一个做llama3中文微调的宝藏仓库
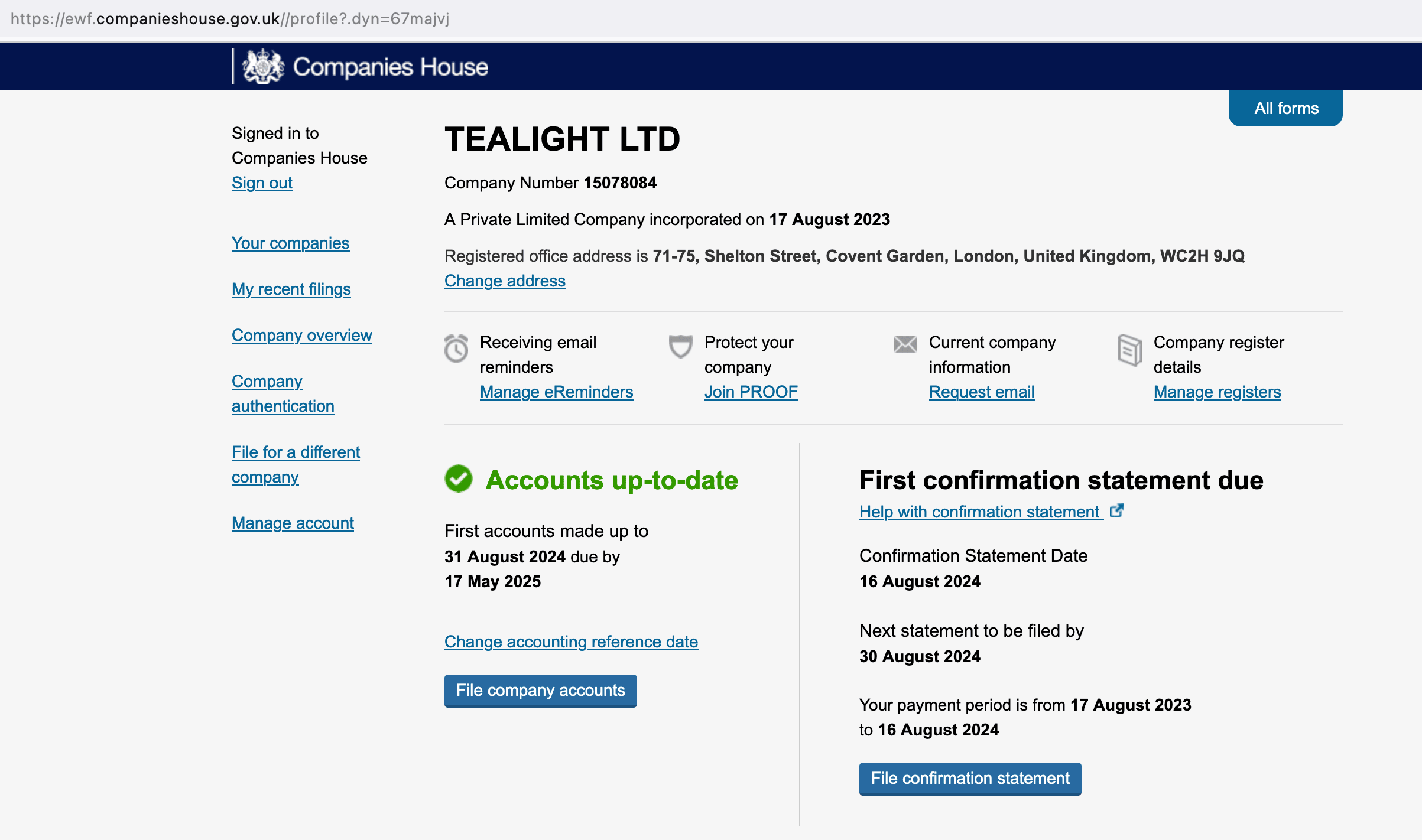
CrazyBoyM/llama3-Chinese-chat: Llama3 中文仓库(聚合资料,各种微调、魔改版本有趣权重 & 训练、推理、评测、部署教程视频 & 文档),旨在支持中文场景下的Llama3模型应用和开发。
CrazyBoyM/llama3-Chinese-chat: Llama3 中文仓库(聚合资料,各种微调、魔改版本有趣权重 & 训练、推理、评测、部署教程视频 & 文档),旨在支持中文场景下的Llama3模型应用和开发。
首款超1000亿参数模型
Qwen1.5-110B是Qwen1.5系列中的新成员,也是该系列首个拥有超过1000亿参数的模型。
该模型在基础模型评估中表现出色,与Meta-Llama3-70B相媲美,并在聊天模型评估(包括MT-Bench和AlpacaEval 2.0)中表现出色
人工智能教育家。 𝕏 关于人工智能、解决方案和有趣的事情。 展示如何以实用的方式为您和您的企业利用人工智能。
人工智能教育家@minchoi 使用 Midjourney v6 重新构想了著名的艺术作品,以《星球大战》的风格呈现。
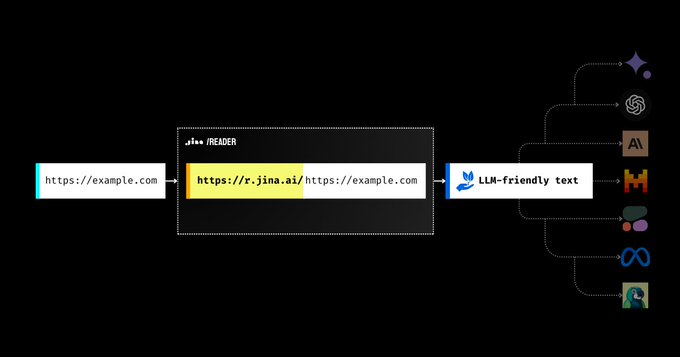
可以做两件事:
它将任何 URL 转换为 https://r.jina.ai/https://your.url 的 LLM 友好输入。免费提高代理和 RAG 系统的输出。
它使用 https://s.jina.ai/your+query 在网络上搜索给定的查询。这使您的LLMs能够从网络获取最新的世界知识。
支持图像视频等多种视觉语言任务
包括支持图像和短视频字幕、视觉问答、图像文本理解、物体检测文件图表解读、图像分割等任务。
PaliGemma 模型包含 30 亿(3B)个参数,结合了 SigLiP 视觉编码器和 Gemma 语言模型。
Prettygraph 是一个基于 Python 的 Web 应用程序,由 @yoheinakajima 开发,用于演示文本到知识图生成的
新 UI 模式。该项目是一个快速破解项目,并不是要成为一个强大的框架,而是一个简单的 UI 想法,用于在生成知识图时动态突出显示文本输入。
能够应对各种类型的线条艺术作品,无论是手绘草图、不同的 ControlNet 线预处理工具,还是由模型生成的轮廓,都能高精确性和稳定地处理。
一个重要特点是其泛化能力极强,无需针对不同的线预处理工具更换不同的 ControlNet 模型。
DeepFaceLive 建立在 DeepFaceLab 的基础上,后者为当前领先的面部交换框架,能够产生接近电影质量的面部合成效果,提供高保真的视觉体验。
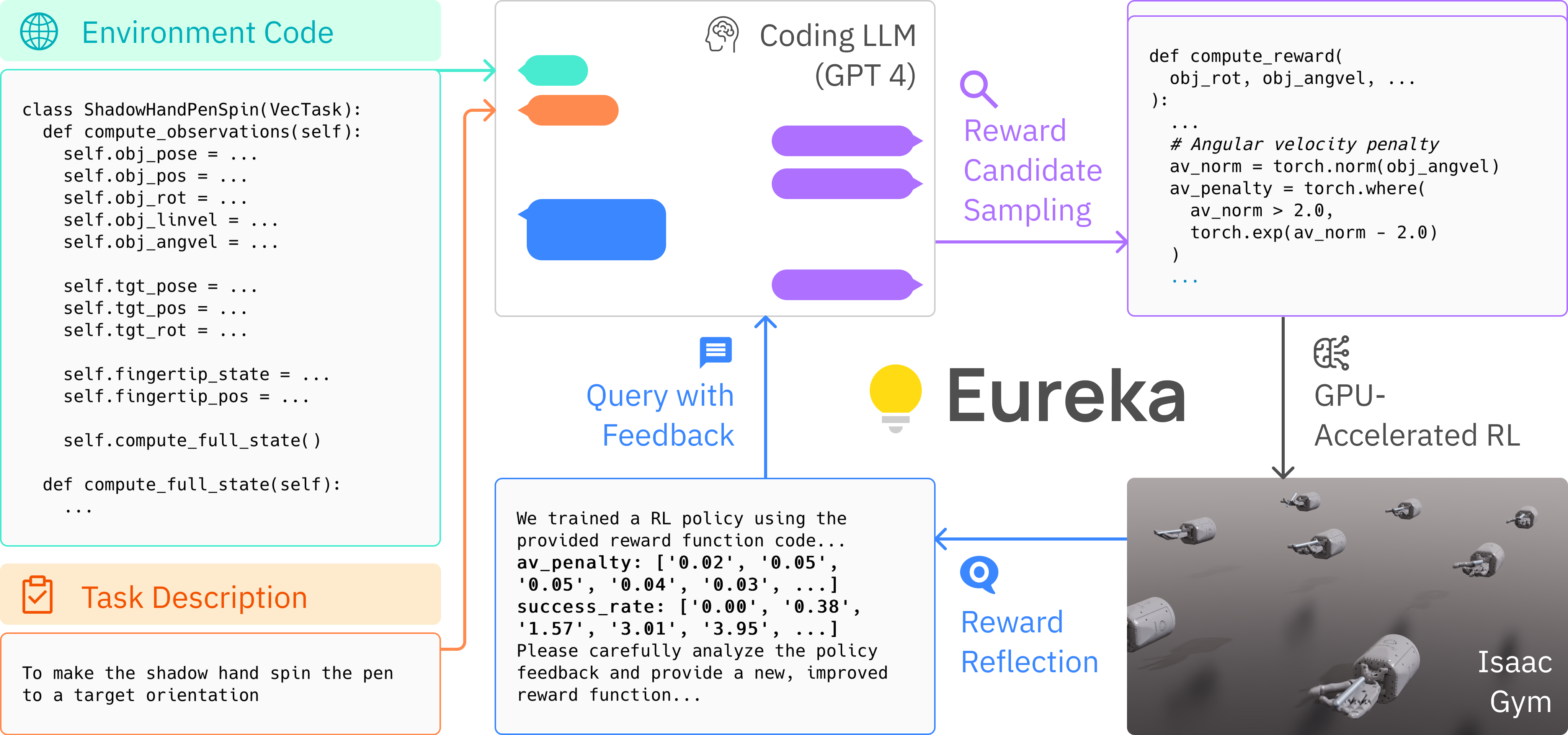
Eureka 弥合了高级推理(编码)和低级运动控制之间的差距。它是一种“混合梯度架构”:一个黑盒,仅推理 LLM 指示一个白盒,可学习的神经网络。外循环运行 GPT-4 来细化奖励函数(无梯度),而内循环运行强化学习来训练机器人控制器(基于梯度)。
能够生成细节丰富、内容多样的图像和视频,同时保持角色身份和服饰的一致性。
可以帮助生成长篇漫画或者带连续剧情的视频。
与IP-Adapter和PhotoMaker等方法相比,StoryDiffusion在保持角色一致性的同时,还能更好地控制文本提示,生成与描述更匹配的图像和视频。
可以将你直播说话时候的声音变声其他各种角色和性别的声音。
还能调整音调、音调动态和混响等参数,塑造个性化的声音。
也可以将你声音与任何角色的声音以任意比例混合,创造出新的声音 。
支持文字生成模型、图片生成模型,分辨率512×512,5秒内即可生成。
3D内容创作在质量和速度方面都取得了显着进步。尽管当前的前馈模型可以在几秒钟内生成 3D 对象,但其分辨率受到训练期间所需的密集计算的限制。在本文中,介绍了大型多视图高斯模型 (LGM),这是一种新颖的框架,旨在从文本提示或单视图图像生成高分辨率 3D 模型。