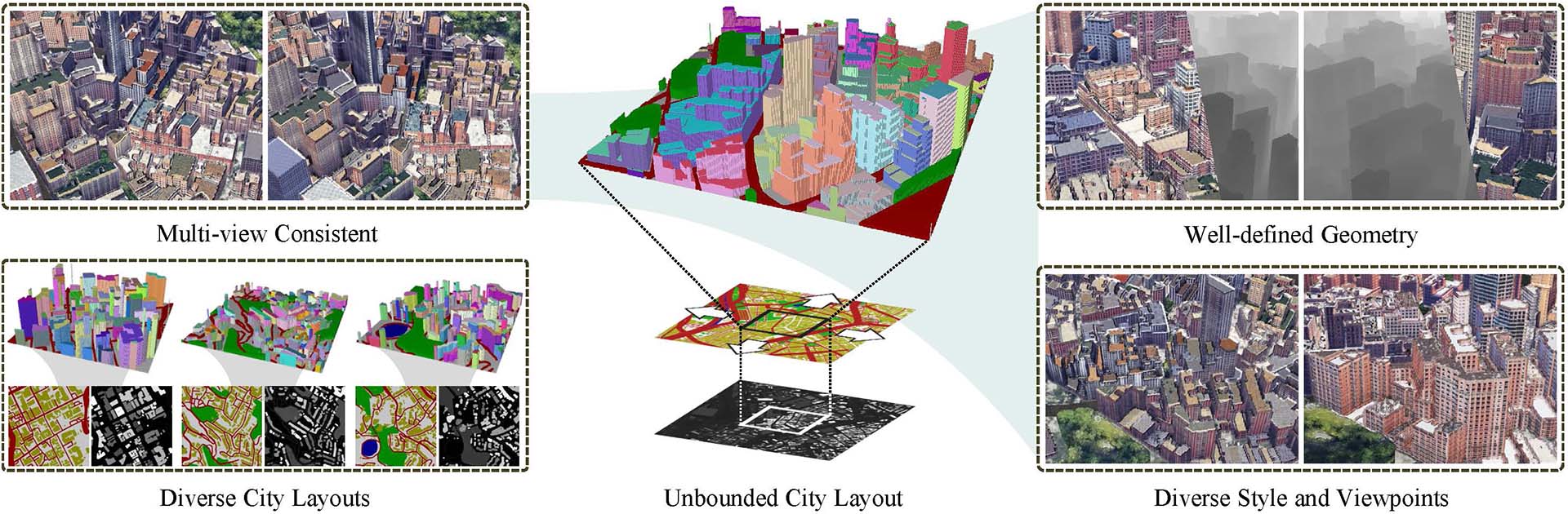
Google DeepMind 展示深度混合:
来自 Google DeepMind、麦吉尔大学和 Mila 的研究人员推出了一种突破性的方法,称为深度混合 (MoD),它不同于传统的统一资源分配模型。 MoD 使 Transformer 能够动态分配计算资源,重点关注序列中最关键的标记。该方法代表了管理计算资源的范式转变,并有望显着提高效率和性能。
来自 Google DeepMind、麦吉尔大学和 Mila 的研究人员推出了一种突破性的方法,称为深度混合 (MoD),它不同于传统的统一资源分配模型。 MoD 使 Transformer 能够动态分配计算资源,重点关注序列中最关键的标记。该方法代表了管理计算资源的范式转变,并有望显着提高效率和性能。
允许模型与外部系统和数据进行交互
使用Tool use (function calling)功能,Claude不仅能够生成文本或回答问题,还能实际调用外部定义的函数或工具来执行特定操作,如获取当前的天气信息、执行数学计算等。
Octopus-V2-2B是由斯坦福大学Nexa AI开发专为Android API的功能调用定制。
采用了一种独特的功能性标记策略,超越了基于RAG的方法,特别适用于边缘计算设备。
比Llama7B + RAG方案快36倍,性能优于 GPT-4,延迟时间小于 1 秒。
WAS26:这个模型是在Banodoco Discord平台分享的艺术作品中挑选出来进行训练的。
Smoooth:专门针对那些动作流畅的视频进行训练。
LiquidAF:这个模型则是在液体模拟的基础上训练的
模型是基于光级数据构建的 Relightable Hands 的高保真通用先验。它概括为新颖的观点、姿势、身份和照明,从而可以通过手机扫描进行快速个性化
可以用来自己进行机器学习
机器人手臂设计为5自由度(DoF)加夹持器,允许它进行广泛的运动,包括旋转、上下举起、弯曲等。
两个这样的手臂还能够折叠衣服。
南洋理工大学的S-lab团队开发了一种新型的动画填色桶彩色化技术。
通过仅需对一帧进行手动彩色化,算法便能自动将颜色传播到后续的所有帧。
哥伦比亚大学的创意机器实验室开发出了一种名为 Emo 的人形机器人头它能够精准恰如其分的模拟面部表情。
Emo装备了26个精密的执行器,可以在 840 毫秒内预测和反映人类的面部表情,包括微笑。
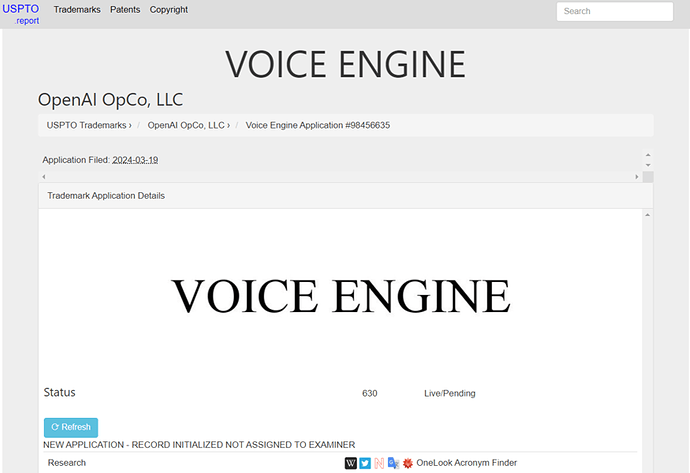
根据文本输入和一个15秒的音频样本,就能生成接近原始说话者声音的自然听起来的语音。
Voice Engine最初于2022年底开发,并已经提供给包括Heygen在内的少数公司进行测试性使用。