中国机器人公司LimX Dynamics
中国机器人公司LimX Dynamics展示了双足平衡和导航技术已经发展到了多么高的水平
专为人体模拟而设计的机器人开发商。公司产品主要专注于运动智能和腿式机器人的研发和制造,包括仿人双足和四足机器人及相关解决方案,应用在工业检测、物流配送、特种作业、家居服务等领域,为为客户提供高品质、创新的产品。
中国机器人公司LimX Dynamics展示了双足平衡和导航技术已经发展到了多么高的水平
专为人体模拟而设计的机器人开发商。公司产品主要专注于运动智能和腿式机器人的研发和制造,包括仿人双足和四足机器人及相关解决方案,应用在工业检测、物流配送、特种作业、家居服务等领域,为为客户提供高品质、创新的产品。

Synthesia 是一个基于人工智能的 AI 视频生成制作平台,利用深度学习算法来合成逼真的人脸表情和口型,从而让虚拟的人物能够根据用户输入的文字来说话。用户只需要在网页上输入文字,就可以生成一段专业、有说服力的视频。
Expressive-1能根据文本自动做出皱眉、微笑、皱眉头等表情。

这款模型被视为国内首个达到Sora级别的视频模型。
Vidu 不仅能模拟真实物理世界,还具备丰富的想象力,支持多镜头生成和高时空一致性。
Vidu 模型融合了 Diffusion 与 Transformer 技术,创新性地开发了 U-ViT 架构。
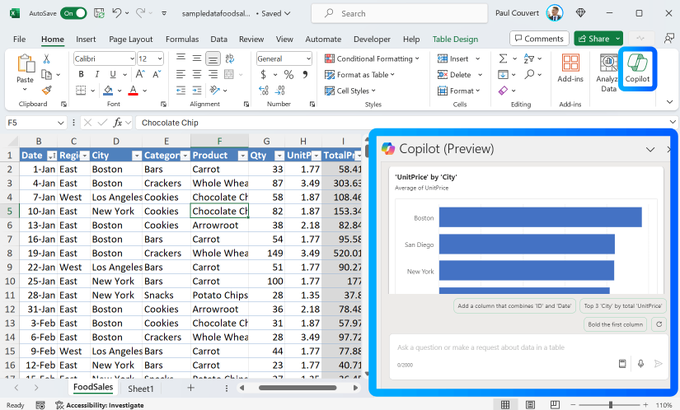
AI快站的特点:
高速下载:提供的模型下载速度相对较快,减少等待时间
模型资源丰富:涵盖大部分常用开源模型,更新速度快
支持断点续传:提供下载器,大模型下载时遇到中断也不再是问题

Amazon Q 不仅可以生成高度准确的代码,还可以进行测试、调试,并具有多步骤规划和推理功能,可以转换和实施根据开发人员请求生成的新代码。 Amazon Q 还通过连接到企业数据存储库以逻辑方式汇总数据、分析趋势,使员工能够更轻松地获得跨业务数据的问题的答案,例如公司政策、产品信息、业务成果、代码库、员工和许多其他主题,并参与有关数据的对话。

Open-Sora
Colossal-AI 团队牵头的项目,目前发布了 1.1 模型,支持 2s~15s,144p 到 720p,任何宽高比文本到图像,文本到视频,图像到视频,视频到视频,无限时间生成的版本。
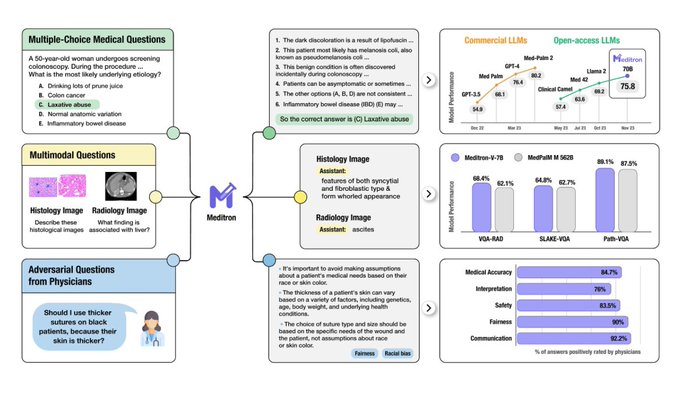
@ICepfl 和 @YaleMed 的研究人员联手构建了 Meditron,这是一款适用于资源匮乏的医疗环境的 LLM 套件。借助 Llama 3,他们的新模型在 MedQA 和 MedMCQA 等基准测试中优于其参数类别中的大多数开放模型。
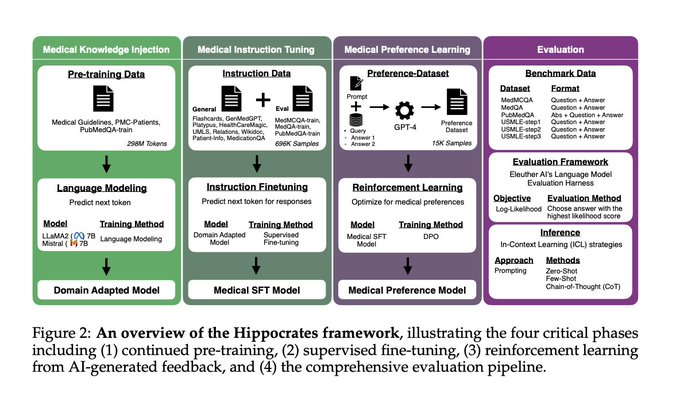
Koç 大学、Hacettepe 大学、Yıldız Technical University 和 Robert College 的研究人员推出了“Hippocrates”,这是一个专为 LLMs 医疗保健应用量身定制的开源框架。与依赖专有数据的先前模型不同,希波克拉底授予对其广泛资源的完全访问权限,从而促进医疗人工智能研究领域的更大创新和协作。该框架的突出之处在于将持续的预训练和强化学习与人类专家的反馈相结合,增强了模型在医疗环境中的实用性。
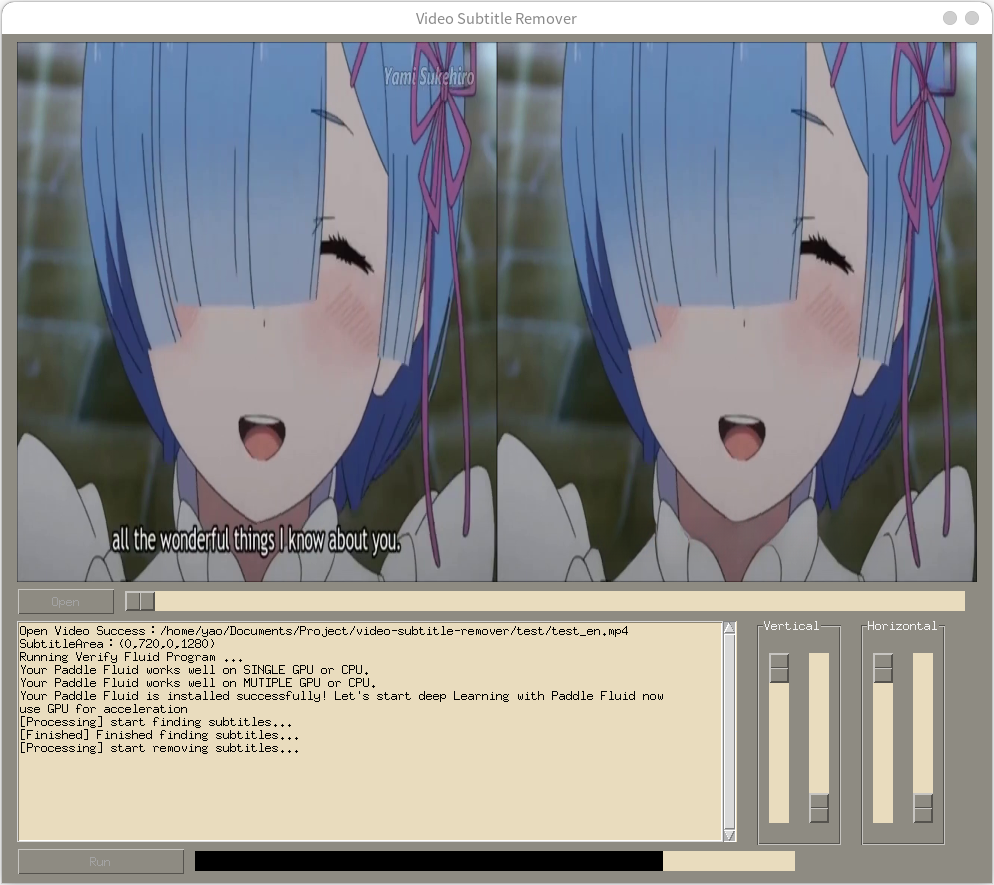
Video-subtitle-remover (VSR) 是一款基于AI技术,将视频中的硬字幕去除的软件。 主要实现了以下功能:
无损分辨率将视频中的硬字幕去除,生成去除字幕后的文件
通过超强AI算法模型,对去除字幕文本的区域进行填充(非相邻像素填充与马赛克去除)
支持自定义字幕位置,仅去除定义位置中的字幕(传入位置)

在临床推理、多模态理解和长文本处理方面都有很大的提升。
研究人员用了14个医疗基准测试Med-Gemini的能力。
结果发现,它在10个基准上都取得了最佳表现,远超之前最强的GPT-4模型。
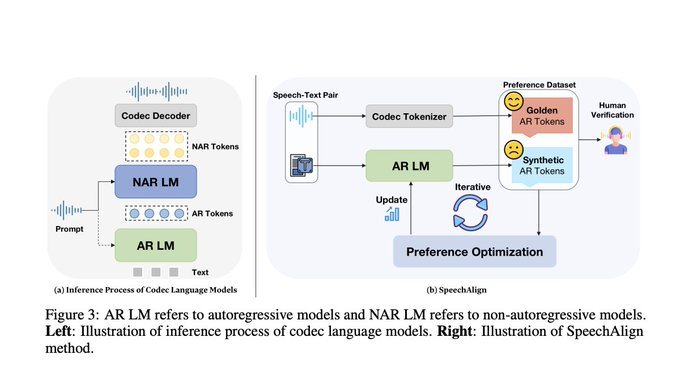
复旦大学的一个研究团队开发了 SpeechAlign,这是一个针对语音合成核心的创新框架,使生成的语音与人类偏好保持一致。与优先考虑技术准确性的传统模型不同,SpeechAlign 通过直接将人类反馈纳入语音生成而引入了巨大转变。这个反馈循环确保产生的语音在技术上是合理的并且在人类层面上产生共鸣。