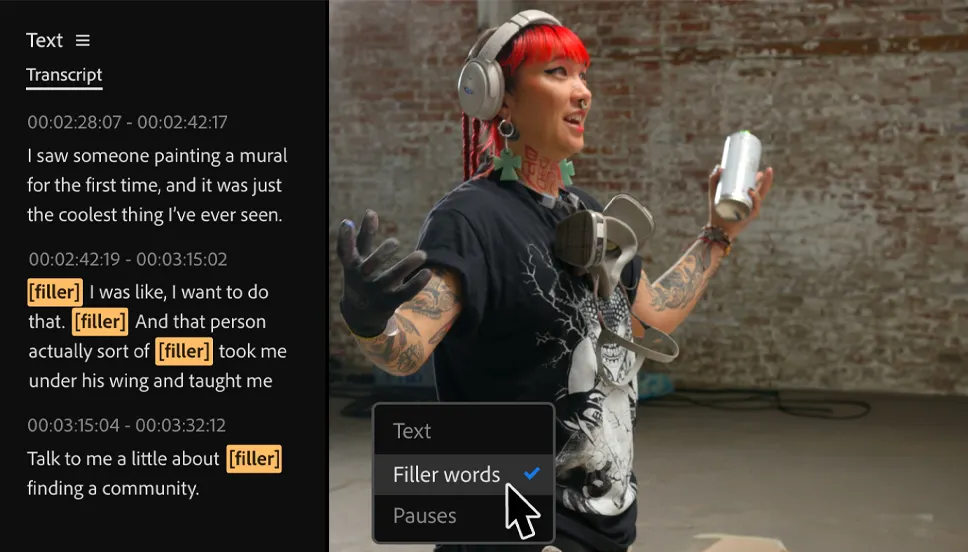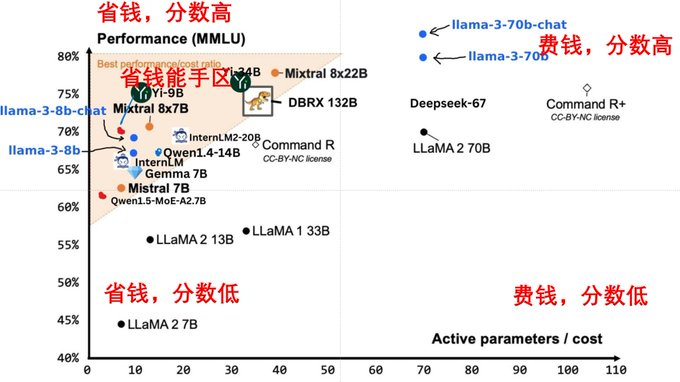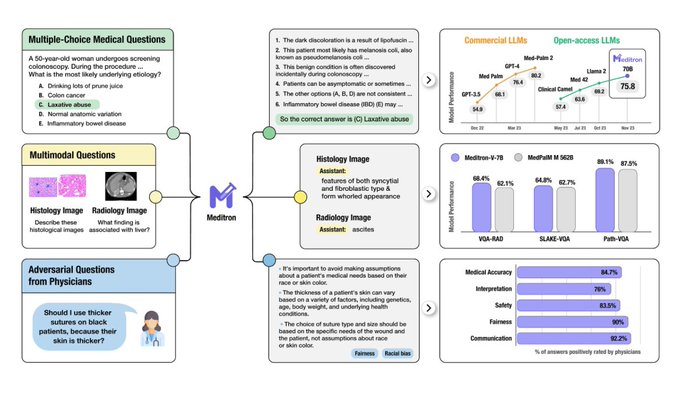
基于LLAMA3构建的医疗领域的多模态模型
@ICepfl 和 @YaleMed 的研究人员联手构建了 Meditron,这是一款适用于资源匮乏的医疗环境的 LLM 套件。借助 Llama 3,他们的新模型在 MedQA 和 MedMCQA 等基准测试中优于其参数类别中的大多数开放模型。
@ICepfl 和 @YaleMed 的研究人员联手构建了 Meditron,这是一款适用于资源匮乏的医疗环境的 LLM 套件。借助 Llama 3,他们的新模型在 MedQA 和 MedMCQA 等基准测试中优于其参数类别中的大多数开放模型。
在临床推理、多模态理解和长文本处理方面都有很大的提升。
研究人员用了14个医疗基准测试Med-Gemini的能力。
结果发现,它在10个基准上都取得了最佳表现,远超之前最强的GPT-4模型。
引入 AI 视频编辑和第三方Sora等AI视频模型
Adobe Premiere Pro将在今年晚些时候推出第三方AI模型,让编辑人员可以选择最适合他们素材的模型,直接在软件中生成和编辑。
它还提供了更高的GEMM和SIMD顶点操作速度,以及更大的本地和片上内存容量和带宽。
此外,Meta还开发了一个大型机架系统,可容纳多达72个加速器,以及一个全新的软件堆栈,与PyTorch 2.0完全集成,支持高效的模型和内核代码生成。
gpt-4-turbo 、 gpt-4 和 gpt-3.5-turbo 指向各自的最新模型版本。您可以通过发送请求后查看响应对象来验证这一点。响应将包括所使用的特定模型版本(例如 gpt-3.5-turbo-0613 )。
CodeGemma:专注于代码完成和代码生成任务,具备出色的数学和逻辑推理能力
RecurrentGemma:是一个为研究实验优化的高效架构,利用循环神经网络和局部注意力来提高内存效率。
Gemini 1.5 Pro能够对上传到Google AI Studio中的视频进行图像(帧)和音频(语音)的同时推理,意味着这个模型具备了理解和处理视频内容的能力,不仅限于视频的视觉部分(如图像帧),也包括音频部分(如对话、背景音乐等)。
来自 Google DeepMind、麦吉尔大学和 Mila 的研究人员推出了一种突破性的方法,称为深度混合 (MoD),它不同于传统的统一资源分配模型。 MoD 使 Transformer 能够动态分配计算资源,重点关注序列中最关键的标记。该方法代表了管理计算资源的范式转变,并有望显着提高效率和性能。
允许模型与外部系统和数据进行交互
使用Tool use (function calling)功能,Claude不仅能够生成文本或回答问题,还能实际调用外部定义的函数或工具来执行特定操作,如获取当前的天气信息、执行数学计算等。
模型是基于光级数据构建的 Relightable Hands 的高保真通用先验。它概括为新颖的观点、姿势、身份和照明,从而可以通过手机扫描进行快速个性化
Alexander Reben 这十年来致力于创作艺术作品,这些作品探讨了人工智能(AI)中人性的幽默与荒谬。
他通过手工将 AI 生成的图像转换成三维模型,并将这些模型具象化于现实世界中,创造出一系列雕塑作品。
Google 官方Gemini API提供的指南和示例集合
帮助开发者更好地理解和使用Gemini API,包括如何构建应用程序、编写提示以及利用API的不同特性。