
DETECT-2B :音频深度伪造检测工具
etect-2B的子模型由带有关键层插入适配模块的冻结音频表示模型组成。这些适配模块专注于识别真实音频与伪造音频的细微差别——即录音中不经意留下的声音痕迹。大多数AI生成的音频片段听起来都“过于完美”。Detect-2B能够预测音频中AI制作的成分,而且无需每次听到新片段时都重新训练模型。这些子模型也经过了大型数据集的充分训练。
etect-2B的子模型由带有关键层插入适配模块的冻结音频表示模型组成。这些适配模块专注于识别真实音频与伪造音频的细微差别——即录音中不经意留下的声音痕迹。大多数AI生成的音频片段听起来都“过于完美”。Detect-2B能够预测音频中AI制作的成分,而且无需每次听到新片段时都重新训练模型。这些子模型也经过了大型数据集的充分训练。
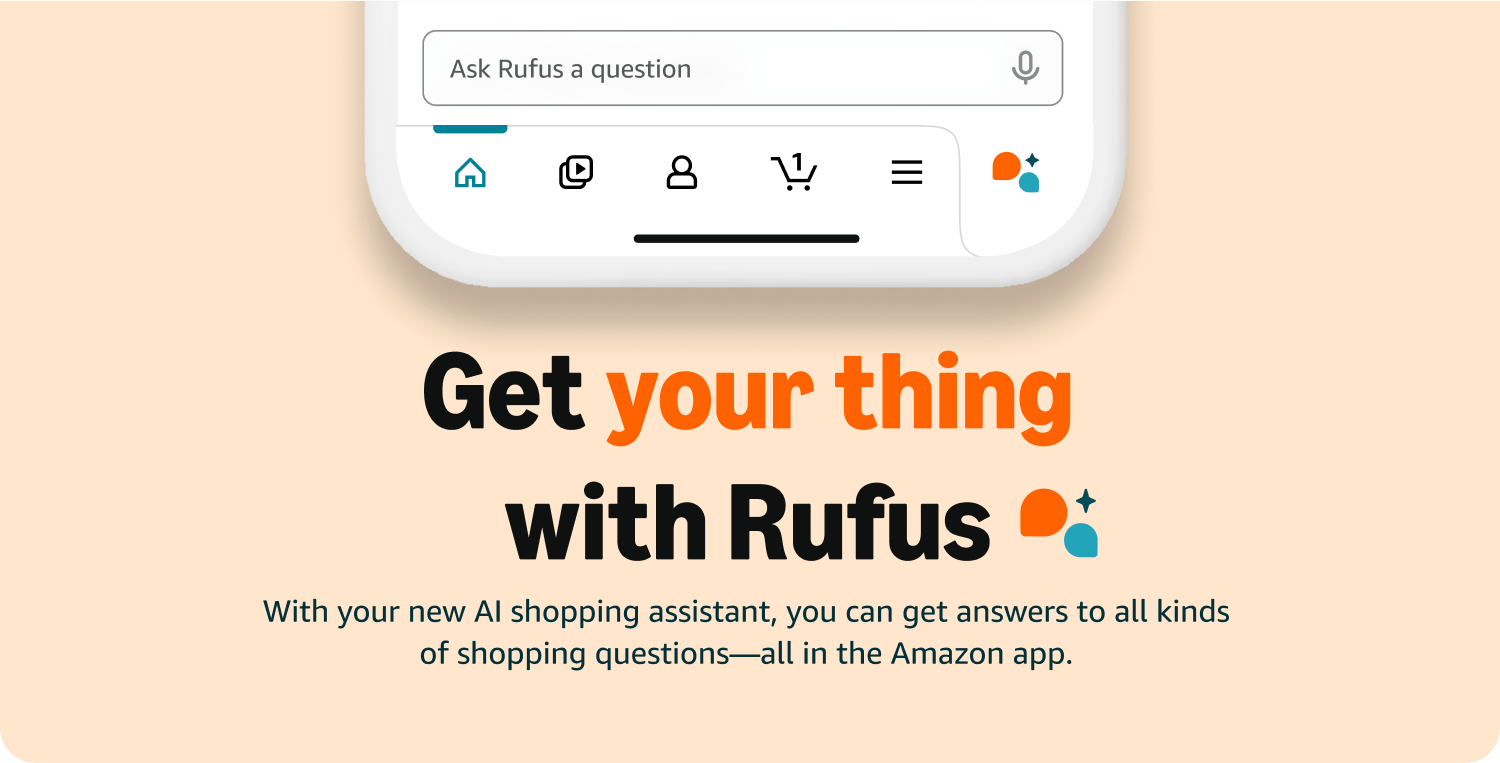
经过数月的测试,亚马逊今天向所有美国客户推出了其生成式人工智能购物助手Rufus。这个对话式购物助手旨在帮助客户节省时间并做出更明智的购买决策。
Rufus现已在亚马逊购物应用中上线,恰逢Prime Day

StreamVC 即使在移动平台上也能以低延迟从输入信号生成结果波形,使其适用于呼叫和视频会议等实时通信场景,并解决这些场景中的语音匿名等用例。
谷歌的设计利用 SoundStream 神经音频编解码器的架构和训练策略来实现轻量级高质量语音合成。
谷歌证明了因果学习软语音单元的可行性,以及提供白化基频信息以提高音调稳定性而不泄漏源音色信息的有效性。

RenderNet Al是一款强大的图像生成工具,专注于创建一致的角色,
并控制其姿势、构图和风格,现在推出了视频换脸功能..
这款 AI 视频换脸工具非常强大

Flawless 是一家人工智能驱动的电影制作工作室,希望您在观看热门节目的同时还能在晚上安然入睡(不会出现不匹配的嘴巴动作和残酷的场景剪辑)。 Flawless 的专有技术 TrueSync 于 2018 年由多才多艺的导演斯科特·曼 (Scott Mann) 和尼克·莱恩斯 (Nick Lynes) 创立,它可以在演员的脸部上进行映射,并提供我们在人工智能狂野西部见过的最令人印象深刻的翻译。

Stability AI宣布为其用户友好型聊天机器人Stable Assistant推出两项创新功能,进一步提升用户体验和创造力。这两项新功能分别是图片编辑中的搜索和替换,以及通过Stable Audio生成高质量音频。
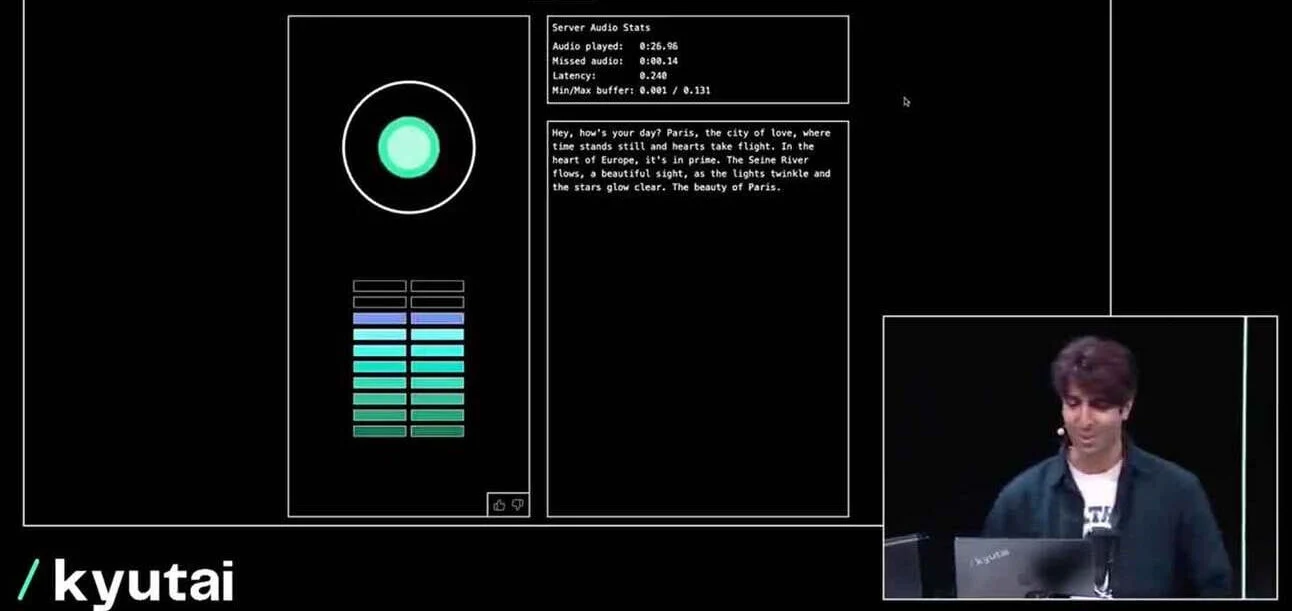
法国独立非盈利AI研究实验室Kyutai推出了具备70种情绪的语音助手Moshi,被视为GPT-4的新挑战者。此次在巴黎的演示显示,Moshi不仅具备多模态交互能力,还能实时生成具有情绪变化的语音,开创性地实现了语音AI的全新应用。

LibreChat是一个免费的开源ChatGPT克隆版,用户可以在一个界面中选择使用不同的AI模型。它支持与OpenAI、Azure、Anthropic和Google等AI模型服务的集成。用户甚至可以在对话中切换AI模型,并使用DALL-E或Stable Diffusion等插件进行图像生成。
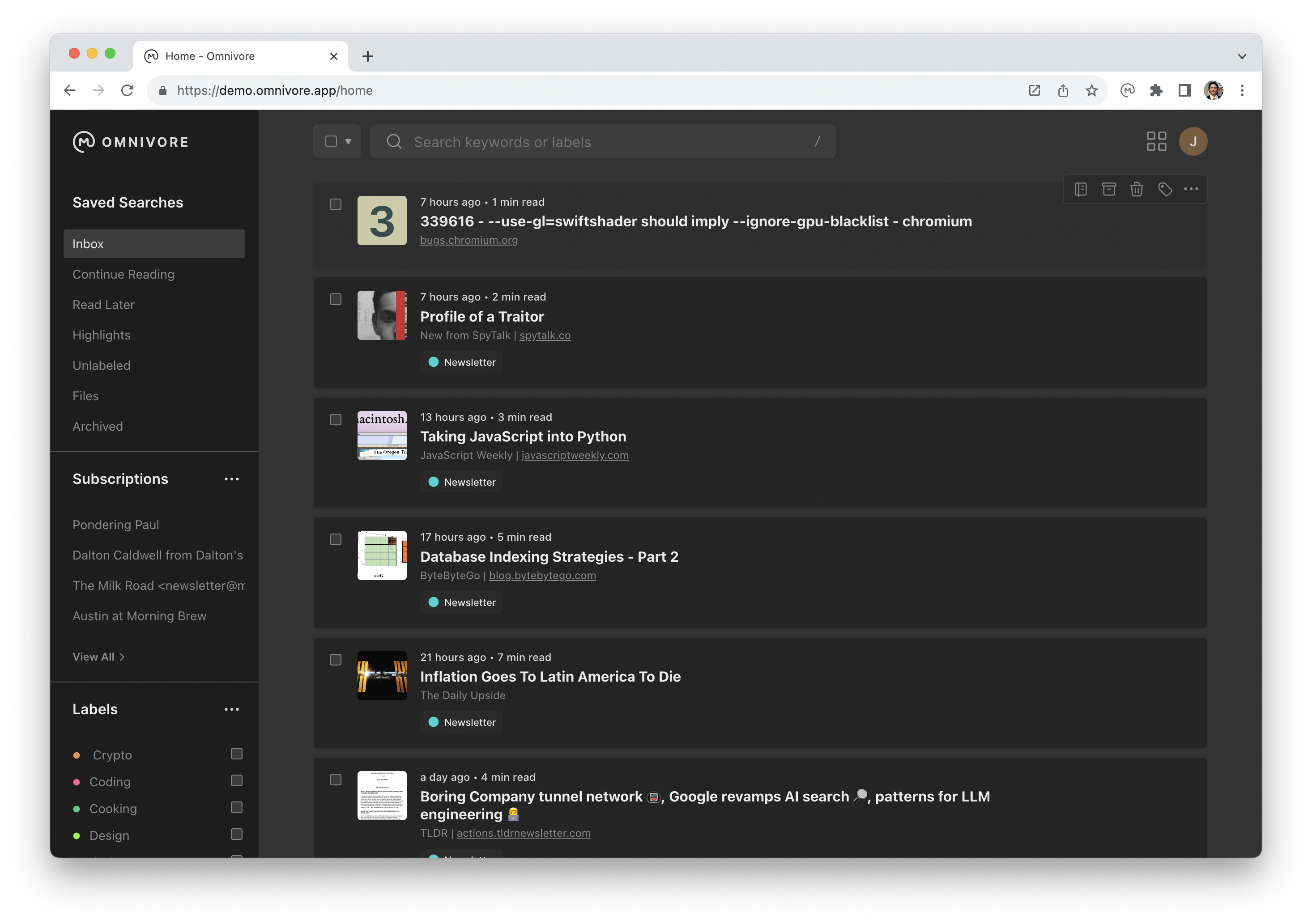
Omnivore 是一个开源的,稍后阅读应用,查看起官方的页面,支持非常多的客户端,包括了 iOS, macOS, Chrome,等等 Android 还在测试中。
Omnivore 吸引的是可以和外部的其他应用同步,比如可以和 Obisidian 同步,还可以接收 Newsletter。 另外还有一个吸引我的点就是,很多宣称可以代替 “Readwise”阅读器,这也是一款还没有深入使用的在线阅读器。
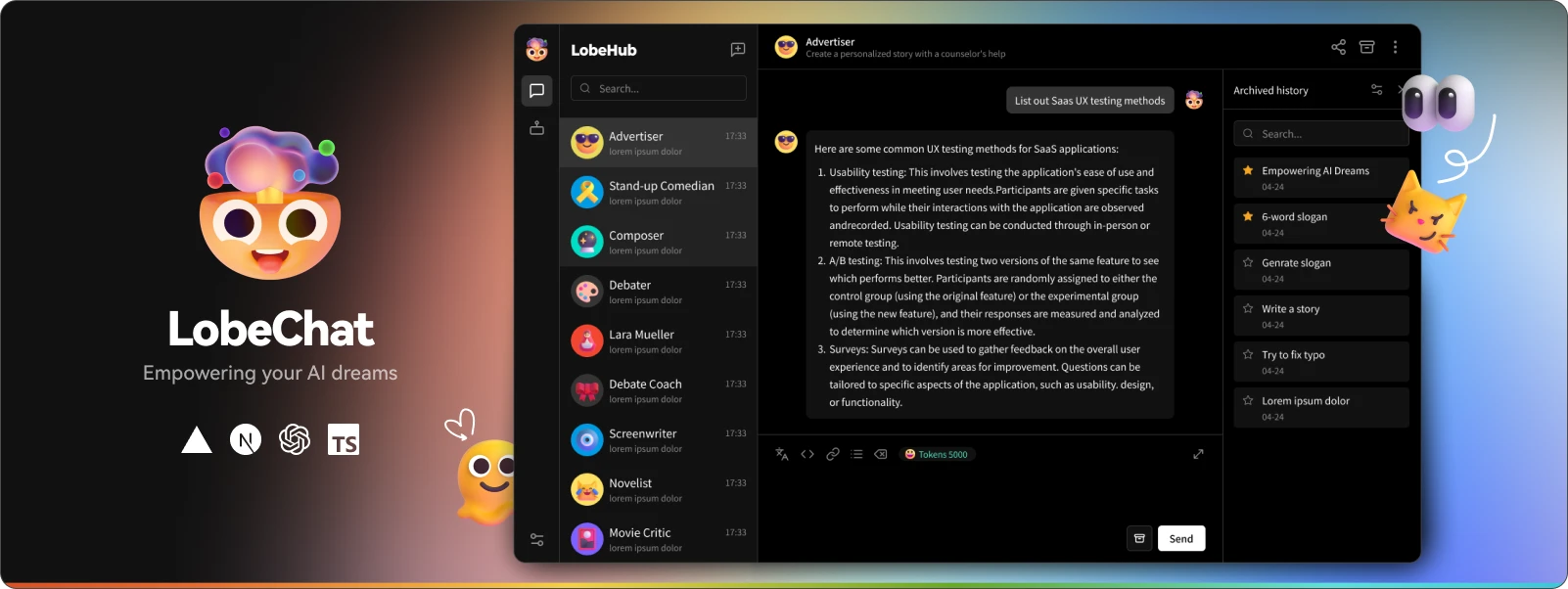
LobeChat 已经支持 OpenAI 最新的 gpt-4-vision 支持视觉识别的模型,这是一个具备视觉识别能力的多模态智能。 用户可以轻松上传图片或者拖拽图片到对话框中,助手将能够识别图片内容,并在此基础上进行智能对话,构建更智能、更多元化的聊天场景。
EmoLLM 是一个用于心理健康领域的大模型项目,通过对大型语言模型(LLM)进行指令微调,旨在支持用户理解、帮助用户进行心理健康辅导。
帮助用户理解和管理情绪
改善行为模式和应对策略
提供心理健康评估和干预措施

Clone(克隆)所言,成立于 2021 年的 Clone 是一家致力于开发低成本、生物仿生和智能仿生机器人的公司。
Clone 的宗旨是运用先进的肌肉骨骼技术,打造类似于《西部世界》中的仿生机器人。
在近期的宣传物料中,1:1 复刻的机器人手灵活地拨弄着手指,以及手握针管等工具,肌肉的拉伸在这个过程中也若隐若现。
也许下一秒,《西部世界》就要走入现实。