科学家通过机器学习模型,为脓毒症治疗“争分夺秒”
这项研究的结果表明,个性化的抗生素治疗时间建议模型可以帮助医生更好地决策,避免治疗延迟或过早给药带来的潜在危害,同时降低患者的死亡率和医疗成本。
这项研究的结果表明,个性化的抗生素治疗时间建议模型可以帮助医生更好地决策,避免治疗延迟或过早给药带来的潜在危害,同时降低患者的死亡率和医疗成本。
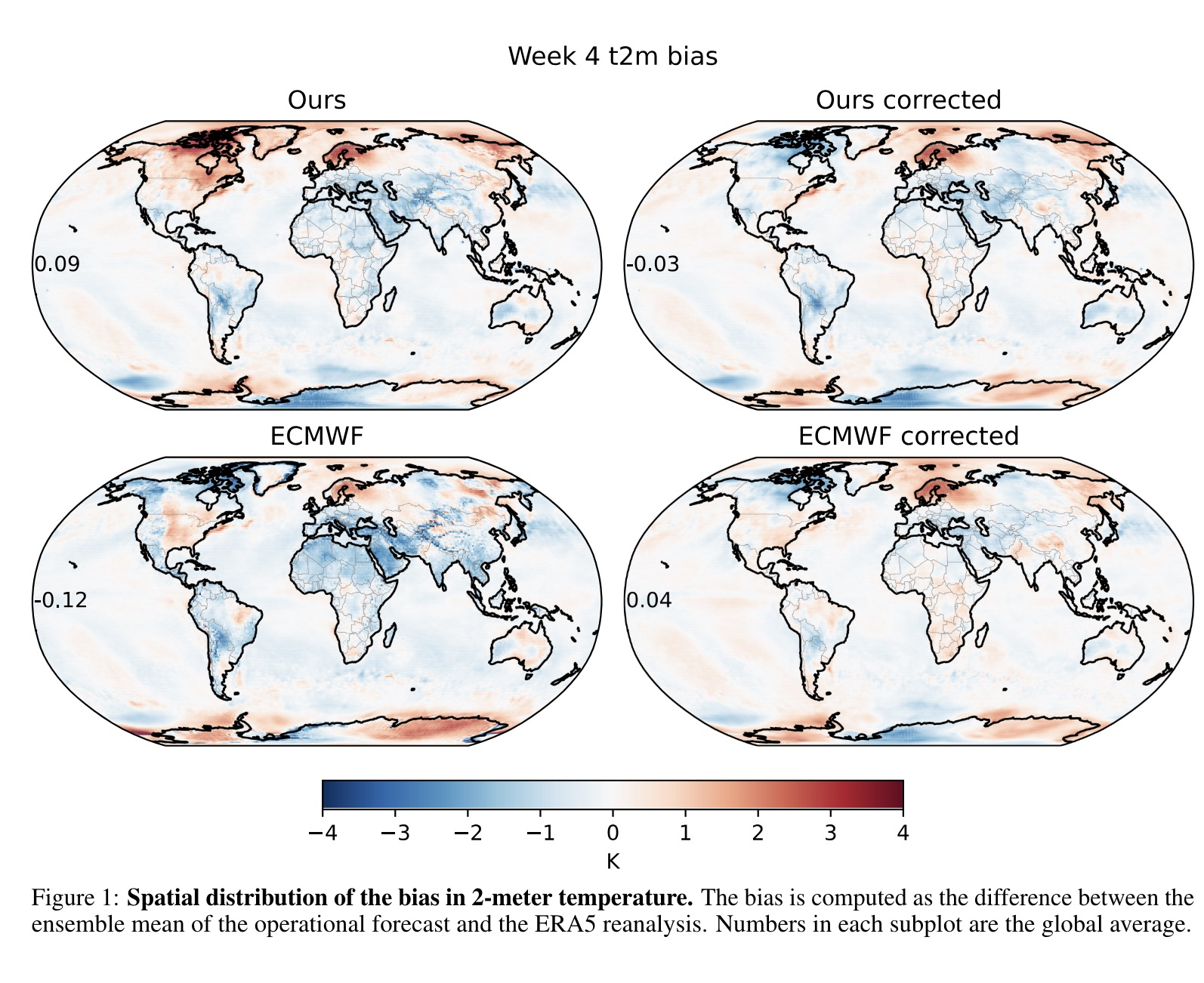
能准确预报未来 30 天天气情况
该模型基于微软 Start 团队近日的最新研究成果,结合了 5 种不同的人工智能模型和 3 种深度学习架构,并利用 了过去数十年的天气数据进行训练,能够准确预测 30 天内的天气预报。
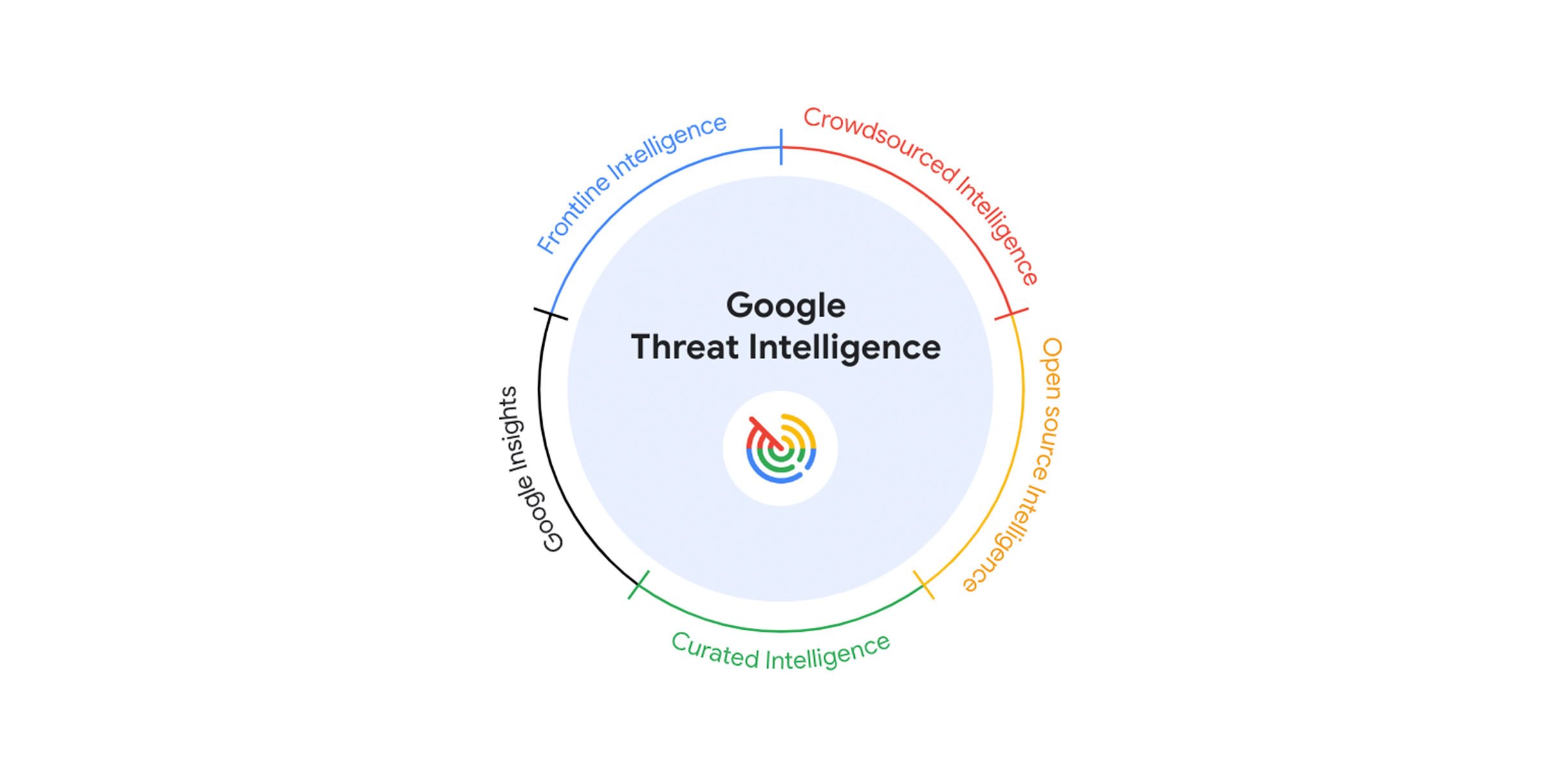
Google 威胁情报的用途示例:
识别和防御网络钓鱼攻击:
假设一家企业遭遇了钓鱼电子邮件攻击,员工可能收到包含恶意链接或附件的电子邮件。
Google Threat Intelligence可以利用其庞大的电子邮件监控网络,检测并阻止这些恶意邮件的传播。
OpenVoice,这是一种多功能的即时语音克隆方法,只需要参考说话者的一个简短的音频剪辑即可复制他们的声音并生成多种语言的语音。除了复制参考说话者的音色之外,OpenVoice 还可以对语音风格进行精细控制,包括情感、口音、节奏、停顿和语调。
CoreNet 是一个深度神经网络工具包,允许研究人员和工程师为各种任务训练标准和新颖的小型和大型模型,包括基础模型(例如 CLIP 和 LLM)、对象分类、对象检测,和语义分割。
Apple 使用 CoreNet 进行的研究工作
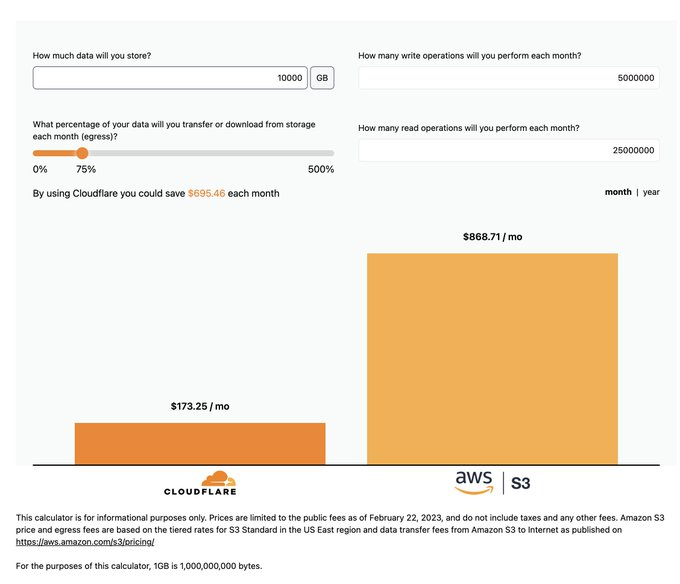
对象存储有时也称为 Blob 存储,可以存储任意的大型非结构化文件。我们常用的有 AWS 的 S3、阿里云的 OSS、腾讯云的 COS、华为云的 OBS,都是对象存储,他们都可以为我们提供延迟一致、持久性高和容量无限的服务,免去了我们本地文件系统的共享、备份等痛点。
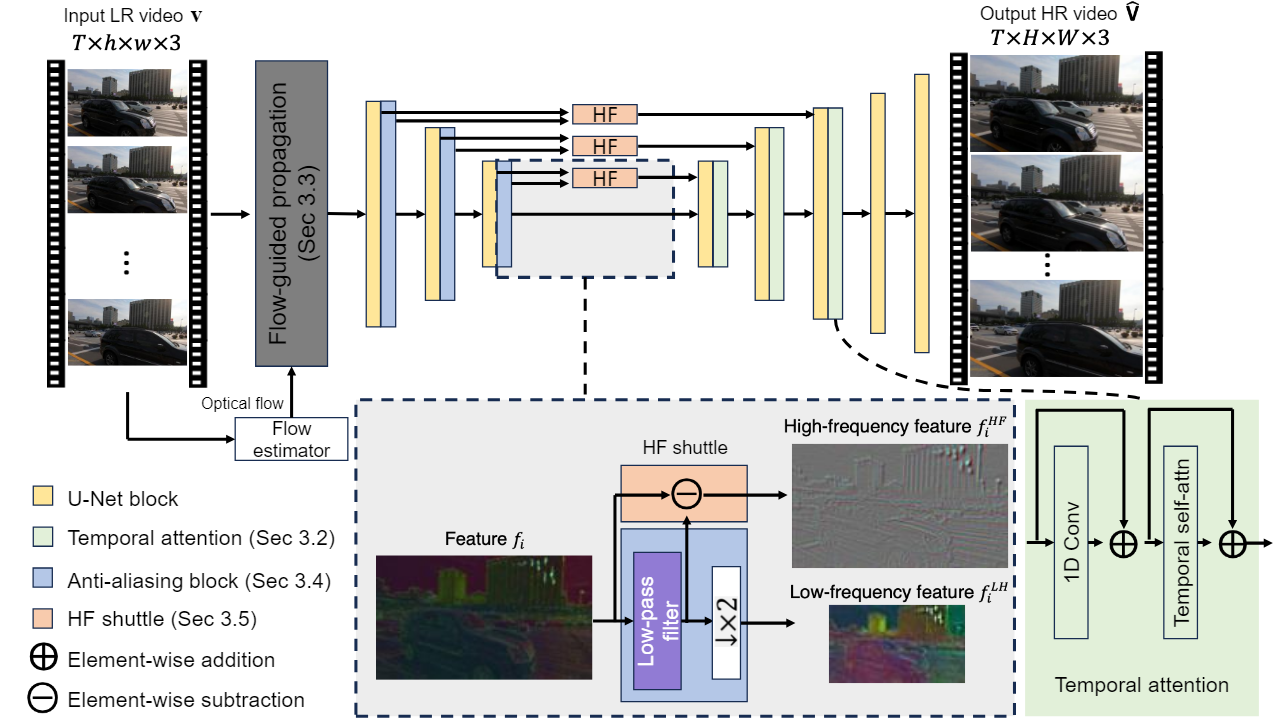
VideoGigaGAN,这是一种新的生成 VSR 模型,可以生成具有高频细节和时间一致性的视频。
VideoGigaGAN 基于大规模图像上采样器——GigaGAN。简单地通过添加时间模块将 GigaGAN 扩展到视频模型会产生严重的时间闪烁。
确定了几个关键问题,并提出了显着提高上采样视频的时间一致性的技术。
一切从任务开始:从一个 GitHub Issue、Pull Request 或仓库中打开 GitHub Copilot Workspace。(截图显示了 octoacademy 仓库中的一个 Issue。)
中国机器人公司LimX Dynamics展示了双足平衡和导航技术已经发展到了多么高的水平
专为人体模拟而设计的机器人开发商。公司产品主要专注于运动智能和腿式机器人的研发和制造,包括仿人双足和四足机器人及相关解决方案,应用在工业检测、物流配送、特种作业、家居服务等领域,为为客户提供高品质、创新的产品。
微软在 Bing 图片搜索中已引入视觉搜索选项,通过识别图片中的内容,并扩展显示相关的图片资源,实现以图搜图功能。
微软计划将必应的图片搜索引入到聊天平台上,增强用户参与度并提供更全面的搜索结果。
涵盖了机器学习系统的设计、构建、投产、优化、运转和维护工作。
详细的学习内容有:
• 机器学习基础:涵盖机器学习的基本原理和方法。
• 特征工程:探讨如何有效地处理和转换数据,以提高模型性能。
Synthesia 是一个基于人工智能的 AI 视频生成制作平台,利用深度学习算法来合成逼真的人脸表情和口型,从而让虚拟的人物能够根据用户输入的文字来说话。用户只需要在网页上输入文字,就可以生成一段专业、有说服力的视频。
Expressive-1能根据文本自动做出皱眉、微笑、皱眉头等表情。
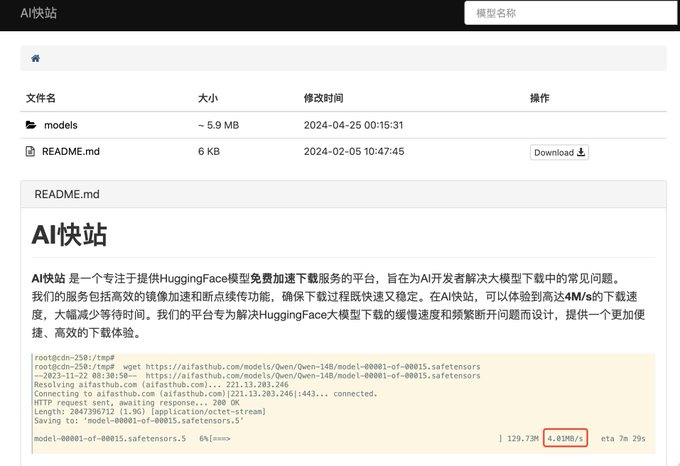
AI快站的特点:
高速下载:提供的模型下载速度相对较快,减少等待时间
模型资源丰富:涵盖大部分常用开源模型,更新速度快
支持断点续传:提供下载器,大模型下载时遇到中断也不再是问题
这款模型被视为国内首个达到Sora级别的视频模型。
Vidu 不仅能模拟真实物理世界,还具备丰富的想象力,支持多镜头生成和高时空一致性。
Vidu 模型融合了 Diffusion 与 Transformer 技术,创新性地开发了 U-ViT 架构。