有意思的项目:EMAGE
可以为输入的音频生成与之同步的面部和身体动作,速度很快,效果很不错!

哥伦比亚大学的创意机器实验室开发出了一种名为 Emo 的人形机器人头它能够精准恰如其分的模拟面部表情。
Emo装备了26个精密的执行器,可以在 840 毫秒内预测和反映人类的面部表情,包括微笑。
根据文本输入和一个15秒的音频样本,就能生成接近原始说话者声音的自然听起来的语音。
Voice Engine最初于2022年底开发,并已经提供给包括Heygen在内的少数公司进行测试性使用。
Mac 可以通过 Private LLM 运行更大模型(32k 令牌长度窗口),无需 Nvidia RTX,无需 GPU。
将 AI 添加到你的工作流程变得更简单!无需代码,只需你的创造力和 Apple 快捷指令即可进行提示工程。
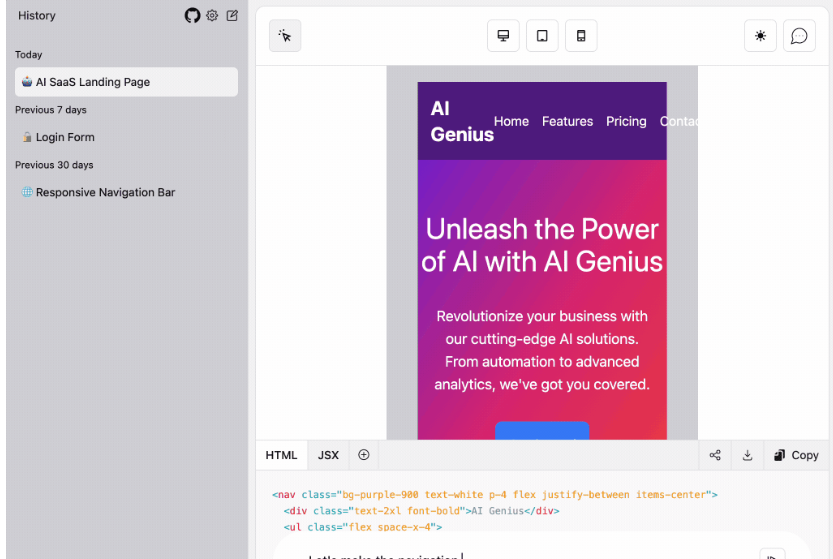
W&B 团队开发的一个开源工具,你可以通过文字来描述你想要的UI界面,OpenUI可以帮你实时进行渲染出效果。
你还可以通过聊天的方式进行任意修改,并将HTML转换为React、Svelte、Web Components等多种前端框架。

为了解决现有模型的局限性,研究者们提出了TextCraftor,这是一种端到端的文本编码器微调技术。TextCraftor的核心思想是通过奖励函数来增强预训练的文本编码器,从而显著提高图像质量和文本图像对齐的准确性。这种方法不需要额外的文本-图像配对数据集,而是仅使用文本提示进行训练,从而减轻了存储和加载大规模图像数据集的负担。

Jamba代表了在模型设计上的一大创新。这里的”Mamba”指的是一种结构化状态空间模型(Structured State Space Model, SSM),这是一种用于捕捉和处理数据随时间变化的模型,特别适合处理序列数据,如文本或时间序列数据。SSM模型的一个关键优势是其能够高效地处理长序列数据,但它在处理复杂模式和依赖时可能不如其他模型强大。