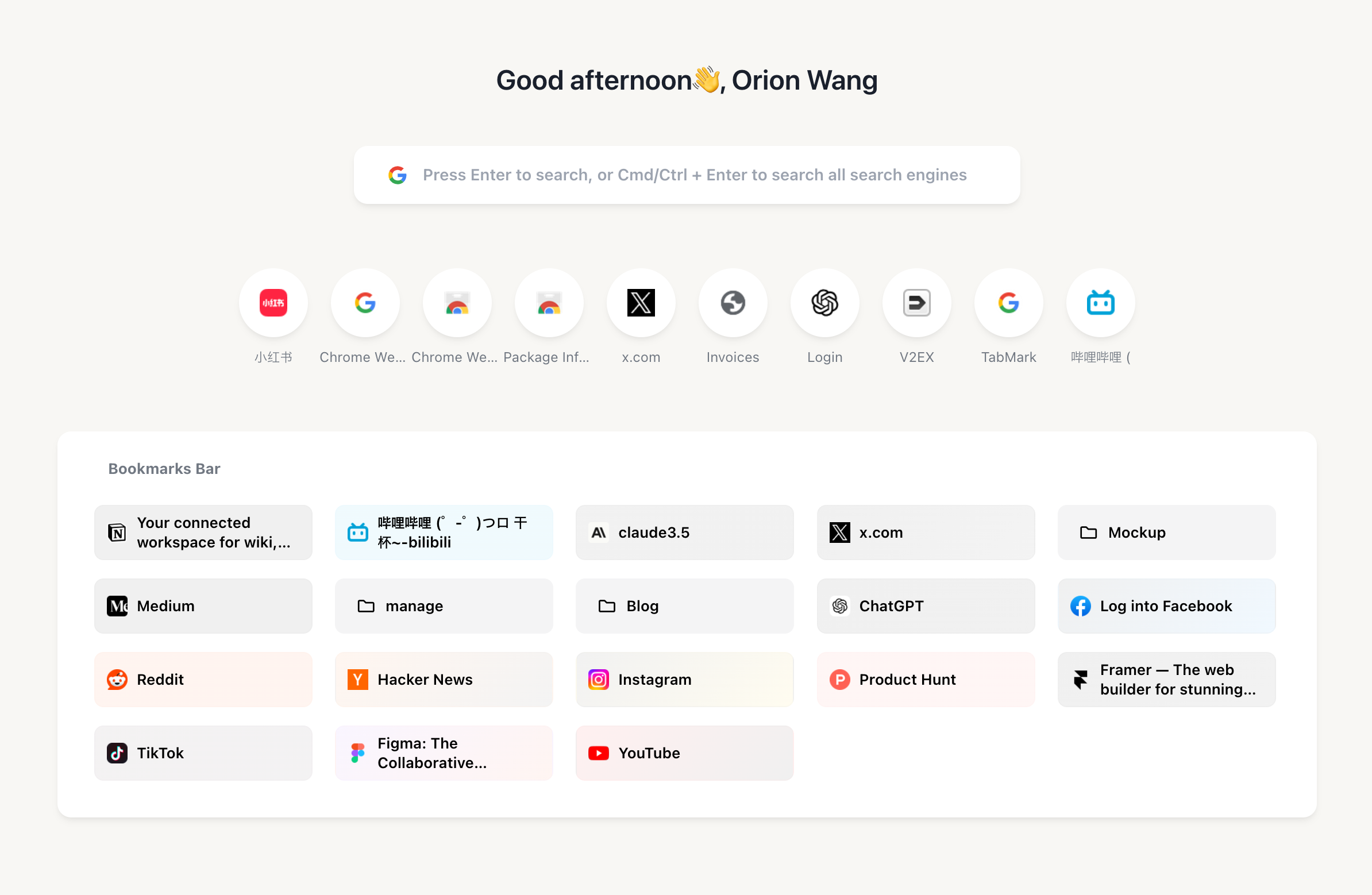
TabMark – 新标签页书签管理插件
TabMark 是一款功能强大且简洁的 Chrome 浏览器插件,它为你的浏览体验带来全新的便利。将新标签页打造成专属的书签管理中心,让你轻松访问常用网站,整理和归类书签,提升工作效率!
TabMark 是一款功能强大且简洁的 Chrome 浏览器插件,它为你的浏览体验带来全新的便利。将新标签页打造成专属的书签管理中心,让你轻松访问常用网站,整理和归类书签,提升工作效率!
NoteGen 是一个跨平台的笔记 APP,目前支持 Mac、Windows、Linux
开源地址在视频下方的描述中
软件安装完毕后,请先在设置页面配置 API Key 后即可正常使用。
Mac 用户需要配置屏幕录制权限,才可以使用截图记录功能。
同步和图床功能(可选),需要创建 Github 仓库,并配置好密钥

一个开源的多模态大语言模型,旨在实现实时的视觉和语音交互。
能够同时处理视频、图像、文本和音频数据,通过减少交互延迟、增强语音处理能力和改进多模态理解,达到了接近GPT-4o的水平。
顯著降低交互延遲。

雖然家庭中的智慧型設備已經發展到包括揚聲器、安全系統、燈光和恆溫器,但控制它們的方式仍然相對穩定。用戶可以與手機交互,或與技術人員交談,但這些通常不如它們所取代的簡單開關方便:“打開燈…不是那個…調高揚聲器音量…不要那麼大聲!”
華盛頓大學的研究人員開發了 IRIS
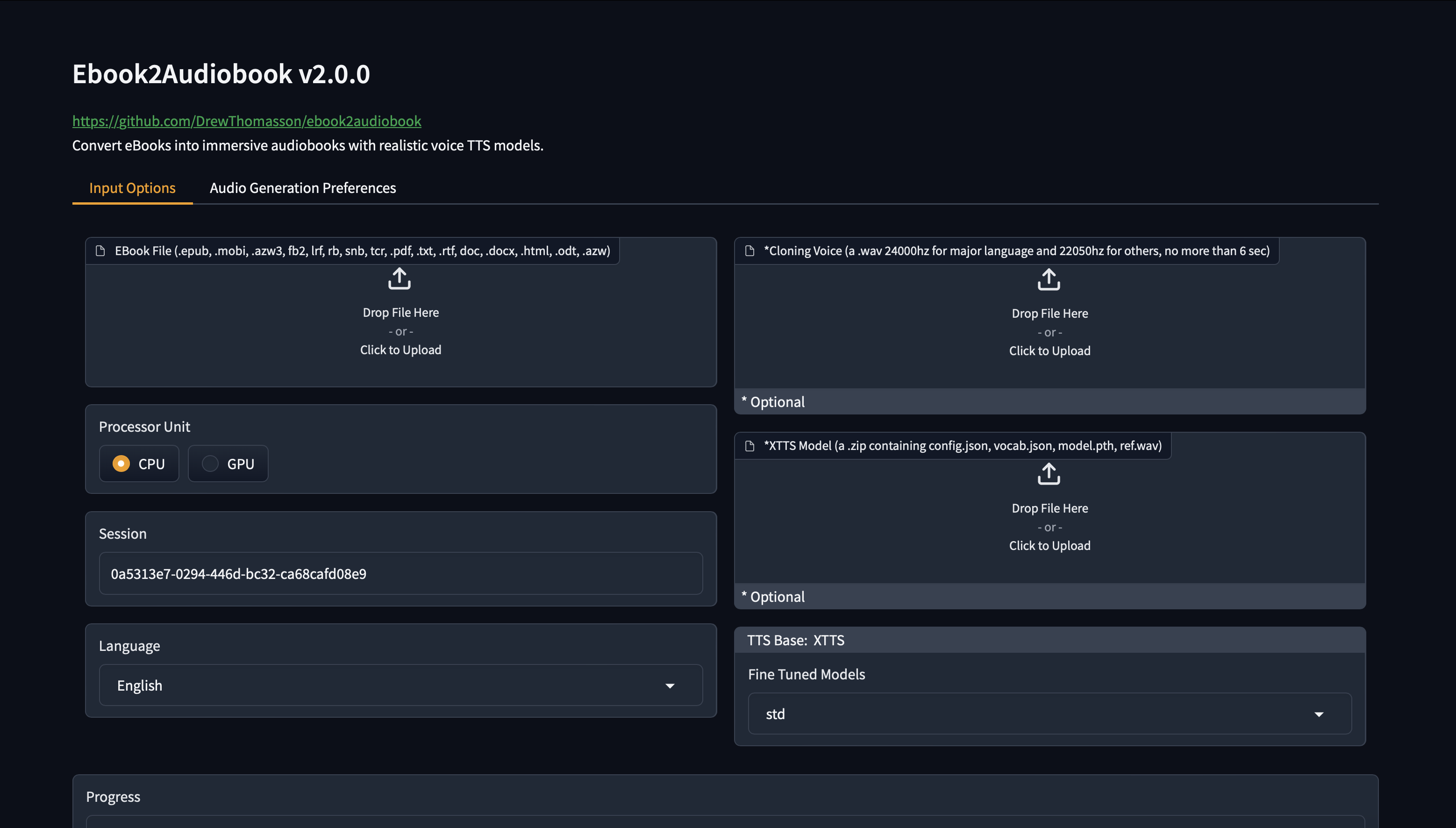
将电子书自动转换为有声书 支持语音克隆、多种语言
ebook2audiobookXTTS 是一个开源项目,旨在将电子书自动转换为有声书,并支持多种语言、语音克隆和章节信息的生成。该项目结合了 Calibre(电子书转换工具)和 Coqui XTTS(文本转语音引擎),通过简单的命令或Web界面完成转换
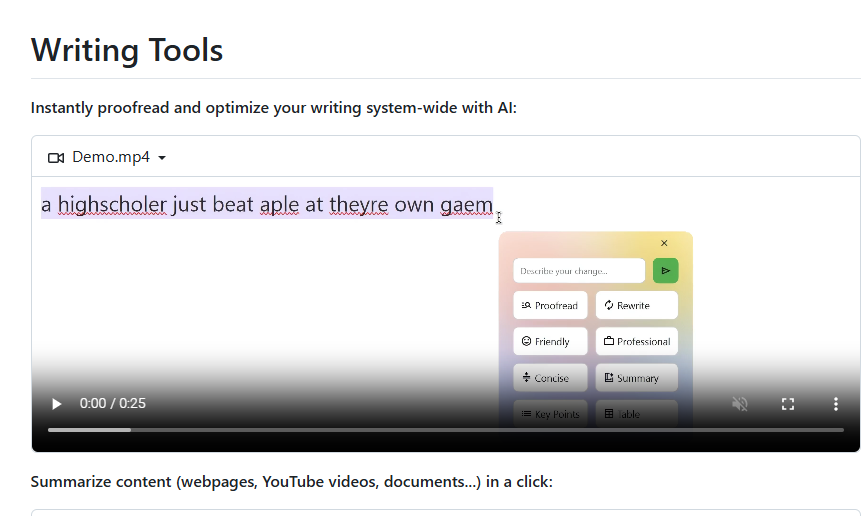
一款名为Writing Tools的开源应用为Windows 11用户带来了类似Apple Intelligence的写作工具功能。该应用支持与多种大型语言模型(LLM)连接,包括Gemini、OpenAI等,提供翻译、摘要、校对等多项功能。用户只需简单配置,即可在Windows系统上无缝使用这些高级写作辅助工具

可控人物影像產生旨在產生以參考影像為條件的人物影像,從而允許精確控制人物的外觀或姿勢。然而,現有方法儘管實現了較高的整體影像質量,但通常會扭曲參考影像的細粒度紋理細節。我們將這些扭曲歸因於對參考影像中相應區域的關注不夠
智音语音助手(Zhiyin_Butler)旨在开发一款通用型智能电脑管家,支持在桌面电脑Windows 10/11系统上安装和部署。项目的所有内容遵循Apache License 2.0开源协议,作为通用型电脑管家系统示例供开发者参考学习。

支持在移动设备上实时运行的超轻量级数字人模型
Ultralight-Digital-Human 是一个创新的开源项目,使得数字人在移动设备上的实时应用成为可能,旨在实现超轻量级的数字人模型,其能够在移动设备上实时运行。
支持在移动设备上实时运行的超轻量级数字人模型
提供了详细的训练和推理步骤

SynthID 使用各种深度学习模型和算法进行水印嵌入和识别,在不影响原始内容质量的前提下,帮助用户确定内容是否由 Google 的 AI 工具生成,并已集成到 Imagen、ImageFX、Gemini 等 Google 产品中