研究發現,不相關的經驗可以增強記憶力
學習和記憶的形成是透過赫布模型來解釋的,該模型表明大腦中的突觸透過神經元的重複同時活化而得到加強。這意味著當兩個神經元被反覆激活時,它們之間的聯繫就會變得更強——我們稱之為「突觸可塑性」。根據赫布規則(「神經元一起放電,連接在一起」),這個過程是嚴格特定於輸入的,並且取決於兩個神經元同時激活。
然而,DANDRITE Sadegh Nabavi 實驗室的新研究表明,學習和記憶並不是那麼簡單。
學習和記憶的形成是透過赫布模型來解釋的,該模型表明大腦中的突觸透過神經元的重複同時活化而得到加強。這意味著當兩個神經元被反覆激活時,它們之間的聯繫就會變得更強——我們稱之為「突觸可塑性」。根據赫布規則(「神經元一起放電,連接在一起」),這個過程是嚴格特定於輸入的,並且取決於兩個神經元同時激活。
然而,DANDRITE Sadegh Nabavi 實驗室的新研究表明,學習和記憶並不是那麼簡單。
蘋果週四告訴開發者,蘋果將允許歐盟的 iPhone 和 iPad 用戶刪除 App Store 或其 Safari 瀏覽器。
蘋果長期以來一直大力保護應用程式商店,將其作為數位內容進入其流行行動裝置的唯一門戶。這項變化發生之際,由於歐盟具有里程碑意義的新數位規則,該公司放鬆了對歐盟設備的控制。
蘋果在開發者支援頁面上表示:“歐盟用戶將可以刪除 App Store、訊息、相機、照片和 Safari 應用程式。”
新加坡的目標是到 2030 年達到碳排放峰值,到 2050 年達到淨零排放,但它嚴重依賴進口石油和天然氣。
該市缺乏生產風能或水力發電的條件,雖然目標是到 2030 年利用當地安裝的太陽能發電 2 吉瓦,但沒有足夠的空間建造大型太陽能發電場。
同時,需求只會增加,特別是來自資料中心的需求,資料中心已經佔新加坡電力消耗的 7%。
研究人員在過去 30 年裡取得了長足的進步,但科學家尚未建造出足夠強大的量子電腦來運行 Shor 的演算法。
當一些研究人員致力於建造更大的量子電腦時,其他研究人員一直在嘗試改進 Shor 的演算法,以便它可以在更小的量子電路上運行。大約一年前,紐約大學電腦科學家 Oded Regev 提出了一項重大理論改進。他的演算法可以運行得更快,但電路需要更多的記憶體。
今天發表在《自然遺傳》上的研究結果標誌著透過將具有特定突變的患者與最有希望的候選藥物相匹配來幫助個人化治療邁出了重要的一步。該預測模型是一種名為 RTDetective 的公開資源,可加速許多不同類型的遺傳性疾病和癌症的臨床試驗的設計、開發和有效性。
截短的蛋白質是蛋白質合成突然停止的結果。在我們的身體中,這是由「無意義突變」的出現引起的,這些突變就像停車標誌或路障,導致細胞機器突然煞車。在許多情況下,這些未完成的蛋白質會停止工作並導致疾病。
一个在线插图工具,帮助作者、教育工作者和创意家长快速为儿童书籍创建插图。
可以使用先进的生成式AI模型,如Imagen、Stable Diffusion、DALL-E等,轻松地在几分钟内完成插图工作。
插图作品可以导出到各种媒体,如印刷书籍、电子书、YouTube等,且所有图像都可商用,无需支付版权费用。
擁有一台功能如此強大的相機,它可以拍攝移動電子的定格照片——一個移動速度如此之快的物體,可以在一秒鐘內繞地球許多圈。亞利桑那大學的研究人員開發了世界上最快的電子顯微鏡,可以做到這一點。
他們相信他們的工作將帶來物理、化學、生物工程、材料科學等領域的突破性進步。
由於一種被稱為無意識選擇性注意的怪癖,你的大腦已經學會了忽略你的鼻子。鼻子是靠近眼睛的突出特徵,它可能會妨礙我們的視力,但神經系統會巧妙地將其過濾掉。
不過,您可以選擇尋找您的鼻子。無論是閉上一隻眼睛,還是向左、向右或向下看,它就會突然出現。
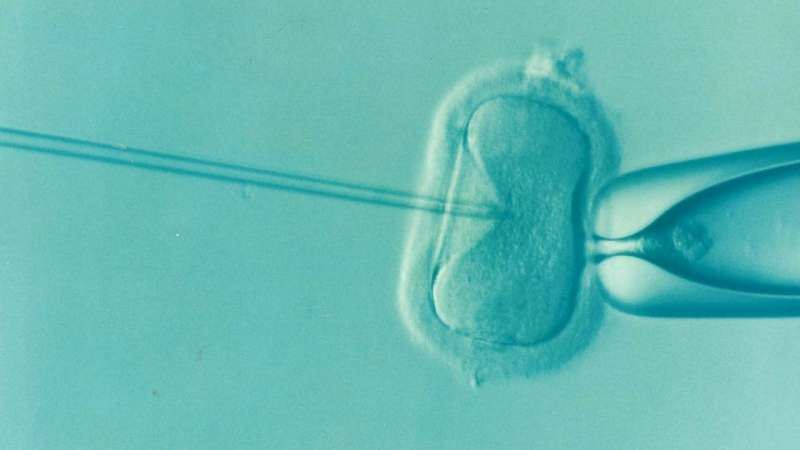
在體外受精 (IVF) 過程中,卵子和精子會產生許多不同的胚胎。然後,胚胎學家選擇最有可能成功懷孕的胚胎並將其移植給患者。
胚胎學家透過利用他們的專業知識,根據胚胎的外觀應用一套廣泛接受的原則來做出這種選擇。近年來,人們對在此過程中使用各種人工智慧(AI)技術產生了濃厚的興趣。
iPhone摄影奖(IPPA)公布了今年的获奖作品,展示了主要使用智能手机拍摄的令人惊叹的图像。值得注意的是,年度摄影师奖颁发给了使用iPhone 11的艺术家,突出了在人工智能生成图像占主导地位的时代,移动摄影的强大功能。获奖照片既是灵感来源,也是手机摄影爱好者的潜在壁纸。
正念呼吸補充了傳統的疼痛緩解方法,並擴大了癌症患者的選擇範圍。
研究人員表示,由於腫瘤壓迫或侵入周圍組織、神經病理機制以及治療的副作用,全球估計有 30-40% 的癌症患者患有中度至重度疼痛。
他們補充說,儘管疼痛管理方面取得了進步,並且藥物和神經阻斷的範圍不斷發展,但疼痛控制不足仍然是臨床醫生面臨的重大挑戰。
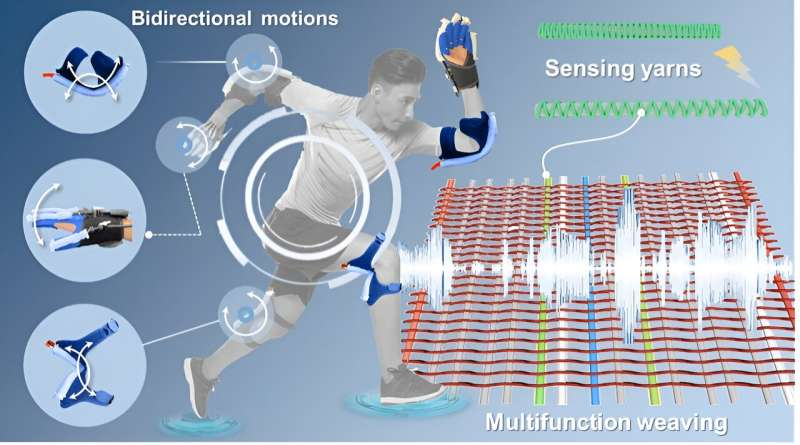
江南大學的研究人員最近推出了一種新的紡織工程方法,用於製造用於醫療保健技術和機器人系統的編織和軟執行器。他們提出的製造策略在《細胞報告物理科學》的一篇論文中概述,既可擴展又易於設計,這可能有助於其未來的大規模採用。
谷歌将AI驱动的搜索摘要扩展到六个新国家
谷歌现在在搜索页面顶部显示基于人工智能的便捷答案,这意味着用户可能永远不会点击进入那些为这些结果提供数据的网站。
但许多网站所有者表示,他们无法承受阻止谷歌人工智能总结他们的内容的后果。