微软开源下一代RAG技术
检索增强生成(RAG)是一种基于用户查询搜索信息并提供结果作为生成AI答案的参考的技术。
该技术是大多数基于LLM的工具的重要部分,并且大多数RAG方法使用向量相似性作为搜索技术。
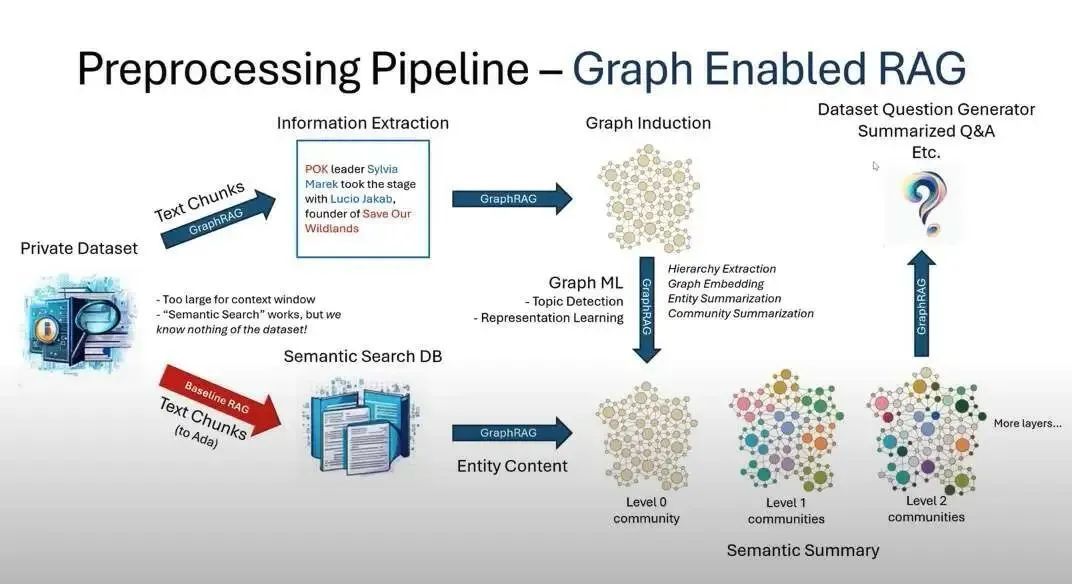
GraphRAG使用LLM生成的知识图,在对复杂信息进行文档分析时,大大提高了问答性能。
检索增强生成(RAG)是一种基于用户查询搜索信息并提供结果作为生成AI答案的参考的技术。
该技术是大多数基于LLM的工具的重要部分,并且大多数RAG方法使用向量相似性作为搜索技术。
GraphRAG使用LLM生成的知识图,在对复杂信息进行文档分析时,大大提高了问答性能。
高质量几何生成:生成精细的三维几何形状,用于构建逼真的场景和物体。
写实材质生成:创建高度真实的材质,使得生成的物体看起来更加生动和自然。
惊艳的光照效果:生成和控制光照效果,增强场景的视觉冲击力和氛围。
可控的运动生成:创建和调整动画和运动效果,使得场景和角色更加动态和逼真。
三星在巴黎举办Unpacked 2024发布会,除了发布Galaxy Z Fold6、Galaxy Z Flip6两款折叠屏手机外,三星还发布了首款智能戒指:Galaxy Ring
Galaxy Ring与普通戒指类似,共九种尺寸,可选钛黑、钛银、钛金三款配色,重量最轻2.3克,戴在手上基本无感。
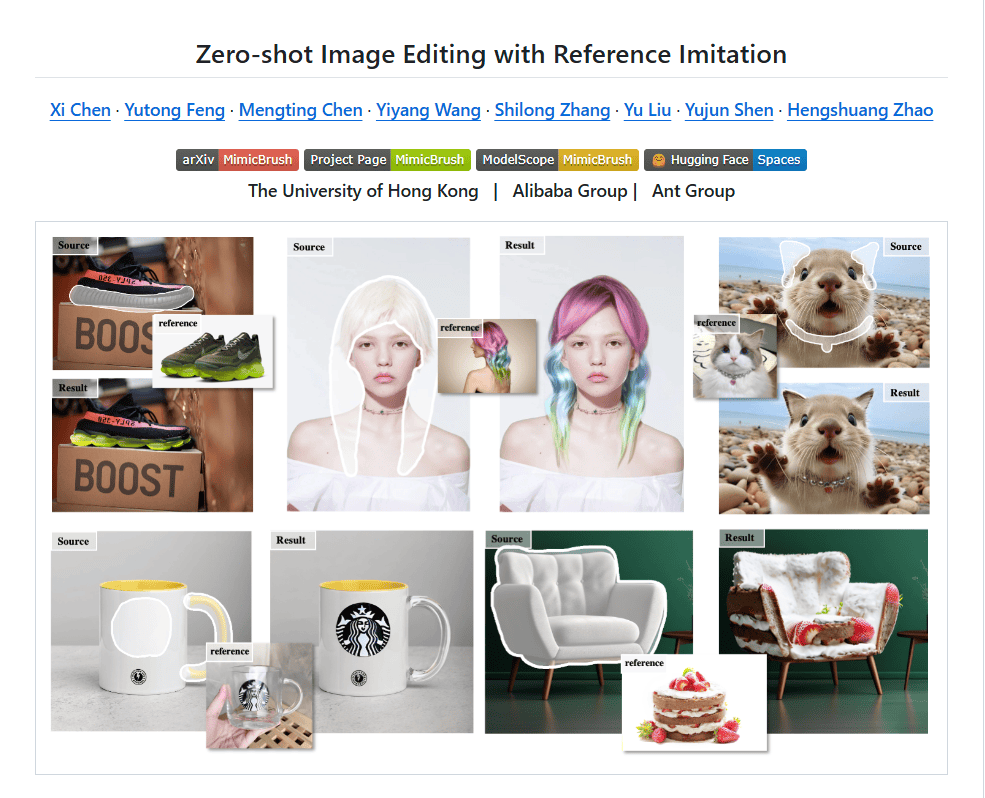
MimicBrush是一种新型的零样本图像编辑技术,由阿里巴巴和香港大学的研究团队共同推出。它允许用户通过上传参考图片来实现原图的局部风格重绘。用户只需指定待编辑的区域并提供一张参考图片,MimicBrush就能够自动理解并模仿参考图片的风格,完成编辑任务。
他们的工作逐渐被 ChatGPT 所取代,而他们的职责则变成了专门修改AI生成的文章,使其不那么机械化和公式化
公司引入了一个自动化系统:经理将文章标题输入在线表单,AI生成大纲,
copilot旨在协助医生,而不是取代医生。他说:“我们称其为copilot,是因为它与工程助手的思维和模式非常相似。这并不是说copilot取代了(软件)工程师。”
OpenAI和Color Health于去年开始研发本周一发布的copilot。
一款语音识别、语音合成、说话人识别、说话人验证等集成了多种语音处理功能的工具:sherpa-onnx
支持:语音识别(ASR,支持流式和非流式)、语音合成(TTS)、说话人识别、说话人验证、语种识别、音频标注、声音活动检测(VAD,例如silero-vad)、关键词检测等
和EMO相比,该项目已开源😄
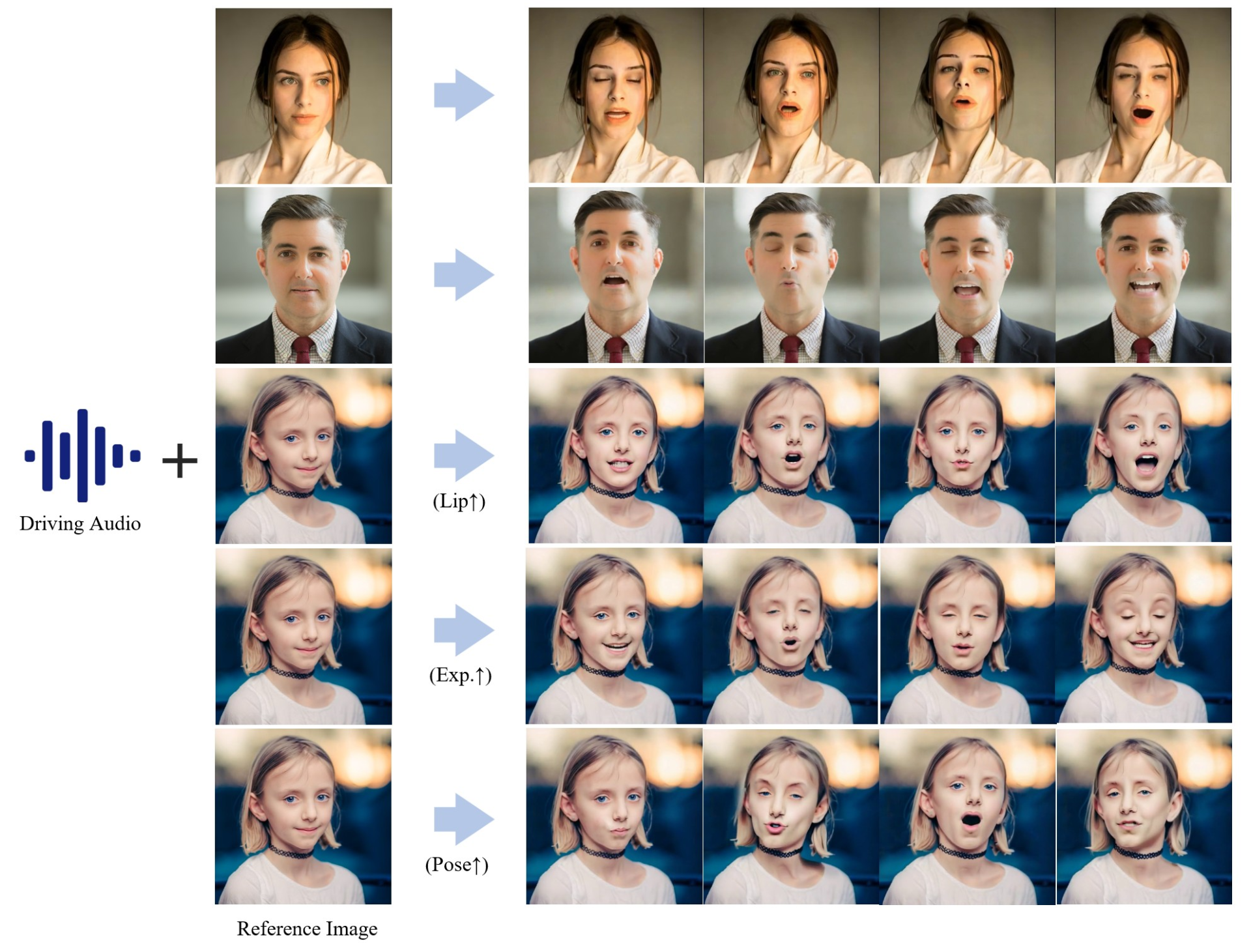
它能够通过输入语音,生成对应的人物嘴唇同步、表情变化和姿态变化的动画。
提高了语音与生成动画之间的对齐精度,使动画的嘴唇、表情和姿态与语音更匹配。
提供对角色表情、姿态和嘴唇运动的精确控制。
支持多种表情和姿态的自适应控制,增强动画的多样性和真实性。
AI Math Notes 是一个互动绘图应用程序,用户可以在画布上绘制数学方程。
绘制完方程后,应用程序会使用多模态大语言模型 (LLM) 计算结果,并在等号旁显示。
该应用程序使用 Python 编写,图形用户界面采用 Tkinter 库,图像处理使用 PIL 库。
苹果新出的翻译 API,不需要联网,完全使用本机大语言模型。
使用翻译框架提供应用内翻译。您可以使用内置 UI,让系统代表您向用户提供翻译。或者您可以使用该框架来定制翻译体验。
要提供内置系统翻译体验,请将视图修饰符锚定到包含要翻译的文本的 SwiftUI 视图。当您希望显示内置系统翻译 UI 时,将 isPresented 设置为 true。将要翻译的文本传递给 text 参数。
@niceaunties
作者介绍:“Niceaunties”的灵感来自于阿姨文化中荒唐又可爱的行为。 TED 演讲者。奖学金 http://daily.xyz 艺术家。
Nemotron-4 340B,一个优化用于NVIDIA NeMo和NVIDIA TensorRT-LLM的模型家族,包括最先进的指令模型和奖励模型,以及用于生成式AI训练的数据集。
NVIDIA今天宣布推出Nemotron-4 340B,这是一组开源模型,开发人员可以使用这些模型生成用于训练大语言模型(LLMs)的合成数据,以应用于医疗、金融、制造、零售等各个行业的商业应用。
NVIDIA ACE(Avatar Cloud Engine)是一套可協助開發人員使用生成式AI將數位化身變為現實的技術。透過 ACE,非玩家角色 (NPC) 可以轉變為動態的互動式角色,能夠發起對話,或提供遊戲知識來幫助玩家完成任務。
在 CES 2024 上,我們宣布推出ACE 產品級微服務 ,提供頂尖數位化身開發人員NVIDIA Audio2Face (A2F) 和 NVIDIA Riva 自動語音辨識 (ASR)。
Refuel AI 最近推出了两个新版本的大语言模型 RefuelLLM-2 和 RefuelLLM-2-small。
RefuelLLM-2 和 RefuelLLM-2-small 是专门为数据标注、清洗和丰富任务而设计的语言模型。
用途: RefuelLLM-2 主要用于自动化数据标注、数据清洗和数据丰富,这些任务是处理和分析大规模数据集时的基础工作,尤其是在需要将非结构化数据转换为结构化格式的场景中。
升级到V 2版本
与之前专注于英文文本版本相比
Glyph-ByT5-v2能够支持10种不同语言的准确拼写,显著提升了多语言文本渲染的准确性和广泛性。
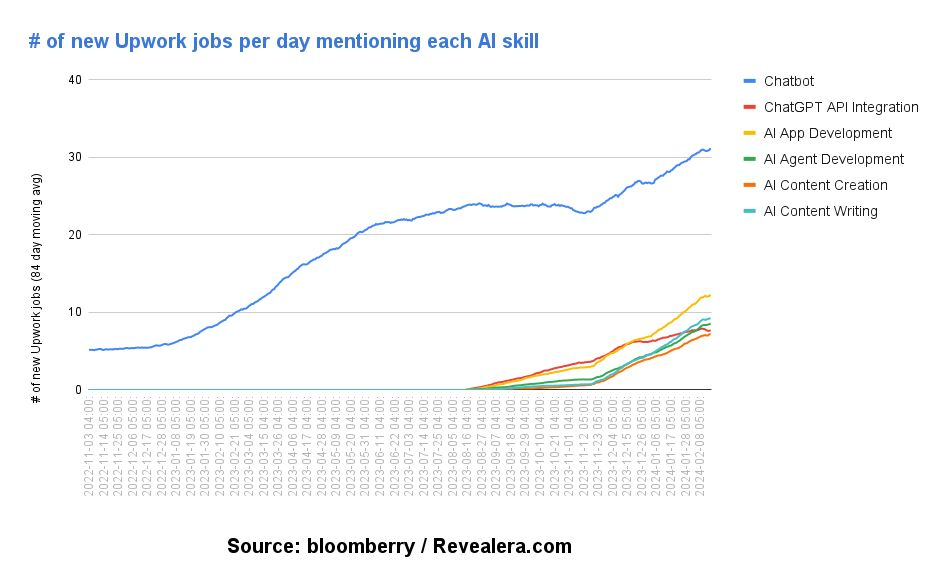
分析了 Upwork 上 2022/11 到2024/02的职位数据,看哪些工作数量下降,哪些工作数量上升,哪些工作时薪下降,哪些 AI 技能的工作发布量增加最多。选择2022/11月作为起始点,是因为 ChatGPT 发布时间是 2022/11/30,而这视为生成式 AI 的起点。