谷歌家的好东西:艺术家
say-what-you-see
可以帮你学会如何写 AI 画图提示词
除了教你技巧外还会有对应的练习,给你一张图片让你用学习的技巧写提示词复刻图片。
藏师傅第一等级全部 70 分以上通过,哈哈。
来测试一下你的 AI 画图提示词能力吧,又要干苦力给谷歌打标了
say-what-you-see
可以帮你学会如何写 AI 画图提示词
除了教你技巧外还会有对应的练习,给你一张图片让你用学习的技巧写提示词复刻图片。
藏师傅第一等级全部 70 分以上通过,哈哈。
来测试一下你的 AI 画图提示词能力吧,又要干苦力给谷歌打标了
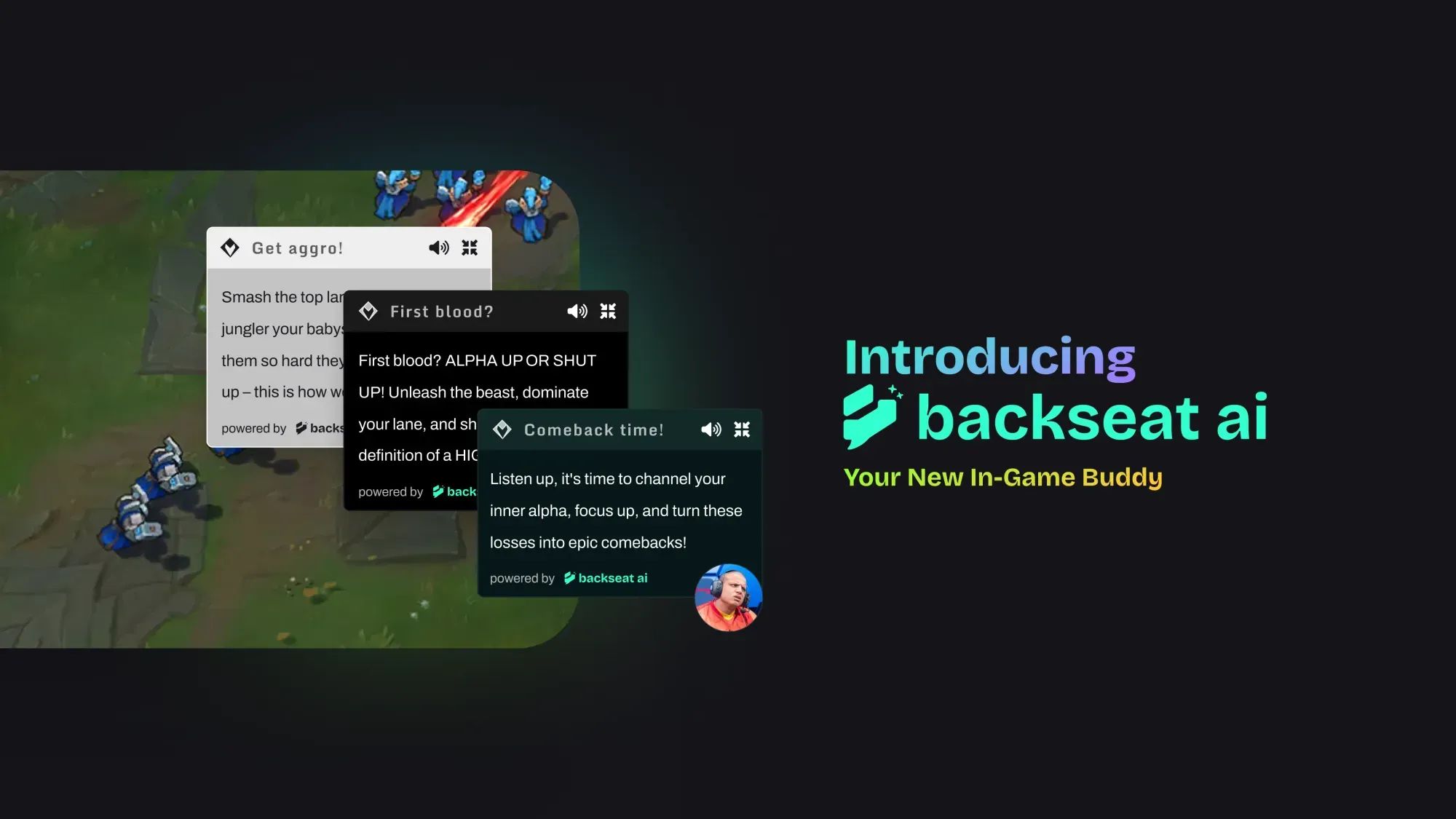
Backseat 是一款由人工智能驱动的游戏内好友,旨在提升您的联盟体验并让您在游戏中获益。我们的梦想是成为在联赛中取得进步的最佳方式,让每场比赛变得社交化和有趣。
今天,我们的桌面应用程序中提供了 Backseat Buddy(游戏内 AI 语音伴侣)和游戏后大厅功能,还有更多功能即将推出 – 包括与好友的实时问答、赛前建议以及更多创作者声音(来自全球创作者!)。
介绍了第一个名为 Prompt2Sign 的多语言手语数据集,该数据集基于公共手语数据,包括美国手语 (ASL) 和其他七种语言。
数据集将大量视频转换为简化的、模型友好的格式,并针对 seq2seq 和 text2text 等翻译模型的训练进行了优化。在此新数据集的基础上,提出了 SignLLM,这是第一个多语言手语生成 (SLP) 模型,其中包括两种新颖的多语言 SLP 模式,允许根据输入文本或提示生成手语手势。
PictoGraphic 是一个AI生成的插图库,提供超过40000张图像和SVG文件,你在这里可以找到适合自己的免费插图
作为设计师,通常会发现自己的设计需要 10 – 15 个高质量图形。
然而,找到这么多既能表达我们的想法又具有共同艺术风格的插图是非常具有挑战性和耗时的。通常,我们最终会花费大量时间在不同的网站和集合中寻找类似的插图,甚至花费更多的时间“再尝试一次”来编辑插图以使其适合。
Deep Paint 提供了各种特制的笔刷和材质,让你的模型看起来更有艺术效果,比如模拟水彩画或粉彩画的效果
您想用 Blender 创造自己的充满幻想的梦幻世界吗?从基本操作到建模、灯光、动画和油性铅笔,让我们通过各种挑战增强您的 3D 知识,共同创作精彩的作品。
无论是Python, Java还是JavaScript,各种语言和技术主题应有尽有。
还有播客、在线课程,以及互动式编程资源,满足各种学习需求
仓库地址就在视频下方,有兴趣额可以点开连接自行查看
刚发布的时候风格复用只能通过垫图用风格一致性的方式。现在直接展示了风格代码,可以很方便的复用功能。
在探索页面随便找了一个提示词,用随机风格抽奖跑了一下,结果出来一个很强的风格。
可以让画面出现暗黑粗粝的风格,而且会大概率出现雪景和怪物特写。
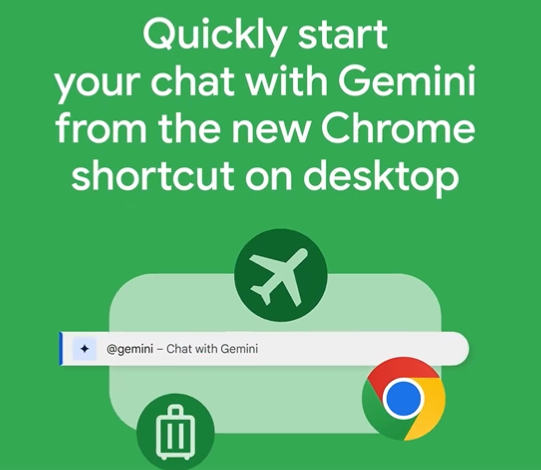
谷歌在 Chrome 中集成了一项新功能,允许用户输入“@”来启动 Gemini。
新的人工智能工具几乎没有学习曲线
立即改进产品并利用现有分销
慢慢提高非人工智能用户的技能
1/ Smartify
使用它你可以像扫描QR码一样扫描绘画、纪念碑、建筑,扫描后,应用会为你提供详细信息。
2/ Snapseed
Snapseed免费提供从裁剪到改变脸部方向或删除物体的一系列功能。
3/ Headspace
一款可以帮助你减压减焦虑的冥想应用。
此次融资由 Lightspeed Venture Partners、Nat Friedman、Daniel Gross 等顶级投资者领投。
Suno 称此轮融资旨在加速产品开发并扩展其音乐创作者团队。致力于打造一个人人都能创作音乐的平台!
音乐家社区值得拥有最好的工具,而构建最好的工具需要最优秀的人才。我们将利用这笔资金来加速产品开发,并发展我们世界一流的音乐制作人、音乐爱好者和技术人员团队。
LlamaFS 是一个自组织文件管理器。它会根据文件的内容和众所周知的约定(例如时间)自动重命名和组织文件。它支持多种文件,甚至图像(通过 Moondream)和音频(通过 Whisper)。
LlamaFS 以两种“模式”运行 – 作为批处理作业(批处理模式)和交互式守护进程(监视模式)。
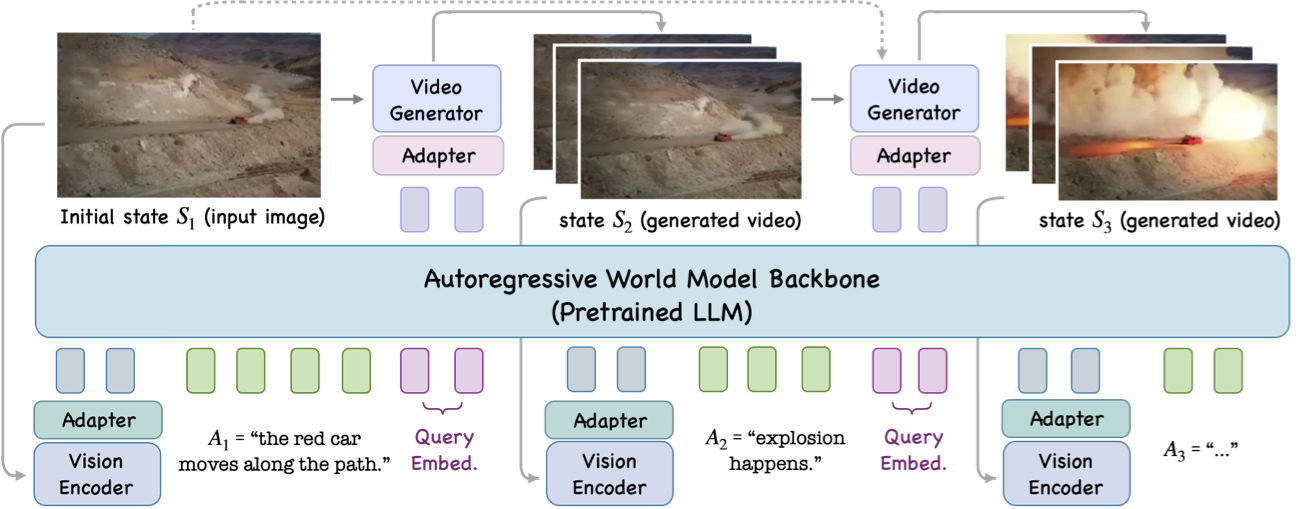
Pandora 在视频生成过程中接受自由文本操作作为输入,以动态引导视频。这与以前的文本到视频模型有很大不同,以前的文本到视频模型只允许在视频开头出现文本提示。动态控制实现了世界模型的承诺,支持交互式内容生成并增强稳健的推理和规划。
在课堂里我一直是面向考试学习英语,不断记忆那些永远也记不住的单词,阅读那些即使翻译成中文也很枯燥的文章。
后来我完成了学校的所有英文课程以后,就开始寻找一些可以让英语学习和娱乐、技能学习相结合的方法。比如阅读感兴趣的英文书籍就是个很好的方法。
在 Microsoft Build 2024 上,Microsoft Copilot Studio 中的一系列强大新功能,您可以使用它来创建自己的自定义副驾驶或通过自己的企业数据和场景扩展 Microsoft Copilot 体验。
第一个是Copilot ,现在可以充当独立代理,可以由事件触发,而不仅仅是对话,并且可以自动化和编排复杂的、长期运行的业务流程,具有更多的自主权和更少的人为干预。
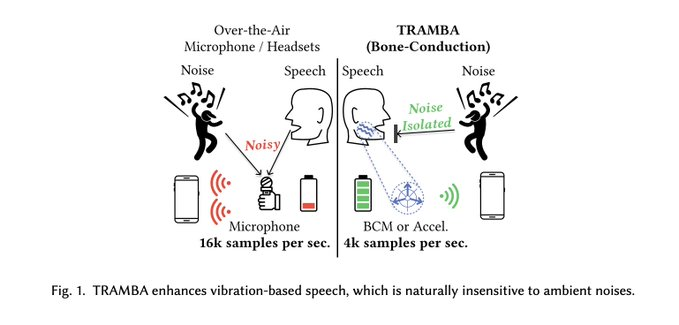
来自西北大学和哥伦比亚大学的研究人员推出了混合变压器 TRAMBA 和 Mamba 架构,用于增强移动和可穿戴平台中的声学和骨传导语音。此前,在此类平台中采用骨传导语音增强技术面临着由于劳动密集型数据收集和模型之间的性能差距而面临的挑战。 TRAMBA 通过使用广泛可用的音频语音数据集进行预训练并使用少量骨传导数据进行微调来解决这个问题。
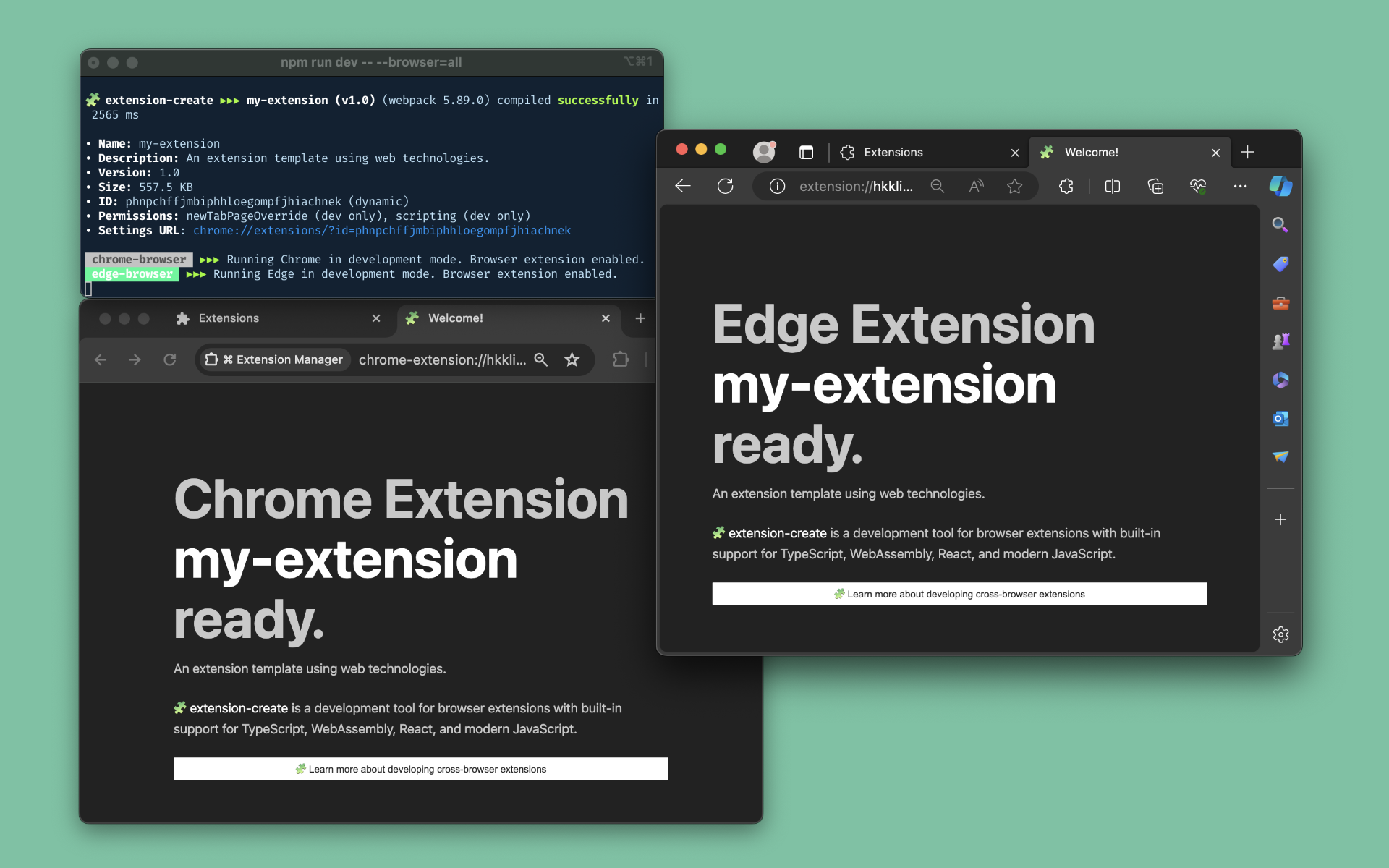
一个命令行工具一键生成支持不同浏览器插件的开发环境,内置支持 TS,React,WebAssembly 以及现代 Javascript。
试了一下,确实挺香,看官方视频感受一下,大家如果要做浏览器插件,建议直接使用这个插件。
无需构建配置即可创建跨浏览器扩展。