AI项目

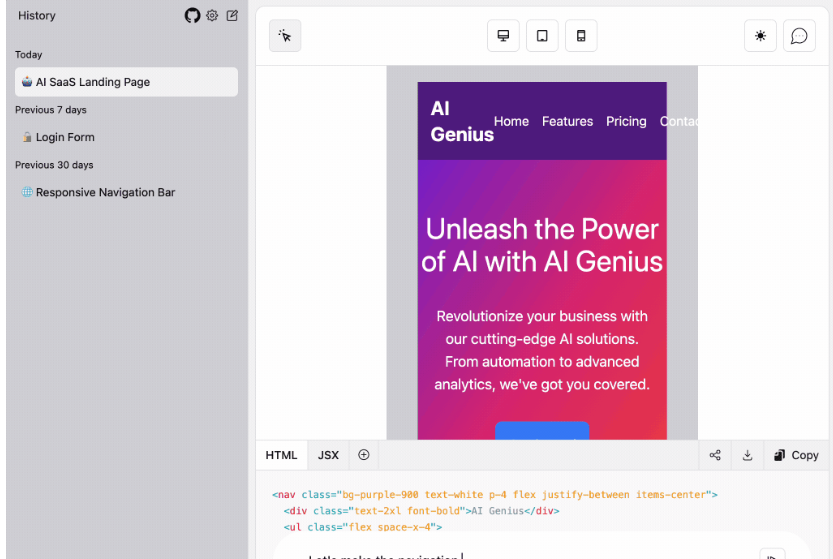
通过聊天的方式来进行UI设计
W&B 团队开发的一个开源工具,你可以通过文字来描述你想要的UI界面,OpenUI可以帮你实时进行渲染出效果。
你还可以通过聊天的方式进行任意修改,并将HTML转换为React、Svelte、Web Components等多种前端框架。

让你的手机“活起来” ,把你的手机变成桌面机器人
Looi采用了仿生行为系统,时刻感知你和你周围的环境。同时接入了ChatGPT,能够通过对话与用户进行互动,可以在手机上显示富有表情的画面。

TextCraftor是一种创新的文本编码器微调技术
为了解决现有模型的局限性,研究者们提出了TextCraftor,这是一种端到端的文本编码器微调技术。TextCraftor的核心思想是通过奖励函数来增强预训练的文本编码器,从而显著提高图像质量和文本图像对齐的准确性。这种方法不需要额外的文本-图像配对数据集,而是仅使用文本提示进行训练,从而减轻了存储和加载大规模图像数据集的负担。

AI21发布世界首个Mamba的生产级模型:Jamba
Jamba代表了在模型设计上的一大创新。这里的”Mamba”指的是一种结构化状态空间模型(Structured State Space Model, SSM),这是一种用于捕捉和处理数据随时间变化的模型,特别适合处理序列数据,如文本或时间序列数据。SSM模型的一个关键优势是其能够高效地处理长序列数据,但它在处理复杂模式和依赖时可能不如其他模型强大。

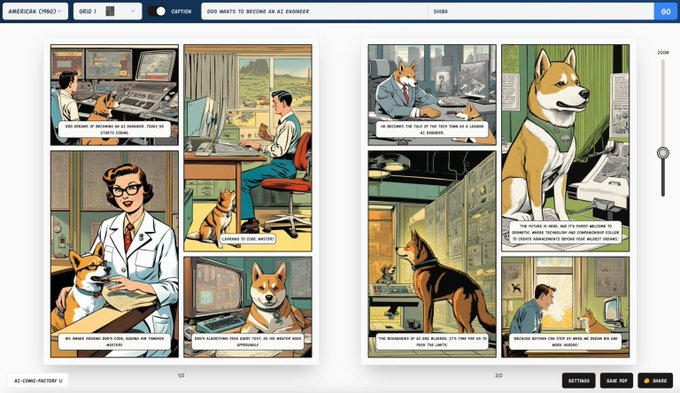
Al Comic Factory:漫画工厂
自动生成有情感、有故事性的漫画内容
它使用大语言模型和如SDXL来自动创建漫画面板。
你只需提供一个简单的文本提示,AI Comic Factory就能根据这个提示生成包含人物对话和场景描述的漫画。

SuperBeasts的ComfyUI真好用
调整阴影、高光和整体 HDR 效果的强度。
应用伽玛校正来控制整体亮度和对比度。
增强对比度和色彩饱和度,以获得更鲜艳的效果。
通过在 LAB 色彩空间中处理图像来保持色彩准确性

LaVague现已作为托管应用程序在huggingface Space上
现在,您可以在不安装任何东西的情况下尝试 LaVague,并根据自然语言指令实现自动化 Web 操作。
这个当中最好的部分?所有堆栈都是开源的!我们使用 Hugging Face #Gradio 作为 UI,他们的 Inference API 调用 #Mixtral 、 @llama_index 用于 #RAG ,LaVague 本身也是开放的-来源。
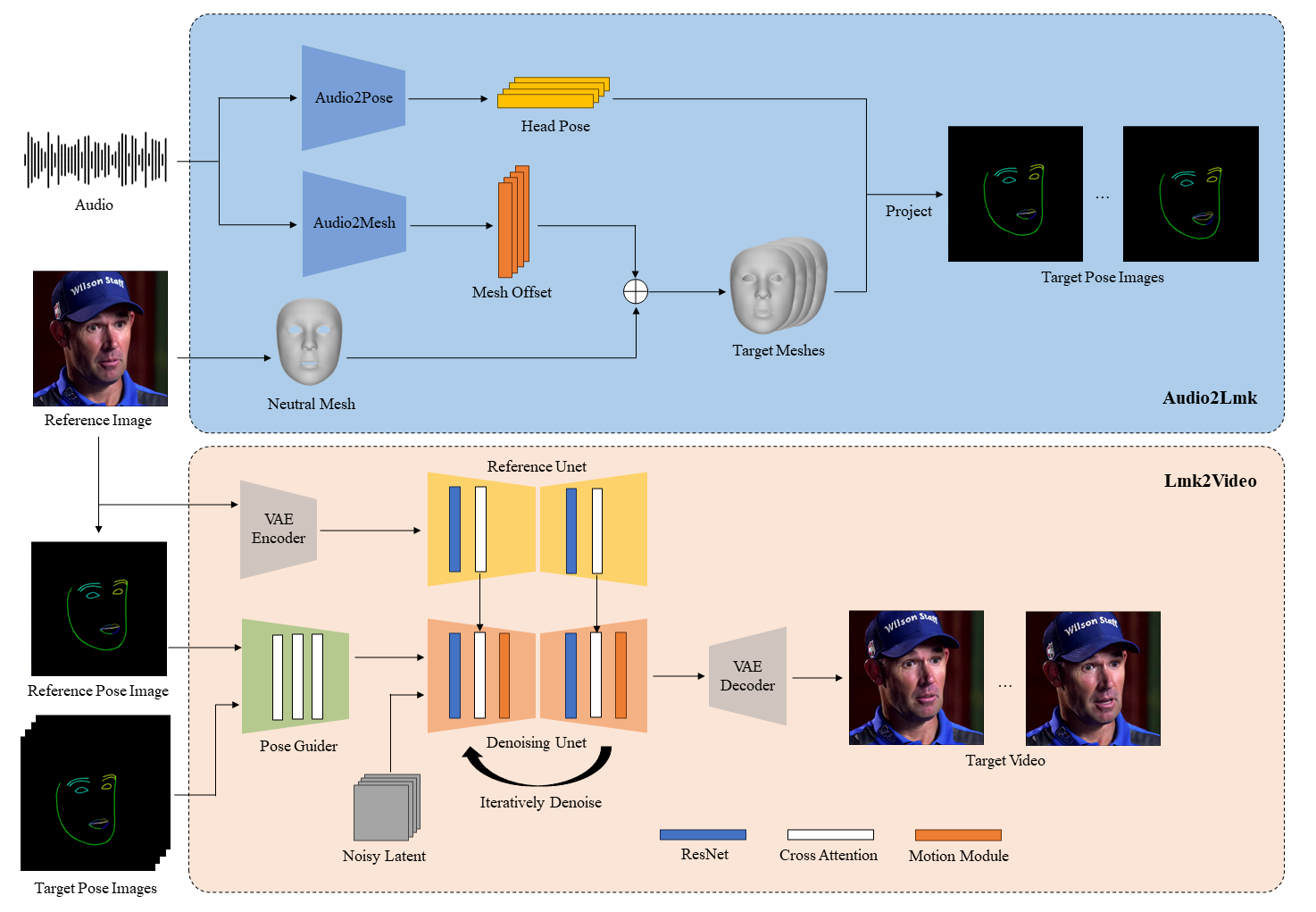
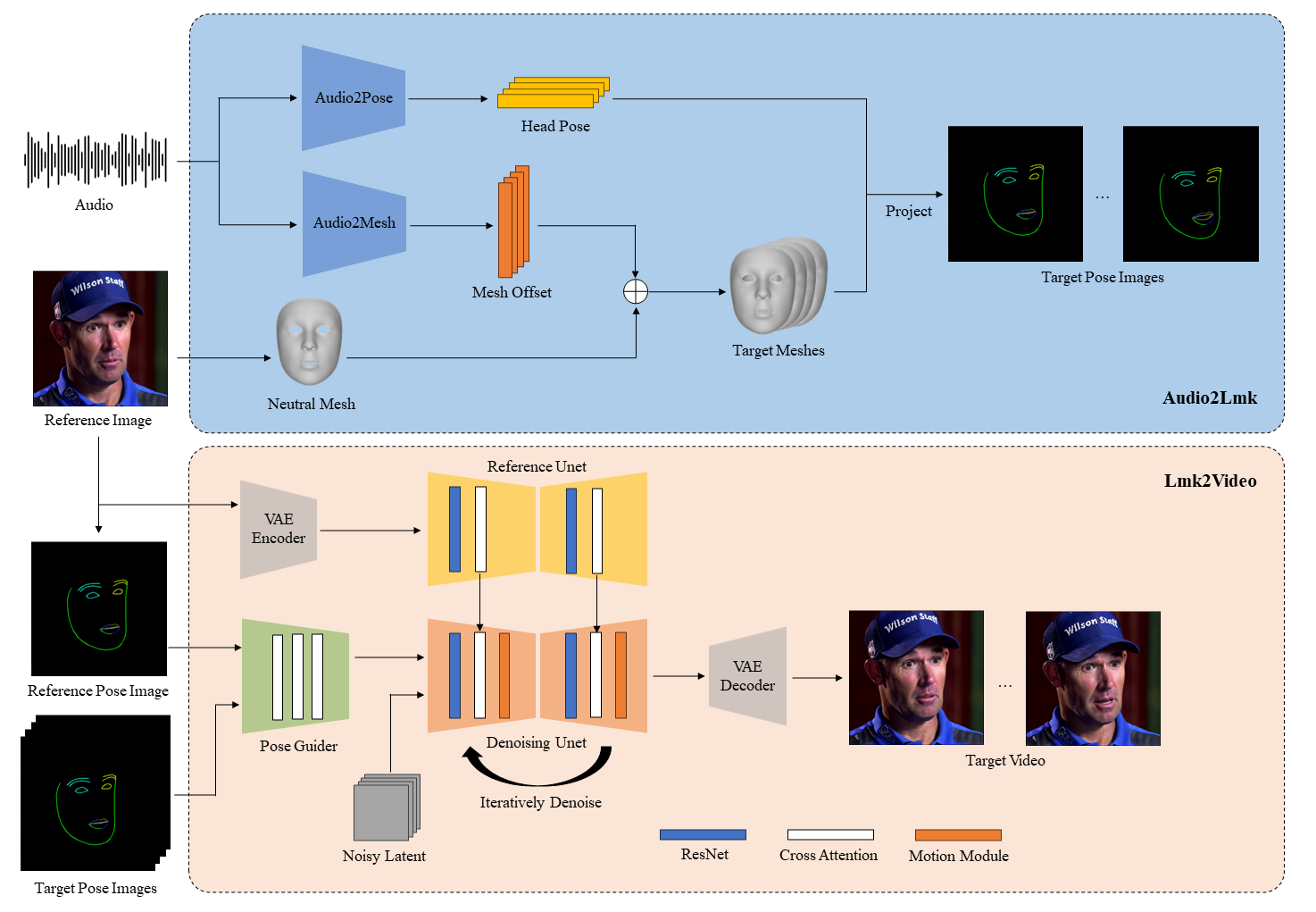
腾讯也搞了一个让照片能唱歌说话的项目
比阿里EMO先开源
AniPortrait:根据音频和图像输入 生成会说话、唱歌的动态视频
它可以根据音频(比如说话声)和一张静态的人脸图片,自动生成逼真的人脸动画,并保持口型一致。
Databricks发布了最强的开源模型DBRX
它在语言理解、编程、数学和逻辑方面轻松击败了开源模型,如 LLaMA2-70B、Mixtral 和 Grok-1。
DBRX 在大多数基准测试中超过了 GPT-3.5。
DBRX 是基于 MegaBlocks 研究和开源项目构建的专家混合模型(MoE),使得该模型在每秒处理的标记数量方面非常快速。

NoLang:输入任何主题或者网页链接直接生成视频
它支持文字、网页链接、PDF、提问等直接转视频
也就是你输入文字、链接NoLang能以视频形式快速回答。
输入PDF文件,会先给你总结内容,然后根据总结的内容在生成一个解答视频。