Stability AI 的 Stable Video官网正式上线
支持上传图片和文字提示生成视频
从官网提供的演示视频来看,质量非常高,是Runway的强有力竞争者。
支持通过相机运动来控制视频的生成过程。
支持上传图片和文字提示生成视频
从官网提供的演示视频来看,质量非常高,是Runway的强有力竞争者。
支持通过相机运动来控制视频的生成过程。
OpenAI在2019年8月份就推出了他们的一音乐生成模型:Jukebox
Jukebox能够根据提供的歌词、艺术家和流派信息生成多种流派和艺术家风格的完整音乐和人声歌曲。
最牛P的是,3年前的质量就已经这样了…
而且据说Jukebox 2即将发布
通过连接大语言模型与多模态适配器和扩散解码器,AnyGPT实现了对各种模态输入的理解和能够在任意模态中生成输出的能力。
也就是可以处理任何组合的模态输入(如文本、图像、视频、音频),并生成任何模态的输出…
实现了真正的多模态通信能力。
这个项目之前叫NExT-GPT
可以根据不同性别和体型自动调整,和模特非常贴合。也可以根据自己的需求和偏好调整试穿效果
OOTDiffusion支持半身模型和全身模型两种模式。
将运行在 Groq 上的 Llama-70B 模型与 Whisper 模型结合,实现了几乎零延迟的性能。
如果在GPT 4或者未来更高版本GPT 5能实现这速度,想象空间很大,几乎秒级就能写一本书出来,AI实时通话都不是问题!
能自动从视频中识别和分离出不同的声音源,并与画面位置匹配。
例如,它可以识别出视频中哪个人物正在说话或哪个乐器正在被演奏。
而且还能够分别提取和分离这些声音源的声音。
PixelPlayer能自我学习分析,无需人工标注数据。
这种能力为音视频编辑、多媒体内容制作、增强现实应用等领域提供了强大的工具,使得例如独立调整视频中不同声音源音量、去除或增强特定声音源等操作成为可能。
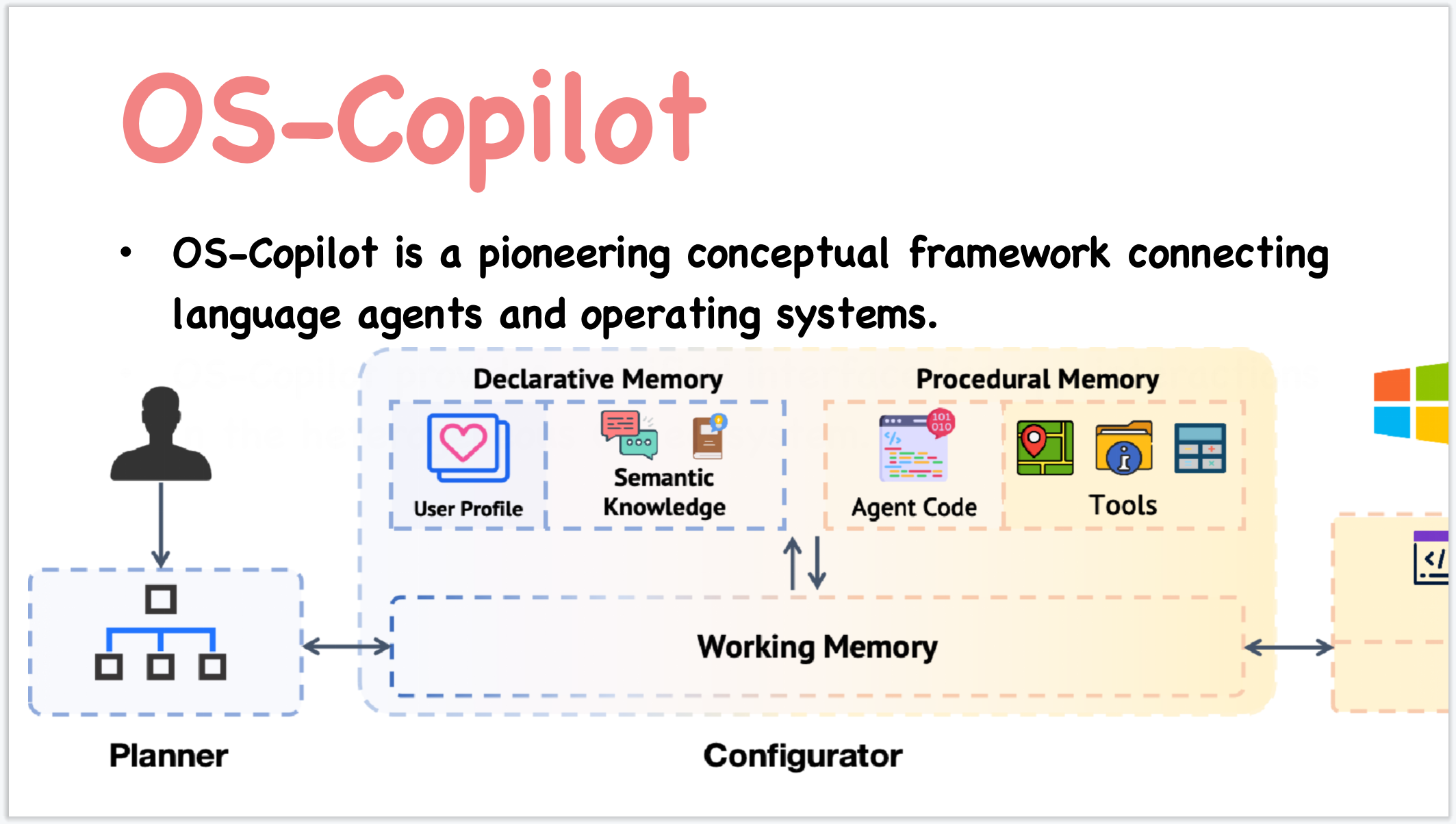
它可以通过理解用户的自然语言指令和屏幕的视觉内容,自动执行一系列复杂的任务。
比如“删除Word文档中的所有图片”或“在PowerPoint文稿中添加一个新幻灯片”。
它结合了GPT 4-V,能够理解和Windows应用程序的图形用户界面(GUI)并执行操作。
UFO能够在Windows应用程序中执行各种操作,如点击按钮、填写表单、浏览文件等,就好像一个人在使用鼠标和键盘操作电脑一样。
嵌入式软件平台是基础架构供应商,与专门的内部资源相比,它能让公司更快、更好、更轻松地启动多产品战略
来源:@Base10Partners
这是其 AI 模型的下一个版本,具有超过 1,000,000 个令牌上下文长度。
该模型现在可以一次性理解整本书、整部电影和播客系列。
这远远超过了所有其他竞争对手的聊天机器人上下文窗口。
OpenAI 的使命是确保全人类能从人工通用智能 (AGI) 中受益,这不仅意味着我们要构建既安全又有益的 AGI,也意味着我们要努力创造广泛分布的利益。现在,我们将分享我们如何实现这个使命的理解,以及我们与 Elon 的关系的一些事实。我们打算驳回 Elon 的所有主张
Sora 是一个数据驱动的物理引擎。它是对许多世界的模拟,无论是真实的还是幻想的。模拟器通过一些去噪和梯度数学来学习复杂的渲染、“直观”物理、长期推理和语义基础。
如果 Sora 使用虚幻引擎 5 对大量合成数据进行训练,我不会感到惊讶。它必须如此!
该机器人只需要1.5厘米的小切口来进行腹部手术,这比一枚硬币还小,大大减少了手术对患者身体的伤害和术后恢复时间。
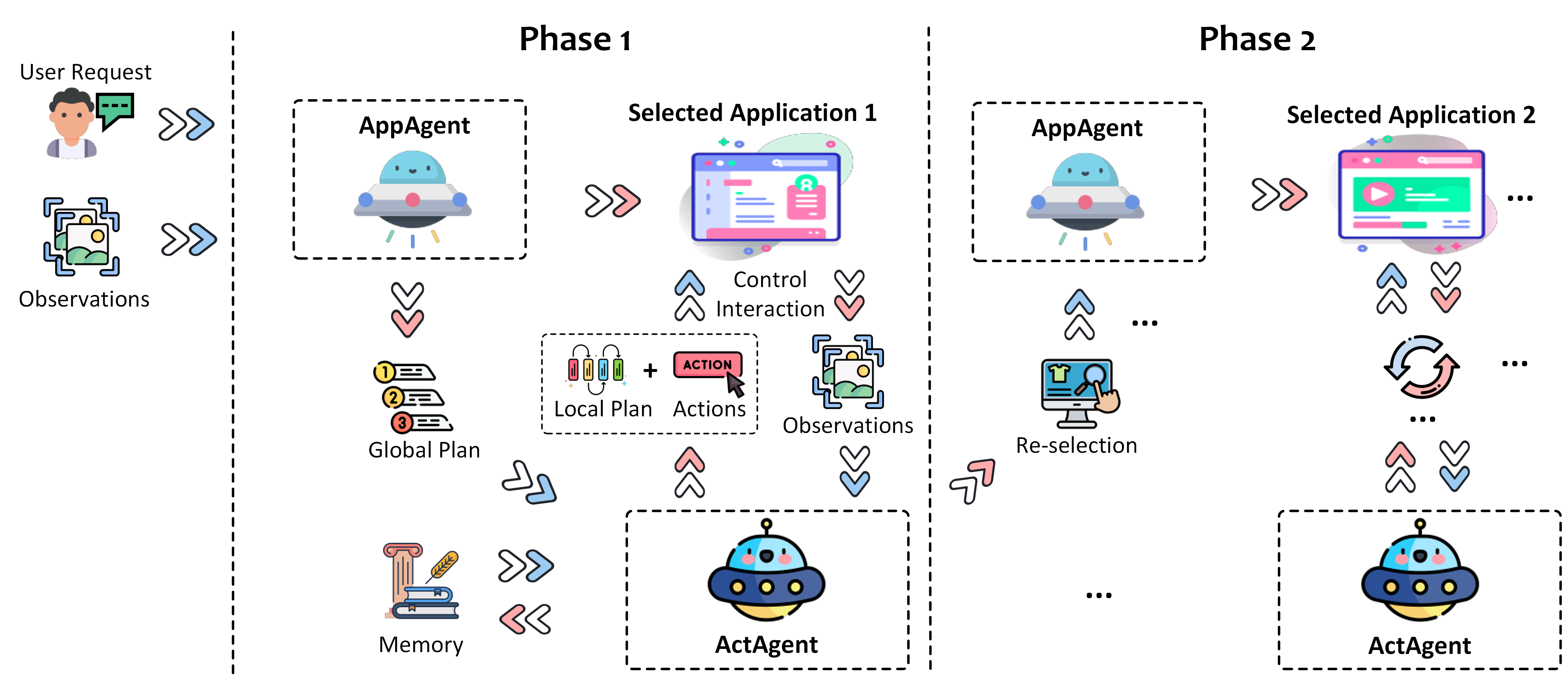
完成一系列广泛且复杂的计算机任务的智能代理框架。
它能够自我学习和改进,处理各种操作系统级别的任务。
包括但不限于文件管理、数据处理、环境设置、多媒体操作、网页浏览、代码编写、第三方应用交互、自动化测试等。
该项目由上海AI实验室、华东师范大学、普林斯顿大学和香港大学的研究人员共同开发。