开源项目

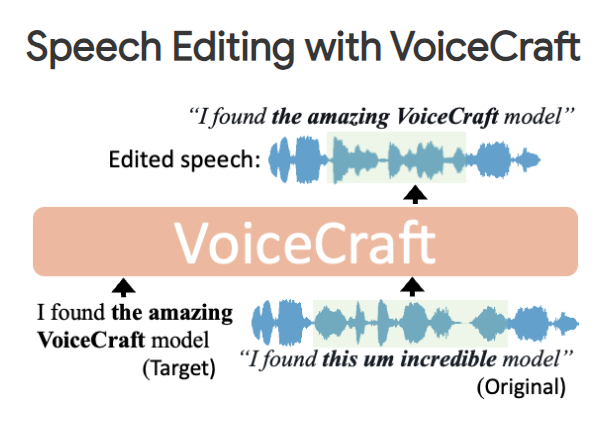

Open-Sora开源了
包括完整的文本到视频模型训练过程、数据处理、训练细节和模型检查点。
该项目由@YangYou1991 团队开发 这是 OpenAI Sora 在视频生成方面的开源替代方案。
可以在仅仅3天的训练后生成2~5秒的512×512视频。

OpenReplay:用户操作记录回放
OpenReplay是一个自托管的会话回放和分析开源工具
可以让开发人员像看电影一样回看用户如何与你的产品互动,包括他们点击了什么,输入了什么,甚至在遇到问题时他们的屏幕上发生了什么。
帮助你优化用户体验和提高产品性能。
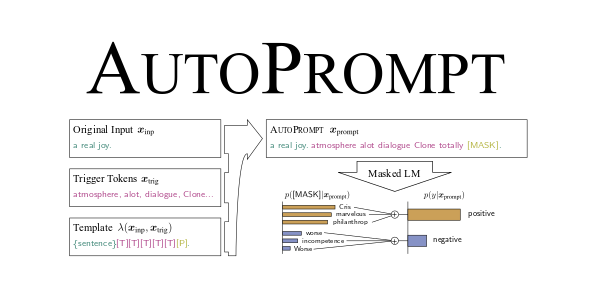
AutoPrompt:自动优化你的提示词
专为优化提示而设计的框架,通过不断的迭代过程,AutoPrompt 构建了一个包含各种挑战性边缘案例的数据集,用于测试和优化提示。
它能根据用户的具体意图自动生成定制化的提示,确保生成的提示能够精准地满足用户的需求。
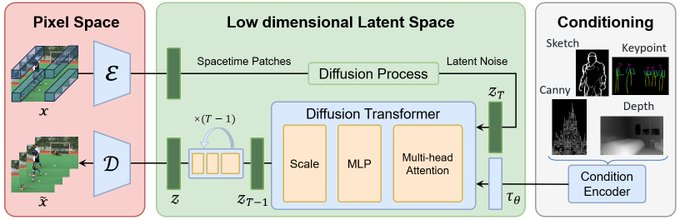
北京大学Yuangroup团队发起了一个 Open-Sora计划
旨在复现OpenAI 的Sora模型
Open-Sora计划通过视频VQ-VAE、Denoising Diffusion Transformer和条件编码器等技术组件,来实现Sora模型的功能。
MeloTTS:由MyShell AI开发的一个高质量的多语言文本到语音(TTS)库
支持英语、西班牙语、法语、中文、日语和韩语等多种语言。
速度非常快,支持中英混合的发音,能生成清晰、自然的语音输出。
即使在普通的在CPU上也能实现实时语音合成。


YOLOv9:实时对象检测,能够快速准确地在图像或视频中识别和定位多个对象
之前的YOLO系列模型相比,YOLOv9在不牺牲性能的前提下实现模型的轻量化,同时保持更高的准确率和效率。
这使得它可以在各种设备和环境中运行,如移动设备、嵌入式系统和边缘计算设备。
YOLOv9通过改进模型架构和训练方法,提高了对象检测的准确性和效率

YOLO-World&EfficientSAM&Stable Diffusion 能干啥?
实时检测视频中的特定对象,然后分割对象,使用自然语言来对特定的对象进行替换、修改、风格化等!
是不是很熟悉?科幻片里面的场景就实现了!
这意味着你可以对任意图像和视频里面的内容进行实时的替换和修改,甚至换掉视频中的某个人物。

YOLOv8:目标检测跟踪模型
YOLOv8能够在图像或视频帧中快速准确地识别和定位多个对象,还能跟踪它们的移动,并将其分类。
除了检测对象,YOLOv8还可以区分对象的确切轮廓,进行实例分割、估计人体的姿态、帮助识别和分析医学影像中的特定模式等多种计算机视觉任务。

UMI:斯坦福开发的一个机器人数据收集和策略学习框架
UMI可以将人类在复杂环境下的操作技能直接转移给机器人,无需人类编写详细的编程指令。
也就是通过人类亲自操作演示然后收集数据,直接转移到机器人身上,使得机器人能够快速学习新任务
UMI整合了精心设计的策略接口,包括推理时延匹配和相对轨迹动作表示,使得学习到的策略不受硬件限制,可跨多个机器人平台部署。

OpenAI推出的一音乐生成模型:Jukebox
OpenAI在2019年8月份就推出了他们的一音乐生成模型:Jukebox
Jukebox能够根据提供的歌词、艺术家和流派信息生成多种流派和艺术家风格的完整音乐和人声歌曲。
最牛P的是,3年前的质量就已经这样了…
而且据说Jukebox 2即将发布

AnyGPT:任意模态到任意多模态的大语言模型
通过连接大语言模型与多模态适配器和扩散解码器,AnyGPT实现了对各种模态输入的理解和能够在任意模态中生成输出的能力。
也就是可以处理任何组合的模态输入(如文本、图像、视频、音频),并生成任何模态的输出…
实现了真正的多模态通信能力。
这个项目之前叫NExT-GPT
OOTDiffusion:一个高度可控的虚拟服装试穿开源工具
可以根据不同性别和体型自动调整,和模特非常贴合。也可以根据自己的需求和偏好调整试穿效果
OOTDiffusion支持半身模型和全身模型两种模式。

PixelPlayer:MIT研究团队开发的项目
能自动从视频中识别和分离出不同的声音源,并与画面位置匹配。
例如,它可以识别出视频中哪个人物正在说话或哪个乐器正在被演奏。
而且还能够分别提取和分离这些声音源的声音。
PixelPlayer能自我学习分析,无需人工标注数据。
这种能力为音视频编辑、多媒体内容制作、增强现实应用等领域提供了强大的工具,使得例如独立调整视频中不同声音源音量、去除或增强特定声音源等操作成为可能。