
Google推出开源视觉语言模型:PaliGemma
支持图像视频等多种视觉语言任务
包括支持图像和短视频字幕、视觉问答、图像文本理解、物体检测文件图表解读、图像分割等任务。
PaliGemma 模型包含 30 亿(3B)个参数,结合了 SigLiP 视觉编码器和 Gemma 语言模型。
支持图像视频等多种视觉语言任务
包括支持图像和短视频字幕、视觉问答、图像文本理解、物体检测文件图表解读、图像分割等任务。
PaliGemma 模型包含 30 亿(3B)个参数,结合了 SigLiP 视觉编码器和 Gemma 语言模型。

Prettygraph 是一个基于 Python 的 Web 应用程序,由 @yoheinakajima 开发,用于演示文本到知识图生成的
新 UI 模式。该项目是一个快速破解项目,并不是要成为一个强大的框架,而是一个简单的 UI 想法,用于在生成知识图时动态突出显示文本输入。

能够应对各种类型的线条艺术作品,无论是手绘草图、不同的 ControlNet 线预处理工具,还是由模型生成的轮廓,都能高精确性和稳定地处理。
一个重要特点是其泛化能力极强,无需针对不同的线预处理工具更换不同的 ControlNet 模型。

DeepFaceLive 建立在 DeepFaceLab 的基础上,后者为当前领先的面部交换框架,能够产生接近电影质量的面部合成效果,提供高保真的视觉体验。
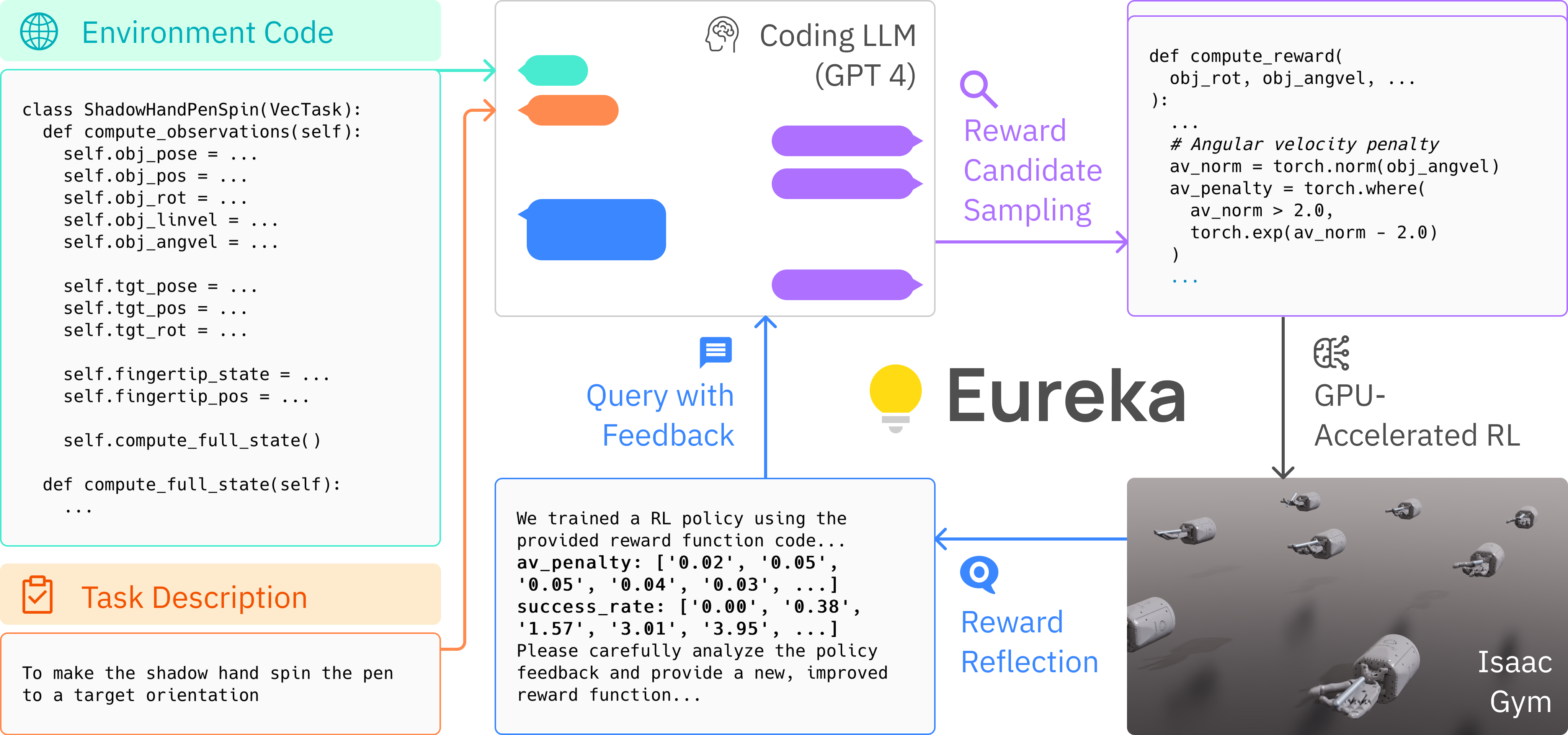
Eureka 弥合了高级推理(编码)和低级运动控制之间的差距。它是一种“混合梯度架构”:一个黑盒,仅推理 LLM 指示一个白盒,可学习的神经网络。外循环运行 GPT-4 来细化奖励函数(无梯度),而内循环运行强化学习来训练机器人控制器(基于梯度)。

能够生成细节丰富、内容多样的图像和视频,同时保持角色身份和服饰的一致性。
可以帮助生成长篇漫画或者带连续剧情的视频。
与IP-Adapter和PhotoMaker等方法相比,StoryDiffusion在保持角色一致性的同时,还能更好地控制文本提示,生成与描述更匹配的图像和视频。

可以将你直播说话时候的声音变声其他各种角色和性别的声音。
还能调整音调、音调动态和混响等参数,塑造个性化的声音。
也可以将你声音与任何角色的声音以任意比例混合,创造出新的声音 。

支持文字生成模型、图片生成模型,分辨率512×512,5秒内即可生成。
3D内容创作在质量和速度方面都取得了显着进步。尽管当前的前馈模型可以在几秒钟内生成 3D 对象,但其分辨率受到训练期间所需的密集计算的限制。在本文中,介绍了大型多视图高斯模型 (LGM),这是一种新颖的框架,旨在从文本提示或单视图图像生成高分辨率 3D 模型。
Audio Native 是一个嵌入式音频播放器,可以自动为网页内容生成语音
只需插入一段简短的代码,即可插入到任何网页和内容中,自动为内容生成语音旁白。
您现在正在阅读的这一行的上方有一个播放按钮。按播放键,您可以收听由 ElevenLabs 语音自动生成的这篇文章的旁白。我们将这种嵌入式语音播放器称为“Audio Native”。

包括「眼動追蹤」、「音樂觸覺」和「聲音捷徑」
Apple 今日宣佈將於今年稍晚推出全新輔助使用功能,包括「眼動追蹤」,一種讓身體障礙使用者只用眼睛即可控制 iPad 和 iPhone 的方式。此外,「音樂觸覺」將為聾人與聽力障礙使用者提供一種用 iPhone 觸感引擎體驗音樂的新方式;「聲音捷徑」將讓使用者能藉由發出自訂聲音來執行任務;「車輛移動提

Copilot+ PC 是迄今为止最快、最智能的 Windows PC。凭借强大的新型芯片,能够实现令人难以置信的 40+ TOPS(每秒万亿次操作)、全天的电池寿命以及对最先进人工智能模型的访问,Copilot+ PC 将使您能够完成任何其他 PC 上无法完成的事情。通过 Recall 轻松查找并记住您在 PC 中看到的内容,使用 Cocreator 直接在设备上近乎实时地生成和优化 AI 图像,并通过实时字幕消除语言障碍,将 40 多种语言的音频翻译成英语。

配备人工智能瞄准步枪的机器狗接受美国海军陆战队特种部队评估
正在接受审查的四足动物具有自动瞄准系统,但需要人工监督才能开火。
据战区报道,美国海军陆战队特种作战司令部 (MARSOC) 目前正在评估 Ghost Robotics 开发的新一代机器人“狗”,该机器人“狗”有可能配备国防科技公司 Onyx Industries 的枪支系统。