谷歌在Chrome中允许用户输入“@”来启动 Gemini
谷歌在 Chrome 中集成了一项新功能,允许用户输入“@”来启动 Gemini。
新的人工智能工具几乎没有学习曲线
立即改进产品并利用现有分销
慢慢提高非人工智能用户的技能
谷歌在 Chrome 中集成了一项新功能,允许用户输入“@”来启动 Gemini。
新的人工智能工具几乎没有学习曲线
立即改进产品并利用现有分销
慢慢提高非人工智能用户的技能
支持图像视频等多种视觉语言任务
包括支持图像和短视频字幕、视觉问答、图像文本理解、物体检测文件图表解读、图像分割等任务。
PaliGemma 模型包含 30 亿(3B)个参数,结合了 SigLiP 视觉编码器和 Gemma 语言模型。
Android Studio提供了一站式解决方案,集成了代码编辑、编译、调试和测试的工具,减少了开发者在不同工具间切换的需要。
支持自动编写代码、语法高亮和代码重构
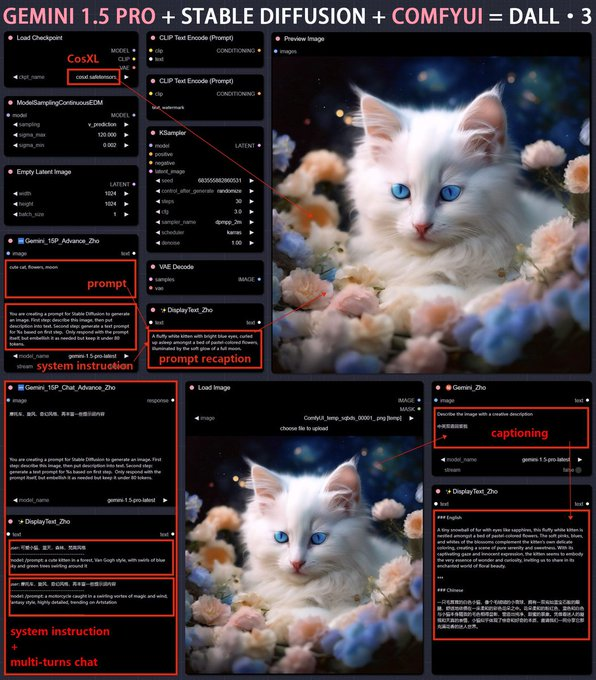
开源社区一直以来的梦想:DALLE3交互和提示词生成能力 + 无数SD模型出图能力,这不巧了嘛
百万上下文、多模态+多轮对话、打标/反推
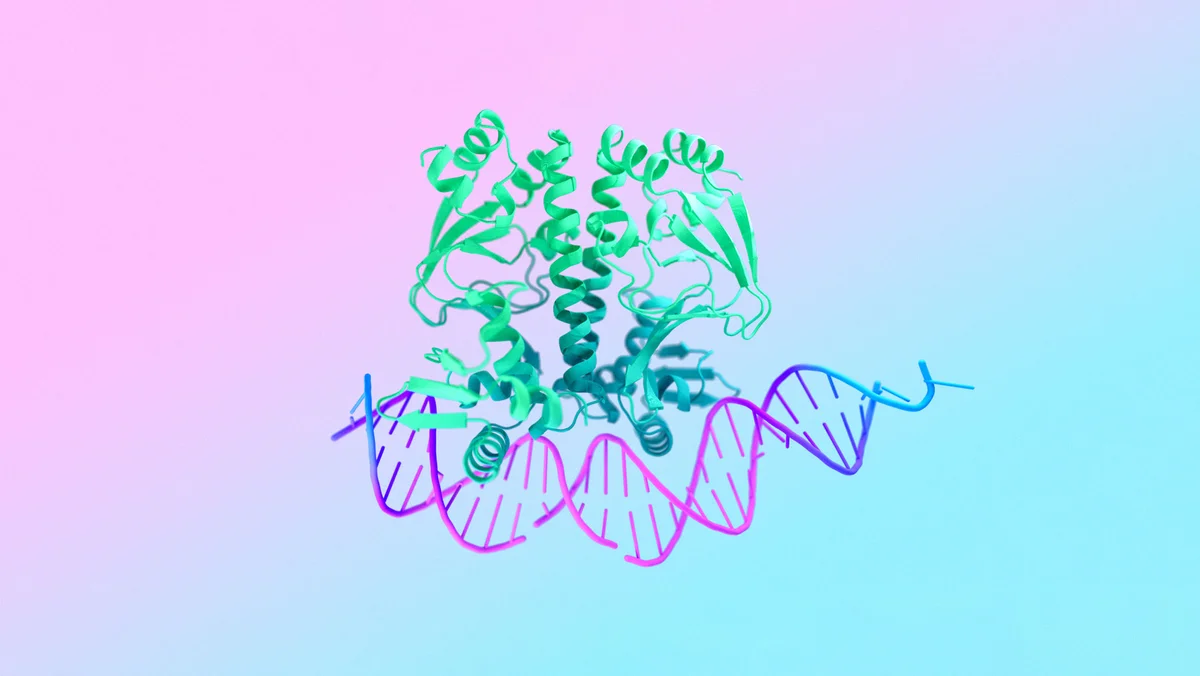
能够预测所有生命分子结构和相互作用 AI 模型
该模型能够生成蛋白质、DNA 和其他分子的 3D 结构,并揭示它们如何组合在一起。
该模型还能够模拟影响细胞健康的化学变化,并检测可能导致疾病的异常。
AlphaFold 3 将为全球科学研究人员和机构免费开放。它的高精度和新一代架构可支持药物发现和生物学的突破性进展。
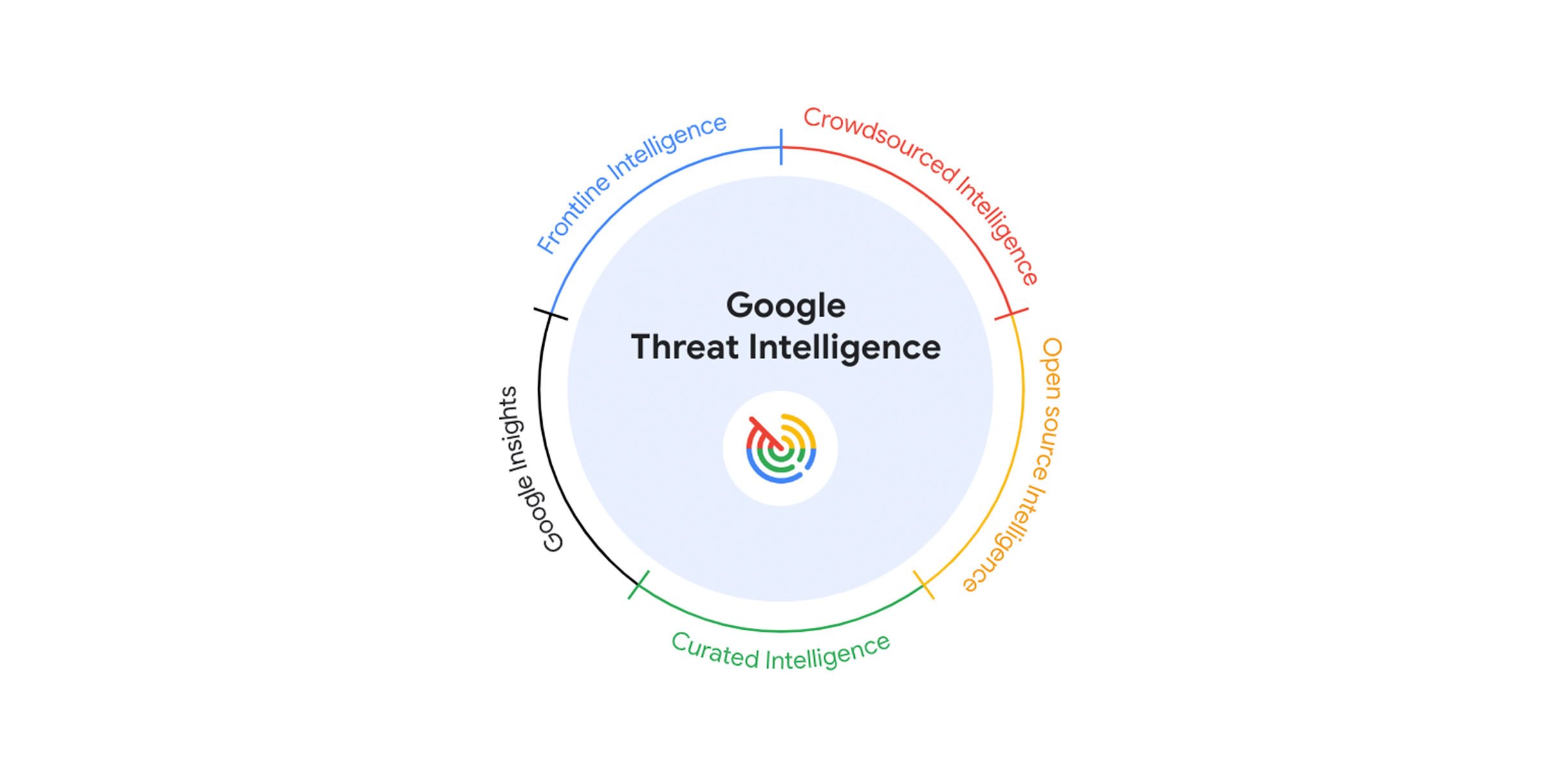
Google 威胁情报的用途示例:
识别和防御网络钓鱼攻击:
假设一家企业遭遇了钓鱼电子邮件攻击,员工可能收到包含恶意链接或附件的电子邮件。
Google Threat Intelligence可以利用其庞大的电子邮件监控网络,检测并阻止这些恶意邮件的传播。
在临床推理、多模态理解和长文本处理方面都有很大的提升。
研究人员用了14个医疗基准测试Med-Gemini的能力。
结果发现,它在10个基准上都取得了最佳表现,远超之前最强的GPT-4模型。
CodeGemma:专注于代码完成和代码生成任务,具备出色的数学和逻辑推理能力
RecurrentGemma:是一个为研究实验优化的高效架构,利用循环神经网络和局部注意力来提高内存效率。
Gemini 1.5 Pro能够对上传到Google AI Studio中的视频进行图像(帧)和音频(语音)的同时推理,意味着这个模型具备了理解和处理视频内容的能力,不仅限于视频的视觉部分(如图像帧),也包括音频部分(如对话、背景音乐等)。
来自 Google DeepMind、麦吉尔大学和 Mila 的研究人员推出了一种突破性的方法,称为深度混合 (MoD),它不同于传统的统一资源分配模型。 MoD 使 Transformer 能够动态分配计算资源,重点关注序列中最关键的标记。该方法代表了管理计算资源的范式转变,并有望显着提高效率和性能。
Google 官方Gemini API提供的指南和示例集合
帮助开发者更好地理解和使用Gemini API,包括如何构建应用程序、编写提示以及利用API的不同特性。
这是其 AI 模型的下一个版本,具有超过 1,000,000 个令牌上下文长度。
该模型现在可以一次性理解整本书、整部电影和播客系列。
这远远超过了所有其他竞争对手的聊天机器人上下文窗口。
注册时可以选择退出训练数据
Gemini Ultra 中 Imagen 2 生成的所有图像都应用了数字水印(但你看不到它)
Ultra 比 Gemini Pro 更能胜任复杂任务,例如编码、逻辑推理以及遵循更长/更详细的指令。
Google的Gemini Ultra模型将在2月7号上线,同时Google聊天机器人Bard将更名为Gemini。
Gemini将开启付费计划:Gemini Advanced
谷歌在Bard谷歌地图和Imagen-2升级,亚马逊推出了人工智能购物助手“Rufus”
此外,亚马逊、Sam Altman、佐治亚理工学院、Meta、Arc 和 Anthropic 在人工智能方面取得了巨大进展。
将其与 Google Sheets 结合起来,实现数据处理的自动化。
向您展示如何使用 Bard 来管理没有公式的电子表格: