自动将你的网页内容转换为播客
Audio Native 是一个嵌入式音频播放器,可以自动为网页内容生成语音
只需插入一段简短的代码,即可插入到任何网页和内容中,自动为内容生成语音旁白。
您现在正在阅读的这一行的上方有一个播放按钮。按播放键,您可以收听由 ElevenLabs 语音自动生成的这篇文章的旁白。我们将这种嵌入式语音播放器称为“Audio Native”。
Audio Native 是一个嵌入式音频播放器,可以自动为网页内容生成语音
只需插入一段简短的代码,即可插入到任何网页和内容中,自动为内容生成语音旁白。
您现在正在阅读的这一行的上方有一个播放按钮。按播放键,您可以收听由 ElevenLabs 语音自动生成的这篇文章的旁白。我们将这种嵌入式语音播放器称为“Audio Native”。
包括「眼動追蹤」、「音樂觸覺」和「聲音捷徑」
Apple 今日宣佈將於今年稍晚推出全新輔助使用功能,包括「眼動追蹤」,一種讓身體障礙使用者只用眼睛即可控制 iPad 和 iPhone 的方式。此外,「音樂觸覺」將為聾人與聽力障礙使用者提供一種用 iPhone 觸感引擎體驗音樂的新方式;「聲音捷徑」將讓使用者能藉由發出自訂聲音來執行任務;「車輛移動提
Copilot+ PC 是迄今为止最快、最智能的 Windows PC。凭借强大的新型芯片,能够实现令人难以置信的 40+ TOPS(每秒万亿次操作)、全天的电池寿命以及对最先进人工智能模型的访问,Copilot+ PC 将使您能够完成任何其他 PC 上无法完成的事情。通过 Recall 轻松查找并记住您在 PC 中看到的内容,使用 Cocreator 直接在设备上近乎实时地生成和优化 AI 图像,并通过实时字幕消除语言障碍,将 40 多种语言的音频翻译成英语。
配备人工智能瞄准步枪的机器狗接受美国海军陆战队特种部队评估
正在接受审查的四足动物具有自动瞄准系统,但需要人工监督才能开火。
据战区报道,美国海军陆战队特种作战司令部 (MARSOC) 目前正在评估 Ghost Robotics 开发的新一代机器人“狗”,该机器人“狗”有可能配备国防科技公司 Onyx Industries 的枪支系统。
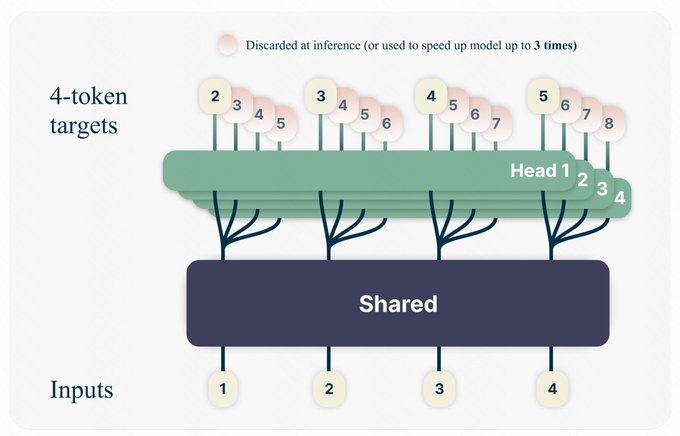
Meta AI 重新介绍了一下他们的新论文,通过一次预测多个词汇来加速 LLM 的训练。
通常语言模型都是根据已知词汇预测下一个词。而这篇论文提出每次预测接下来的多个词,而不仅仅是一个词。
这种方法可以在不增加训练时间的情况下,提高代码和自然语言模型在下游任务上的能力。对于规模更大的模型,这种改进效果更加明显。
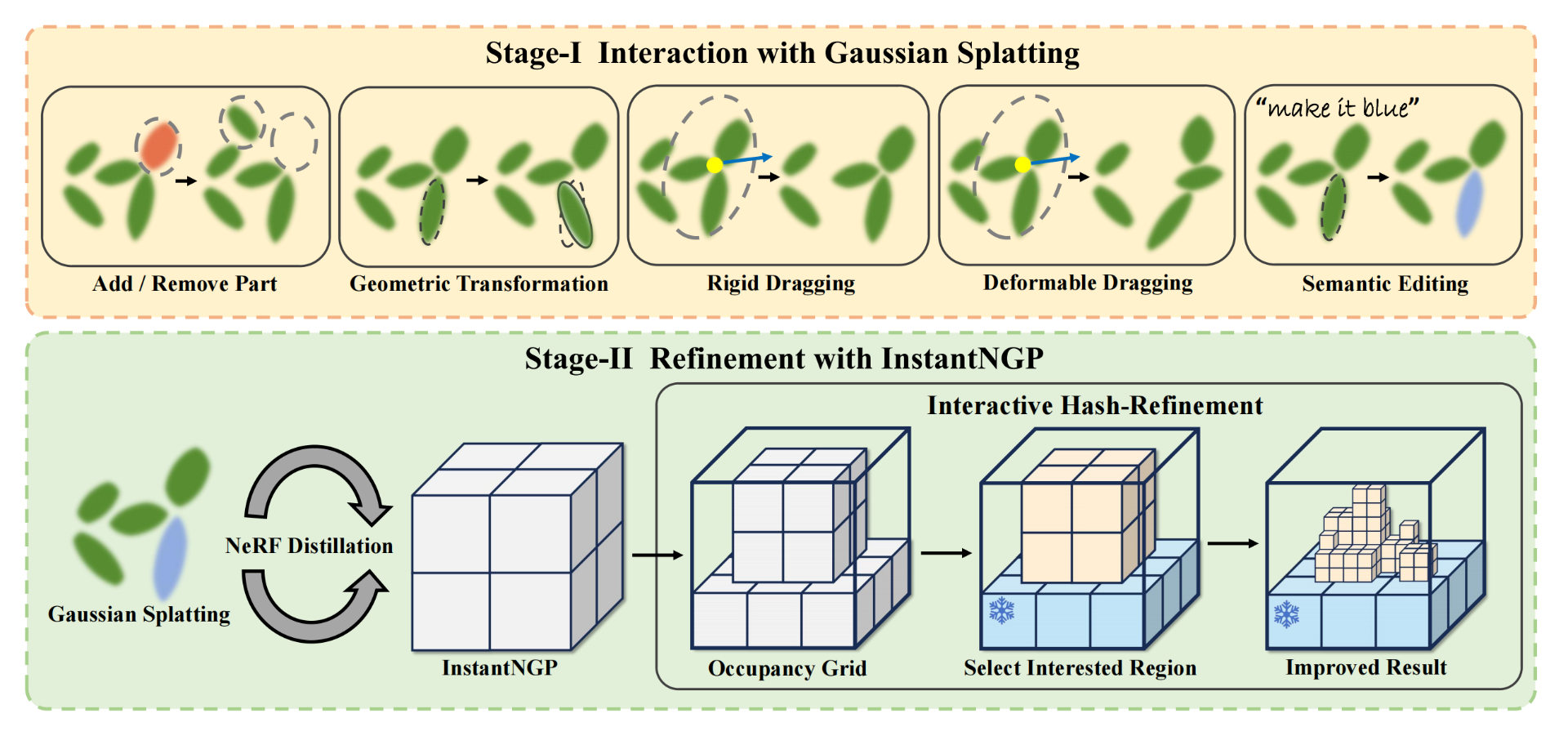
它提供了一种非常灵活的方式来创造和修改3D内容。你可以添加、移除组件来对模型进行各种组合,类似乐高搭建,还可进行可变形和刚性拖动等操作。
也可以通过文本控制。
而且用户交互的实时反馈,能够即时看到你的操作如何影响最终的效果。
通过3D技术,Project Neo能够为原本平面的2D图像添加立体效果。
能够快速的为图标、动画插图创建独特的3D形状。
通过简单的操作,你可以在几分钟内完成图标、插图设计,极大地提高了工作效率。
Project Neo与Adobe的桌面和网络应用程序无缝集成,支持无缝导出高质量的SVG文件和像素完美的图像。
PhysDreamer:由多所大学(包括麻省理工学院、斯坦福大学、哥伦比亚大学和康奈尔大学)合作开发。
真实的对象交互对于创建沉浸式虚拟体验至关重要,但合成真实的 3D 对象动态以响应新颖的交互仍然是一项重大挑战。与无条件或文本条件动力学生成不同,动作条件动力学需要感知对象的物理材料属性,并将 3D 运动预测建立在这些属性(例如对象刚度)的基础上。
ZeST(Zero-Shot Material Transfer)是一种基于零样本的方法
介绍 ZeST,这是一种零样本、免训练的方法,用于
(a) 图像到图像的材料传输。
(b) ZeST 可以轻松扩展以在单个图像中执行多种材质编辑
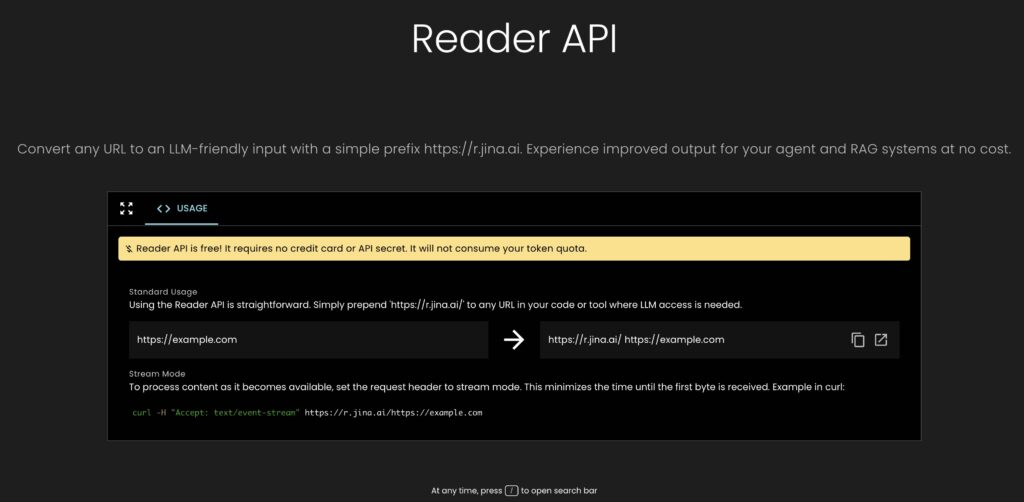
只需要输入任意URL,Jina-ai/Reader就能格式化和清理URL里的内容,确保LLM接收到的输入更加规范和易于处理。
操作非常简单,只需要在任意URL前+前缀 https: //r.jina.ai/ 即可实现转换,并且以流式方式处理数据
Android Studio提供了一站式解决方案,集成了代码编辑、编译、调试和测试的工具,减少了开发者在不同工具间切换的需要。
支持自动编写代码、语法高亮和代码重构
他可以将代码库转化为类似维基百科的文章,使得非专业人士也能理解复杂的代码结构。
而且当源代码发生变化或用户通过指令更新时,文档会自动刷新,确保实时性。
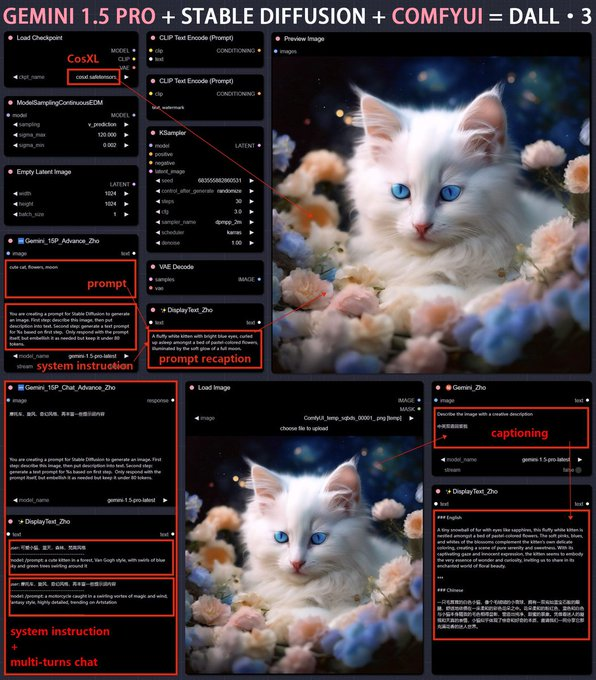
开源社区一直以来的梦想:DALLE3交互和提示词生成能力 + 无数SD模型出图能力,这不巧了嘛
百万上下文、多模态+多轮对话、打标/反推
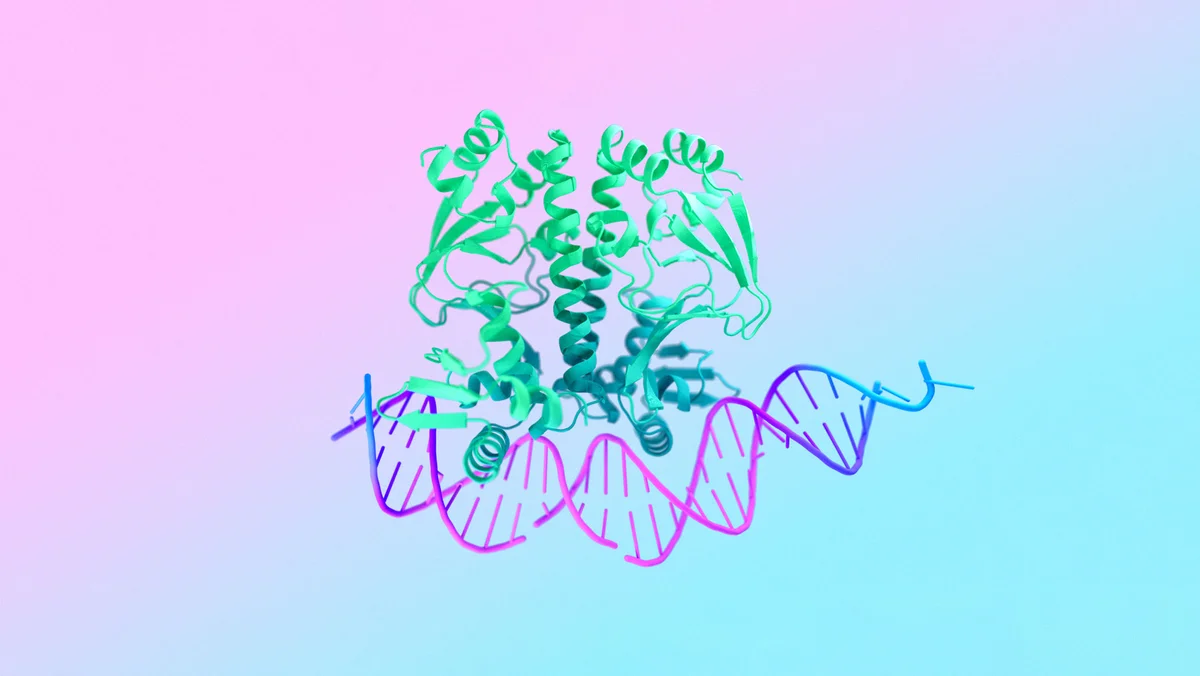
能够预测所有生命分子结构和相互作用 AI 模型
该模型能够生成蛋白质、DNA 和其他分子的 3D 结构,并揭示它们如何组合在一起。
该模型还能够模拟影响细胞健康的化学变化,并检测可能导致疾病的异常。
AlphaFold 3 将为全球科学研究人员和机构免费开放。它的高精度和新一代架构可支持药物发现和生物学的突破性进展。