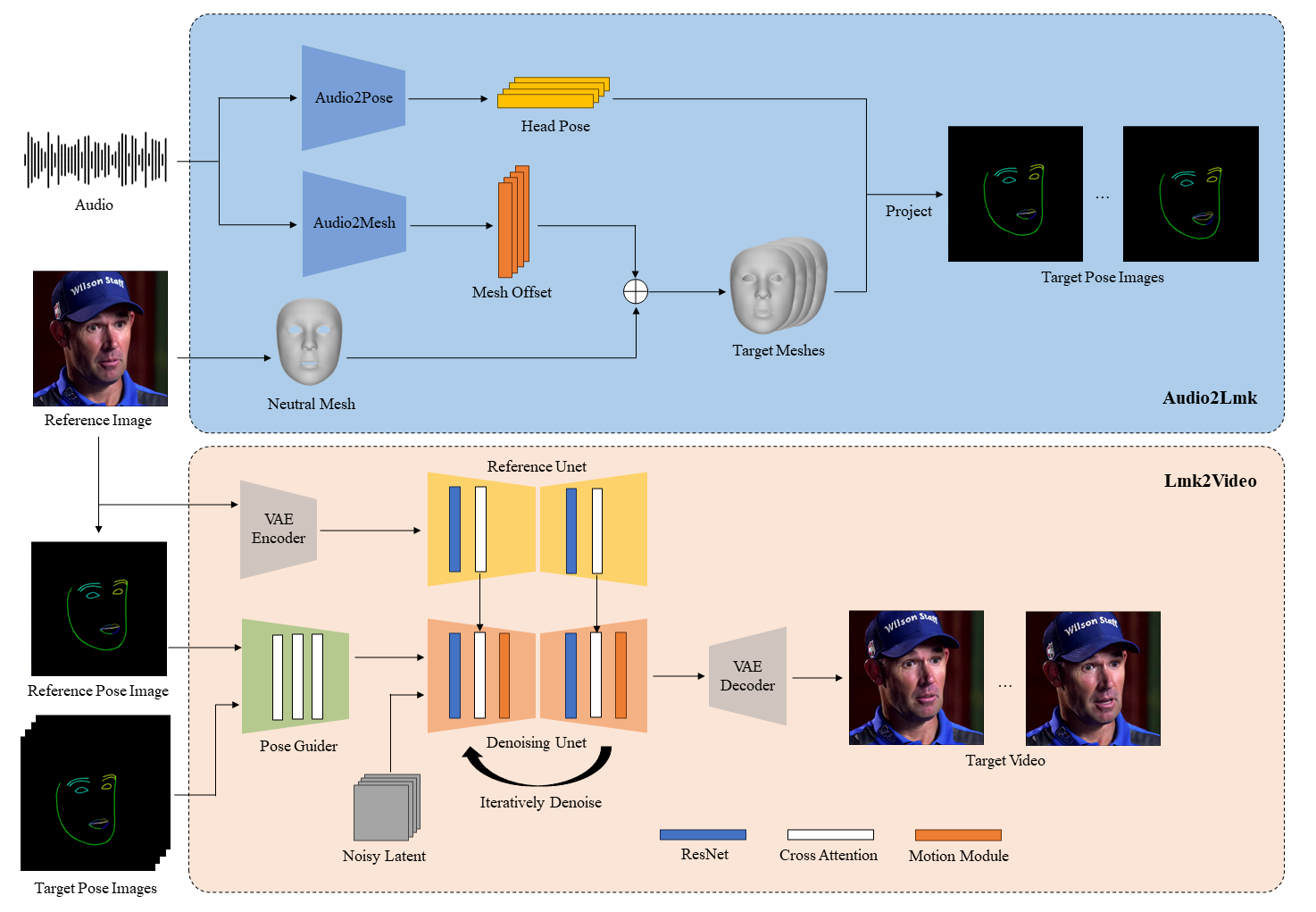
比阿里EMO先开源
AniPortrait:根据音频和图像输入 生成会说话、唱歌的动态视频
它可以根据音频(比如说话声)和一张静态的人脸图片,自动生成逼真的人脸动画,并保持口型一致。
现在,您可以在不安装任何东西的情况下尝试 LaVague,并根据自然语言指令实现自动化 Web 操作。
这个当中最好的部分?所有堆栈都是开源的!我们使用 Hugging Face #Gradio 作为 UI,他们的 Inference API 调用 #Mixtral 、 @llama_index 用于 #RAG ,LaVague 本身也是开放的-来源。
最新研究更新:提供每月最佳生成式AI论文列表,包括各项研究的摘要和主题。
免费课程列表:超过65个与生成式AI相关的免费课程。
面试资源:面试准备材料,特别是针对生成式AI领域的面试问题。
课程材料:《Applied LLMs Mastery 2024》课程材料。