MindSearch 是一个开源的 AI 搜索引擎框架
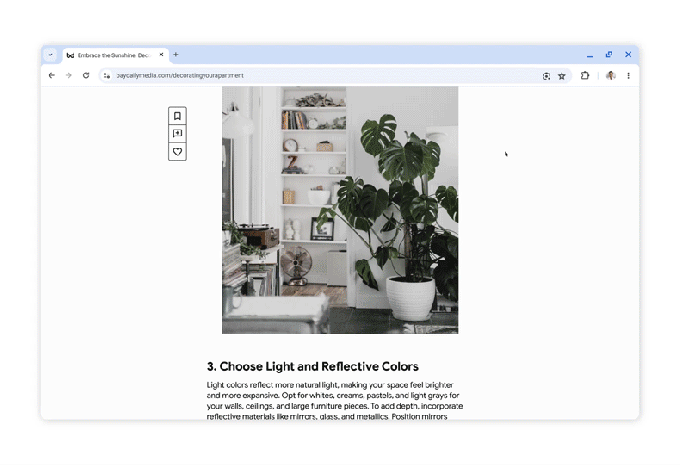
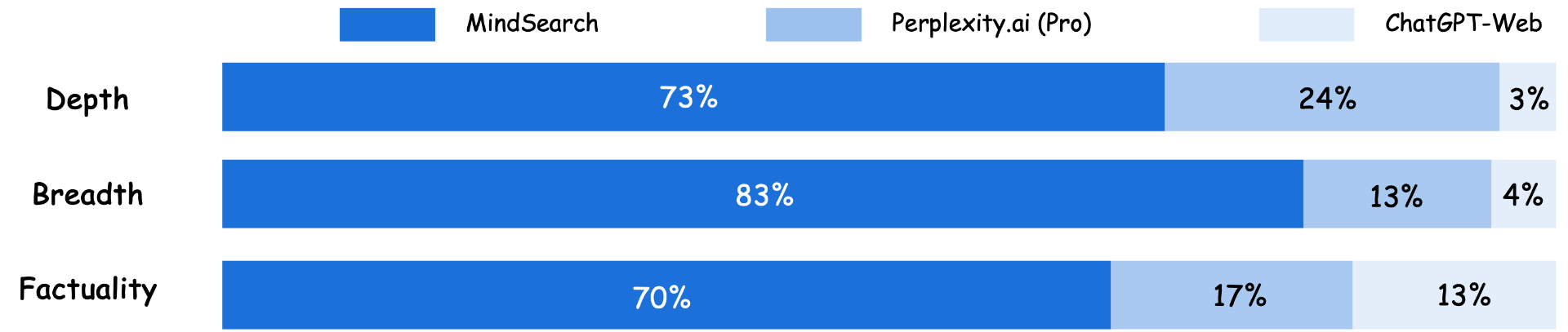
MindSearch是由上海人工智能实验室开发的一个基于大语言模型(LLM)和搜索引擎相结合的系统,旨在模仿人类在网络上寻找和整合信息的过程。性能可与 Perplexity.ai Pro 相媲美,能够处理超过 300 个网页的长上下文信息。而且是开源的,你可以轻松用它部署来构建您自己的搜索引擎。
MindSearch是由上海人工智能实验室开发的一个基于大语言模型(LLM)和搜索引擎相结合的系统,旨在模仿人类在网络上寻找和整合信息的过程。性能可与 Perplexity.ai Pro 相媲美,能够处理超过 300 个网页的长上下文信息。而且是开源的,你可以轻松用它部署来构建您自己的搜索引擎。
初创公司 Rapidus 计划于 2024 年 4 月开始其最先进芯片的试生产,标志着其重振半导体产业的努力迈出了关键一步。这个雄心勃勃的项目源于 2020 年 IBM 的一通电话,IBM 寻求合作伙伴来大规模生产其 2 纳米芯片。
尽管日本的芯片产业落后,但 IBM 选择了日本,因为其对日本芯片工具和材料供应链的信任度很高,以及 Rapidus 与 Imec 等国际研究机构的合作关系。
Google Lens 现已可用于 Chrome 桌面浏览器,用户可以通过快速拖动和搜索手势搜索浏览器屏幕上看到的内容。“标签比较”功能可让用户跨站点比较商品,网上购物时,来回切换标签页对比商品价格与评论很麻烦,该功能可在一处显示人工智能生成的多个标签页中的产品概览。
一个开源项目,旨在代理Midjourney的Discord频道,通过API形式调用AI绘图,提供免费的绘图接口。
支持多账号配置,每个账号可设置任务队列,并提供不同的生成速度模式(RELAX、FAST、TURBO)
谷歌发布了三款新的“开放式”生成式人工智能模型,并称这些模型比大多数模型“更安全”、“更小巧”、“更透明”。这是谷歌 Gemma 2 生成模型系列的新成员,该系列于5月份首次亮相。新模型 Gemma 2 2B、ShieldGemma 和 Gemma Scope 的设计针对略有不同的应用和用例,但都具有安全性的共同点。
Gemma 2 2B 是一个用于生成分析文本的轻量级模型,可在笔记本电脑和边缘设备等多种硬件上运行。至于 ShieldGemma,是一组“安全分类器”,旨在检测仇恨言论、骚扰和色情内容等有害信息。最后,Gemma Scope 允许开发人员“放大” Gemma 2 模型内的特定点,使其内部运作更易于解释。
研究发现,在产品描述中使用术语 AI 会降低消费者的购买意愿。研究人员调查了逾千名美国成年人,发现在产品描述中提及 AI 会削弱情感信任,降低购买意愿。例如,参与者查看了与智能电视相关的描述,一组的描述中有 AI,另一组没有,结果看到产品描述含有 AI 的一组人表示他们不太可能购买这款电视机。对于高风险的产品和服务如医疗设备和金融服务,术语 AI 会激起更加强烈的负面反应。
市场营销学临床助理教授、该研究的主要作者梅苏特·西塞克 (Mesut Cicek)表示,研究结果一致表明,被描述为使用人工智能的产品不太受欢迎。
好莱坞最近的劳工合同重点关注了 AI 的影响,演员和编剧获得了保护,但其他工匠面临着不同的现实。例如,图片编辑担心 AI 可能自动化他们三分之一的工作,这可能会降低他们每年 125,000 美元至 200,000 美元的薪水。
虽然美国舞台员工国际联盟 (IATSE) 工会已经协商了一些 AI 条款,包括定期与制片厂会面,但许多成员认为这些条款还不够。然而,工会领导层认为,完全禁止 AI 不切实际,可能会导致制作转移到海外。
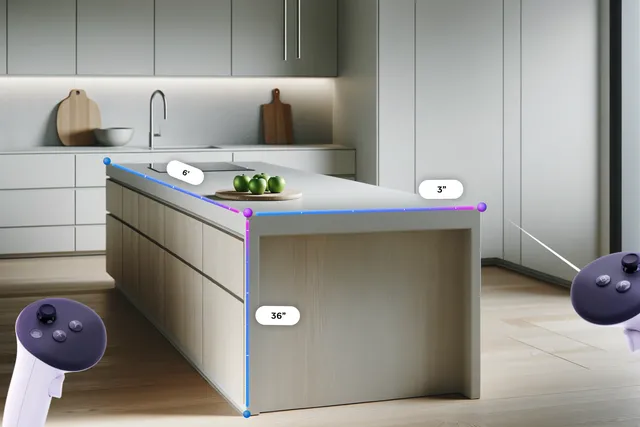
Meta 的 Quest 3 头显即将迎来一款名为 Layout 的新应用,允许用户测量空间、可视化家具摆放,甚至调整图片水平。该应用是 v68 更新的一部分,允许用户虚拟放置电视等物体,以查看它们是否合适。
Canva 已收购澳大利亚 AI 初创公司 Leonardo.ai,获得了其文本转图像和文本转视频生成器的访问权限。此举加强了 Canva 在生成式 AI 市场的地位,有可能挑战 Adobe 的主导地位。
Leonardo.ai 的技术将被整合到 Canva 的 Magic Studio 产品中,而其平台将保持独立运营。此次收购正值 Canva 寻求扩展其创意套件并与 Adobe 的 Firefly 模型竞争之际。然而,Canva 面临对其数据训练实践的审查,需要应对围绕生成式 AI 的伦理问题。
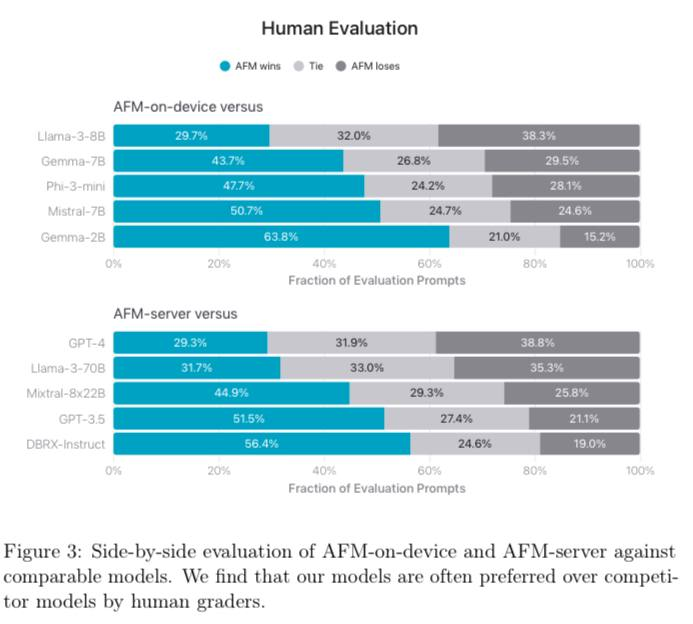
Apple大模型的报告也已出炉,披露了大量技术细节。报告显示,在指令遵循、文本总结等任务上,苹果云端大模型取得了超过 GPT-4 的成绩。
苹果进行了 IFEval 测试,结果在指令和 prompt 两个层次上,云侧 AFM 都超过了 GPT-4,成为了新的 SOTA。端侧模型的表现,也超过了 Llama 3-8B、Mistral-7B 等近似规模的模型。在 AlpacaEval 当中,端侧和云侧 AFM 也都取得了第二名的成绩。
苹果透露,其新的人工智能模型训练使用了谷歌的张量处理单元 (TPU),而不是英伟达的 GPU。这一决定意义重大,因为英伟达在 AI 芯片市场占据主导地位,份额高达 80%。
苹果在其 iPhone AI 模型中部署了 2048 个 TPUv5p 芯片,在其服务器 AI 模型中部署了 8192 个 TPUv4 处理器。
这是一个让你能够一键同时向多个AI提问的完全免费浏览器插件。
目前支持了新标签页打开和新窗口打开两种模式,
还在开发浏览器侧边栏,能够让你在新标签页打开时垂直查看打开的多个标签页,估计下周能发布。
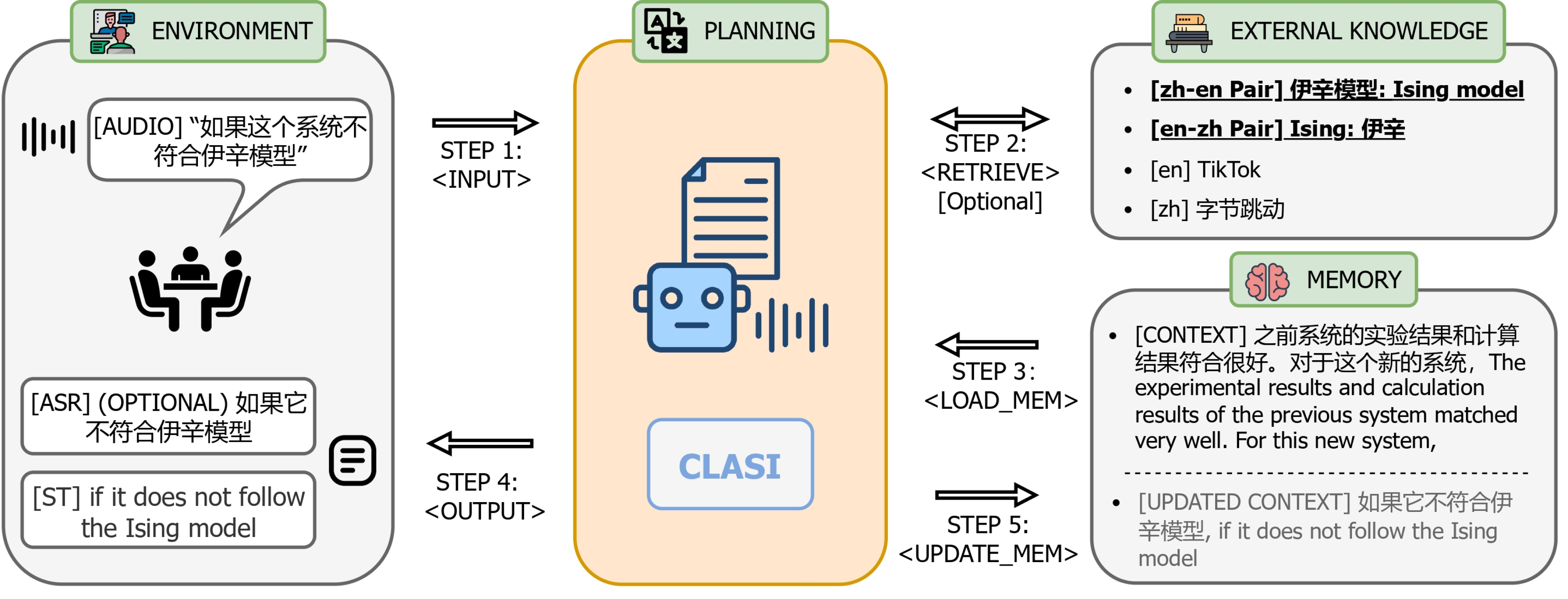
CLASI是由字节跳动开发的一个高质量的同时语音翻译系统,类似于专业的人类译员。它能实时翻译语音内容,保持高翻译质量和低延迟。CLASI利用先进的数据策略和多模态检索技术来处理复杂的术语和不清晰的语音信息。
CLASI会根据当前的音频内容,结合外部知识库和历史上下文,生成准确且容错的翻译。它在各种测试数据集上的表现都非常出色,能够传达更多有效信息。
谷歌的人工智能系统AlphaProof和AlphaGeometry 2取得了突破性成就,成功解决了2024年国际数学奥林匹克(IMO)中的六个问题中的四个,获得了相当于银牌的分数。这是首次有人工智能系统在这一享有盛誉的比赛中达到如此高水平的表现。
AlphaProof是一种强化学习系统,解决了两个代数问题和一个数论问题,包括本次比赛中最具挑战性的题目。AlphaGeometry 2是其前身的改进版本,解决了几何问题。这些人工智能系统总共获得28分,在每个解决的问题上都得到了满分。
Vozo Rewrite & Redub 是一款创新的视频编辑工具,你可以通过简单的提示重写视频脚本、然后这个工具会自动给视频重新配音、翻译语音并口型同步,然后生成新的视频。
无论是将经典视频转变为病毒视频宣传片,还是将普通视频变成喜剧,亦或是将一种语言翻译成多种语言,Vozo 都能在几秒钟内完成。
大部分新功能需要订阅标准版才可以用,目前的定价是 10 美元/月
AI 说唱生成器是一款尖端工具,利用先进的人工智能来创作独特的说唱歌曲。无论您是经验丰富的艺术家还是只是想享受乐趣,我们的人工智能说唱生成器都提供了一种无缝的方式来制作个性化的说唱音乐。您可以输入自己的歌词、选择乐器并选择音乐风格,以根据您的喜好精确定制您的说唱歌曲。