Luma AI推出了视频生成器,名为 Dream Machine
Luma AI 刚刚推出了一款类似 Sora 的 AI 视频生成器,名为 Dream Machine。
但与 Sora 或 KLING 不同的是,它完全向公众开放。
Luma AI 刚刚推出了一款类似 Sora 的 AI 视频生成器,名为 Dream Machine。
但与 Sora 或 KLING 不同的是,它完全向公众开放。
用 MLX 把你的 iPhone、iPad 还有 Mac 在本地连接起来组成一个大号 GPU 来用!Nvidia 在数据中心做超级 GPU,Apple 说我 Edge Devices 多,用这种廉价方式串联 GPU 也行
ToonCrafter,这是一种超越传统基于通信的卡通视频插值的新方法,为生成插值铺平了道路。传统方法隐含地假设线性运动,并且没有像消遮挡这样的复杂现象,经常与卡通中常见的夸张的非线性和带有遮挡的大运动作斗争,导致插值结果难以置信甚至失败。
OpenAI 在命名下一代人工智能模型时可能会放弃数字,至少最近在巴黎举行的一次演讲中是这么建议的。
在 VivaTech 会议上演示 ChatGPT Voice 期间,OpenAI 开发人员体验主管 Romain Huet 展示了一张幻灯片,揭示了未来几年人工智能模型的潜在增长,但 GPT-5 并未出现在其中。
该框架包括一套功能齐全的高端软件分析工具,使用户能够在包括 Windows、macOS 和 Linux 在内的各种平台上分析编译的代码。功能包括反汇编、汇编、反编译、绘图和脚本编写,以及数百种其他功能。
Ghidra 支持多种处理器指令集和可执行格式,并且可以在用户交互和自动化模式下运行。用户还可以使用 Java 或 Python 开发自己的 Ghidra 扩展组件和/或脚本。
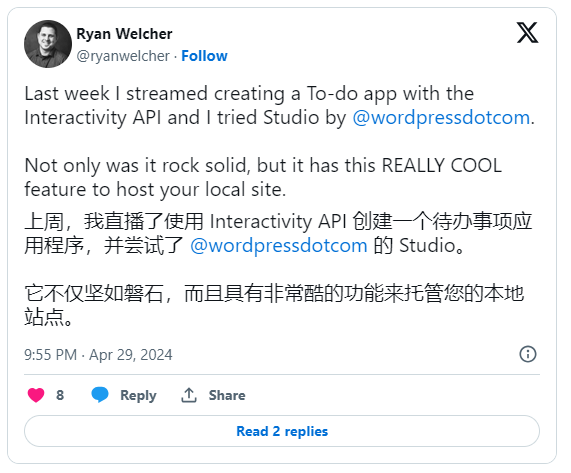
Studio,免费的本地 WordPress 开发环境,现在可用于 Windows。
最近推出了 Studio,这是适用于 MacOS 的免费开源本地 WordPress 开发环境,Windows 版本的 Studio 现已推出!
提醒一下,将 Studio 构建为本地构建 WordPress 网站的最快、最简单的方法。
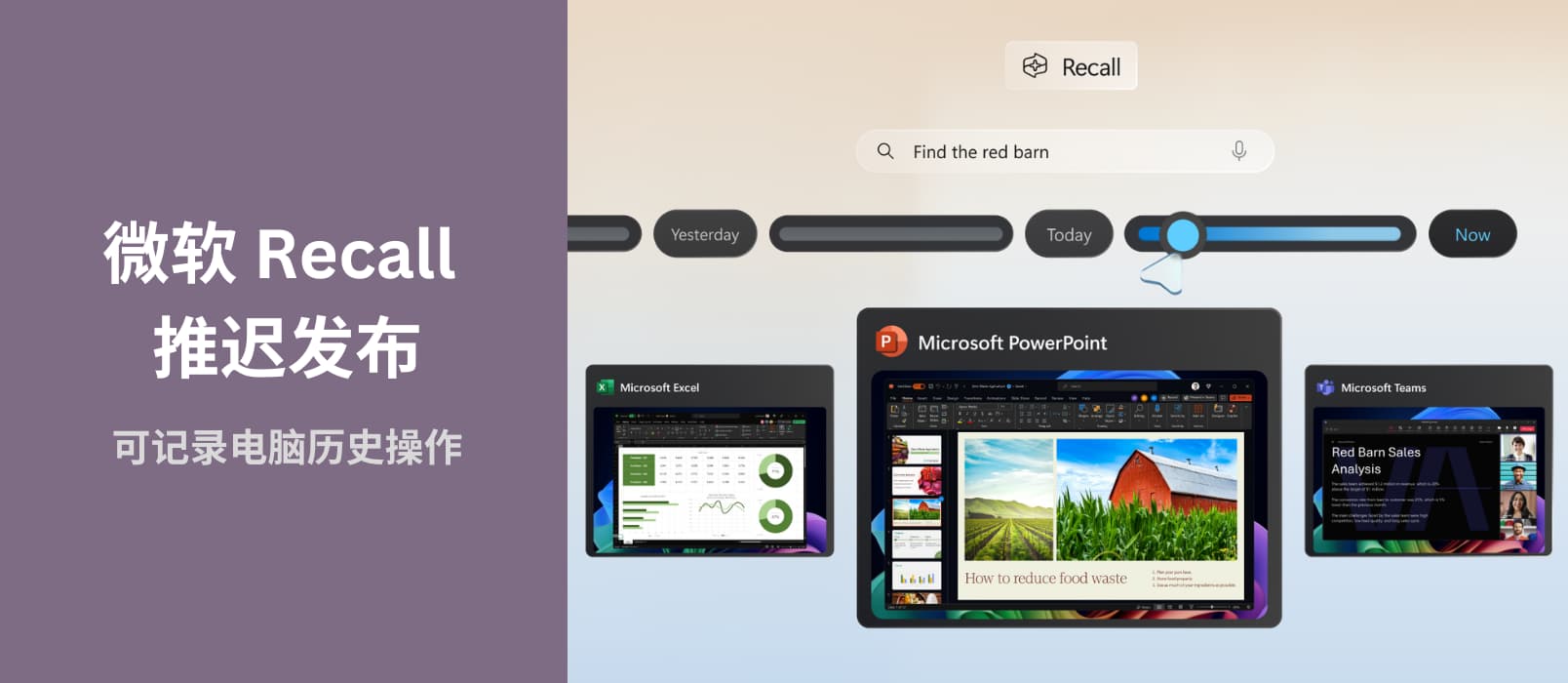
微软:新电脑上捕捉屏幕截图的Recall AI 功能将默认关闭
该功能每5秒截取一次用户屏幕并记录用户屏幕操作。
使用户能够像查询记忆一样回顾过去的操作。但这一功能引发了网络安全专家的担忧,他们认为黑客有可能获取用户信息。
本地和远端大模型混合使用的方案。
使用 chrome 本地模型的好处:
1、本地处理敏感数据;
2、流畅的用户体验;
3、对 AI 的访问权限更高;
4、离线使用 AI。
人工智能教育家minchoi。 X关于人工智能、解决方案和有趣的事情。 展示如何以实用的方式为您和您的企业利用人工智能。
使用 Midjourney v6 以《Mad Max: Furiosa》的风格重新想象著名的艺术作品。
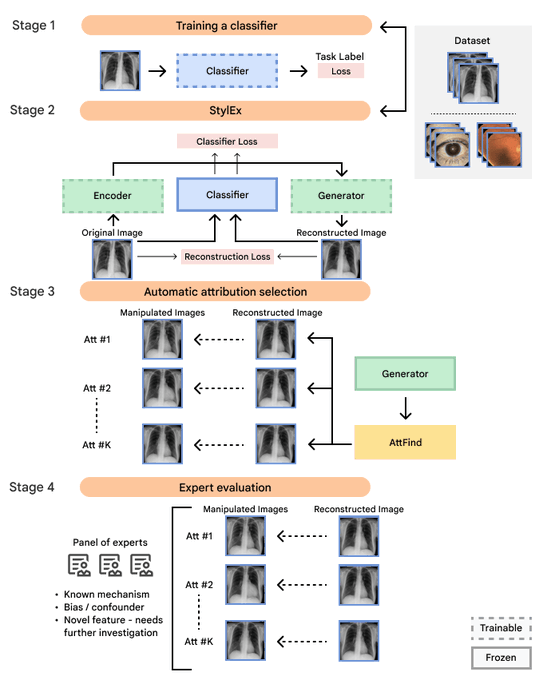
机器学习 (ML) 有潜力彻底改变医疗保健,从减少工作量和提高效率到发现新的生物标志物和疾病信号。为了负责任地利用这些好处,研究人员采用可解释性技术来了解机器学习模型如何进行预测。然而,当前基于显着性的方法突出了重要的图像区域,通常无法解释特定的视觉变化如何驱动机器学习决策。
Truecaller 很自豪地宣布与 Microsoft 建立合作伙伴关系,利用 Microsoft Azure AI Speech 的全新个人语音技术。 Truecaller 的 AI 助手于 2022 年 9 月首次推出,已经融合了多种 AI 技术,可以自动为您接听电话、屏幕呼叫、接收消息、代表您回复或记录通话以供您以后查看。
ChatTTS:专门为对话场景设计的文本到语音TTS模型
该模型经过超过10万小时的训练,公开版本在 HuggingFace 上提供了一个4万小时预训练的模型。
专为对话任务优化,能够支持多种说话人语音,中英文混合等。
Seed-TTS,这是一系列大规模自回归文本转语音(TTS)模型,能够生成几乎与人类语音无法区分的语音。
Seed-TTS作为语音生成的基础模型,在语音上下文学习中表现出色,在说话者相似性和自然性方面的表现与真实人类语音在客观和主观评估中相匹配。
通过微调,我们在这些指标上获得了更高的主观评分
LearnLM-Tutor 是一个由 Google DeepMind 开发的生成式 AI 模型,专门用于教育领域,旨在提供一对一的对话辅导。
通过即时反馈、多轮对话、错误识别和积极学习促进等功能,模型不仅帮助学生解决具体问题,还培养他们的自主学习和批判性思维能力。结合定制化学习计划、多学科支持和进步追踪功能,LearnLM-Tutor 成为一个强大的教育工具,为学生的全面发展提供了有力支持。