Creatie这个AI-UI设计工具
有点强啊,做的相当完整,基本上可以当做一个加上了 AI 功能的 FIgma。
而且全部都是免费的,AI 能力也很强,选择区域输入需求直接就会展示对应备选的组件,你可以自己拼装和修改,还能使用自己的设计系统。
有点强啊,做的相当完整,基本上可以当做一个加上了 AI 功能的 FIgma。
而且全部都是免费的,AI 能力也很强,选择区域输入需求直接就会展示对应备选的组件,你可以自己拼装和修改,还能使用自己的设计系统。
这些条件 GAN 能够采用文本到图像模型(例如 SD-Turbo),通过一步(A100 上为 0.11 秒,A6000 上为 0.29 秒)进行配对和不配对图像转换。尝试我们的代码和 @Gradio 演示。
包括完整的文本到视频模型训练过程、数据处理、训练细节和模型检查点。
该项目由@YangYou1991 团队开发 这是 OpenAI Sora 在视频生成方面的开源替代方案。
可以在仅仅3天的训练后生成2~5秒的512×512视频。
Openrouter提供了一个统一的接口,通过这个接口,你可以直接访问和使用几十种AI模型
你可以使用这个接口对各种模型进行测试和比价,选择最适合自己的,避免了东奔西跑
通过结合解剖学精确的模型、物理模拟器和基于真实果蝇行为训练的人工智能模型
@HHMIJanelia 和 @GoogleDeepMind
的科学家创造了一种计算机化昆虫,它能够像真实果蝇一样,在复杂的轨迹上行走和飞行。
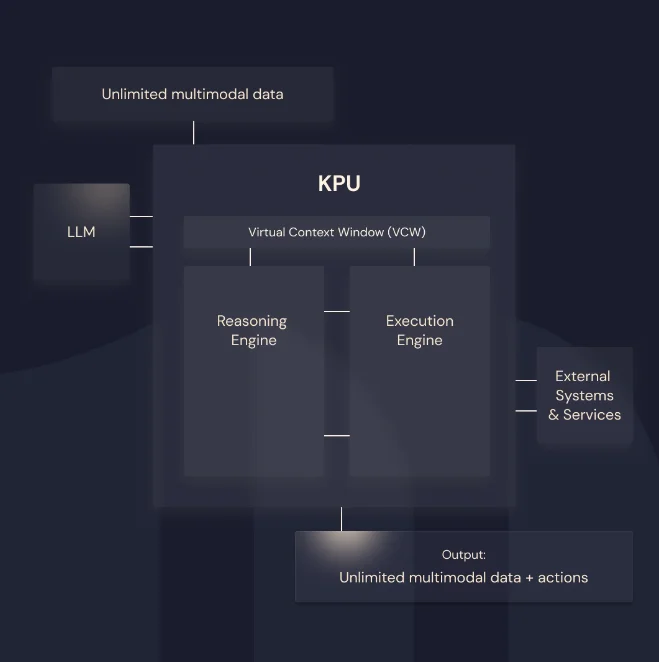
通过将推理与数据处理分开,优化和提升了大语言模型处理复杂任务的能力。
使用KPU后,在多个基准测试和推理任务中GPT-4 、Claude 3 Opus等模型等能力得到大幅提升,都超越了没有使用KPU的原模型本身!
Google也弄了一个:一张照片+音频即可生成会说话唱歌的视频的项目
VLOGGER:基于文本和音频驱动,从单张照片生成会说话的人类视频
成本大约 $3,600,可以用来记录真人手指的动作来训练机器人进行灵活的操作。
并且不是遥控操作,它有一对特制的手套,通过各种传感器捕捉手部运动的精确数据。与传统基于视觉的运动捕捉技术相比,这些手套不会因为视线遮挡而失效,更适合在日常活动中使用。
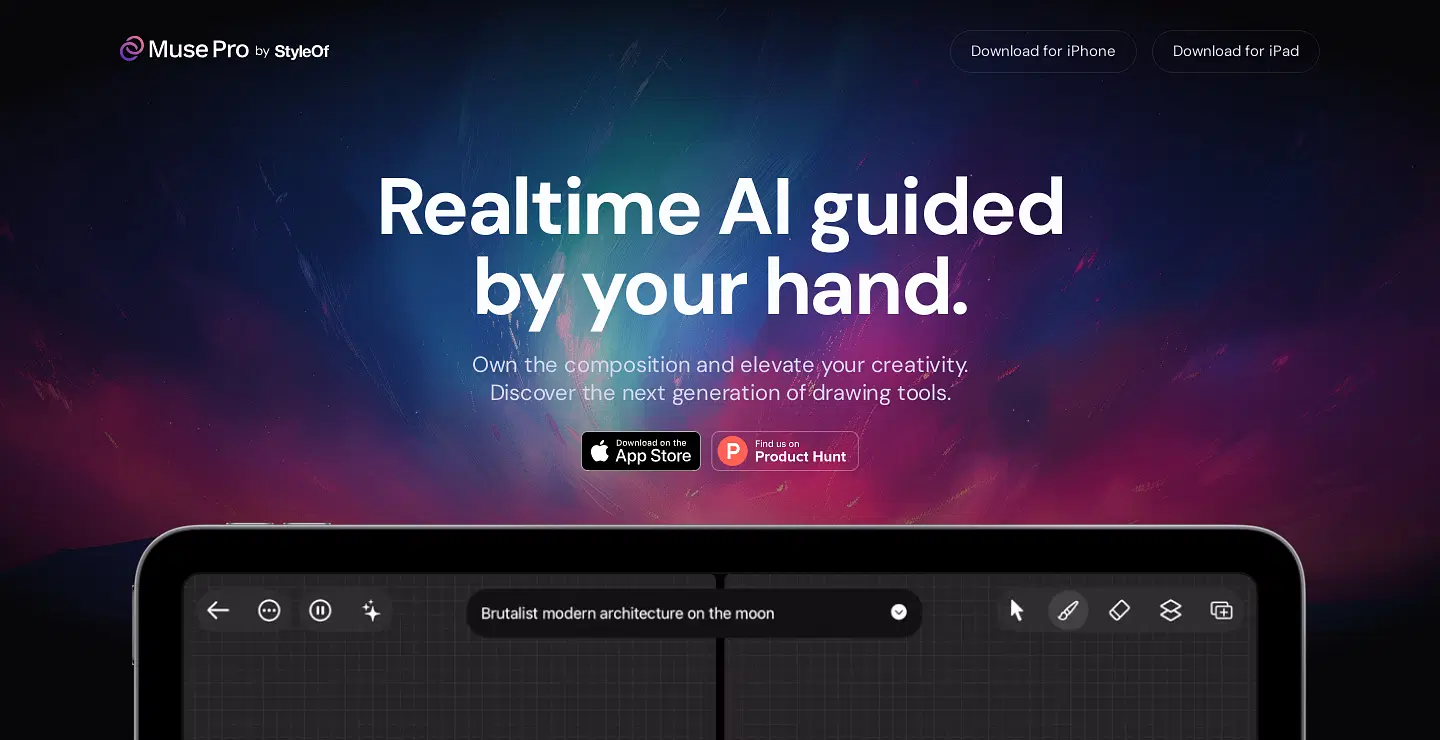
与其他画笔快速生成图片的尴尬应用不同,Musepro这个iPad 应用看起来是真的可用。借助 iPad 搭配的 Apple Pencil以及内置的丰富笔刷,应该可以极大的提高画图效率。
通过提供一个将自然语言查询转化为 Selenium 代码的引擎,LaVague 可让用户或其他人工智能轻松实现自动化,轻松表达网络工作流程并在浏览器上执行。
Human to Humanoid (H2O)由卡内基梅隆大学的研究团队开发,它允许人们通过一个简单的RGB摄像头让机器人实时模仿人的全部动作。
在你输入的指令后面加上 –cref URL,URL是你选择的角色图像的链接。
你还可以用 –cw 来调整参照的“强度”,范围从100到0。
默认的强度是100 (–cw 100),这时会参考人物的脸部、发型和衣着。
如果设置为强度0 (–cw 0),那么系统只会关注脸部(这对于更换服饰或发型很有帮助)。
能够通过文字提示创造出适用于各种场景的声音和音效
如游戏中的射击和跳跃声音、动画中的雨声环境以及视频中的地铁到站声音等。