AI项目


国产的机器人:星尘智能AI机器人S1
星尘智能的英文名:Astribot
一款超级令人印象深刻的家用机器人,可以做饭、打扫卫生、洗衣服等。
它可以模仿人类动作迅速做出学习,而且灵活性极强

IDM-VTON:虚拟试衣技术
IDM-VTON能够捕捉到服装的细节,如纹理、图案和缝线等,这些细节在试衣图像中被准确地再现。
即使是在户外或者背景复杂的照片中,这项技术也能准确地展示衣物试穿效果,保持高质量的图像输出。
在多个不同的人物上展示同一件服装时,IDM-VTON依然能保持了服装细节的一致性。

Extropic 发布一种全新的热力学计算机
公司创始人Gill Verdon表示:非常高兴最终能分享更多有关 Extropic 正在构建的内容:一个全栈硬件平台,利用物质的自然波动作为生成人工智能的计算资源。
这种新颖的计算范式对世界实际上意味着什么?

Mistral入门指南:介绍
Mistral 推出的开源 Mixtral 8x7B 模型采用了“专家混合”(MoE)架构。与传统的 Transformer 不同,MoE 模型内置多个专家级前馈网络(本模型为8个),在进行推理时,由一个门控网络负责选择两个专家进行工作。这样的设置让 MoE 在保持与大型模型相当的性能的同时,能够实现更快的推理速度

Foundation Capital 这篇文章的论点非常有意思
他们认为AI公司正在颠覆SaaS平台的本质,即SaaS平台将会从软件即服务快速过度到服务即软件的范式。
在传统软件业务中,公司出售平台或工具的访问权限,但客户仍需要使用该工具来实现预期目标。
而在服务业务中,实现预期目标的责任则由销售服务的公司承担。
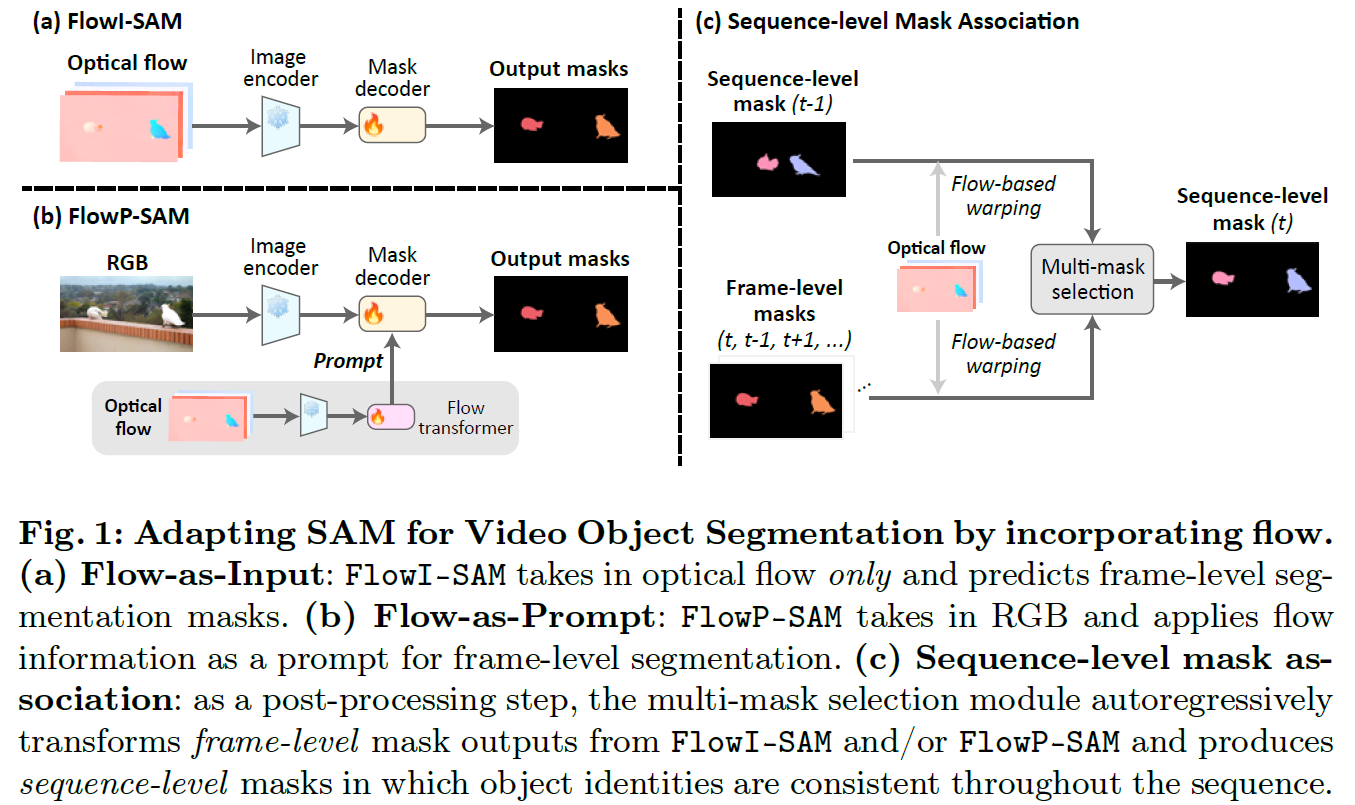
SAM模型视频分割项目
本项目的目标是运动分割——发现并分割视频中的运动对象。这是一个被广泛研究的领域,有许多仔细的、有时甚至是复杂的方法和训练方案,包括:自监督学习、从合成数据集学习、以对象为中心的表示、非模态表示等等。对本文的兴趣是确定 Segment Anything 模型 (SAM) 是否有助于完成此任务。

斯坦福大学和麻省理工学院的研究人员推出了搜索流
来自斯坦福大学、麻省理工学院和 Harvey Mudd 的研究人员设计了一种方法,通过将搜索过程表示为序列化字符串“搜索流”(SoS),来教授语言模型如何搜索和回溯。他们提出了一种统一的搜索语言,并通过倒计时游戏进行了演示。在搜索流上预训练基于 Transformer 的语言模型将准确率提高了 25%,而通过策略改进方法进一步微调则解决了 36% 以前未解决的问题。这表明语言模型可以学习通过搜索解决问题、自我改进并自主发现新策略。
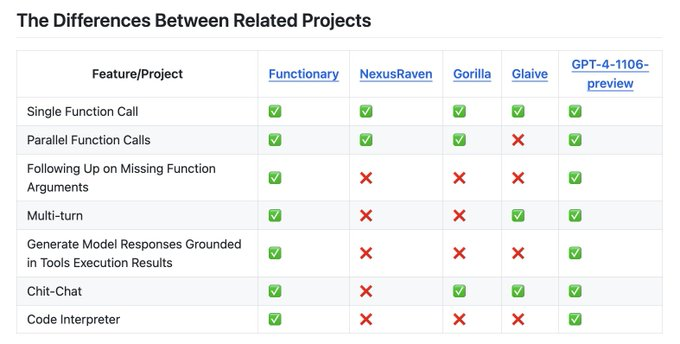
MeetKai发布OpenAI 函数调用模型的替代方案
Functionary 是一种可以解释和执行函数/插件的语言模型。
该模型确定何时执行函数,无论是并行还是串行,并且可以理解它们的输出。它仅根据需要触发功能。函数定义以 JSON 架构对象的形式给出,类似于 OpenAI GPT 函数调用。
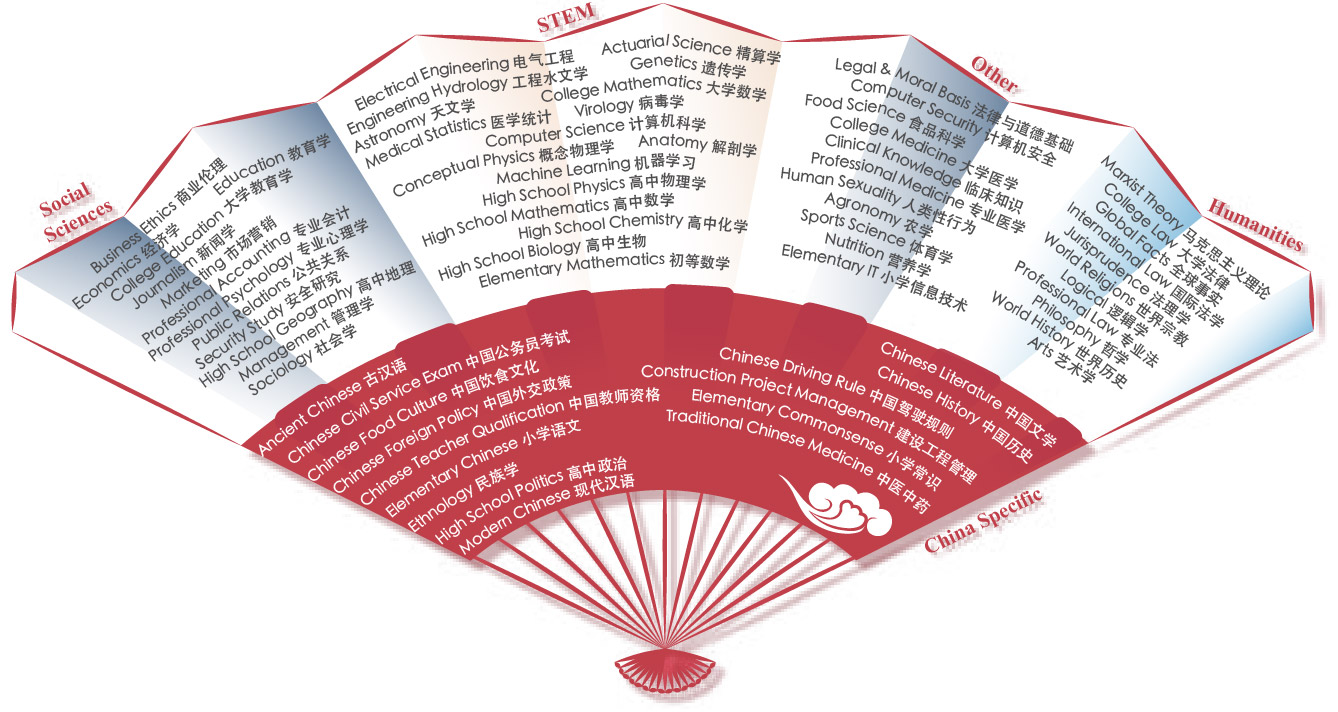
CMMLU 由来自中文教科书的多项选择题组成
CMMLU是一个综合性的中文评估基准,专门用于评估语言模型在中文语境下的知识和推理能力。
CMMLU涵盖了从基础学科到高级专业水平的67个主题。
它包括:需要计算和推理的自然科学,需要知识的人文科学和社会科学,以及需要生活常识的中国驾驶规则等。
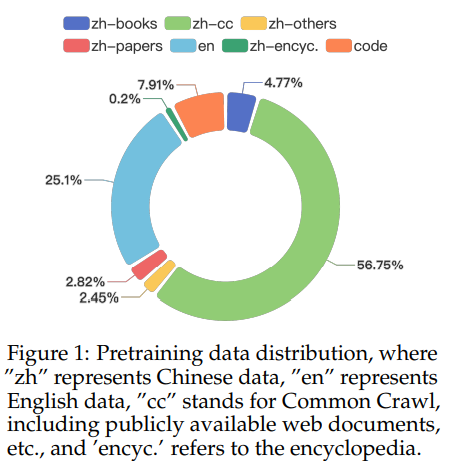
CT-LLM:一个 2B 微小的 LLM
想象一个语言障碍不再成为获取尖端人工智能技术的障碍的世界。这正是 CT-LLM 背后的研究人员通过优先考虑世界上使用最广泛的语言之一的中文来实现的目标。这个 20 亿参数模型不同于主要在英语数据集上训练语言模型,然后将其适应其他语言的传统方法。

Meta公布了其下一代训练和推理加速器(MTIA)的详细信息
它还提供了更高的GEMM和SIMD顶点操作速度,以及更大的本地和片上内存容量和带宽。
此外,Meta还开发了一个大型机架系统,可容纳多达72个加速器,以及一个全新的软件堆栈,与PyTorch 2.0完全集成,支持高效的模型和内核代码生成。

伦敦国防科技黑客马拉松落下帷幕
2024年伦敦国防科技黑客马拉松大赛是一个激发创新、鼓励协作的盛会,由EMC(Edge Matrix Computing)发起。这场黑客马拉松旨在将AI潜力与Web3革命相结合,促进AI和去中心化技术领域的创新。
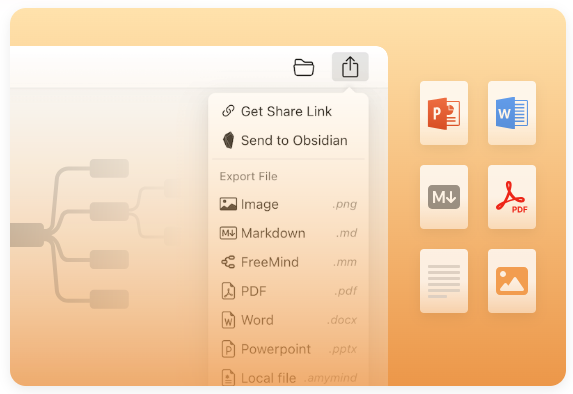
伴你思考的AI思维导图
使用 AI 将文本转换为思维导图。并将markdown、txt、freemind文件转为思维导图,轻松以 PowerPoint、PDF 或 Word 格式导出。轻松编辑并与他人分享您的思维导图。
音乐生成应用Udio正式发布
比Suno有更多的自定义能力,听了一些生成的音乐感觉还是比Suno V3差一些。
前谷歌DeepMind的顶尖AI研究员和工程师创立,并且由艺术家 like @iamwill 和 @common 背书。