Vercel 上一键部署babyAGI
Morphic 只用 OpenAI 与搜索服务 @tavilyai 的 API 就能整得像模像样,换成 Gemini 与 Google Search 的 API 也一样能行。感觉 Perplexity 给大家带了 AI 时代的问答式搜索体验后,这种模式就会被大家学去强化自己的功能了
Morphic 只用 OpenAI 与搜索服务 @tavilyai 的 API 就能整得像模像样,换成 Gemini 与 Google Search 的 API 也一样能行。感觉 Perplexity 给大家带了 AI 时代的问答式搜索体验后,这种模式就会被大家学去强化自己的功能了
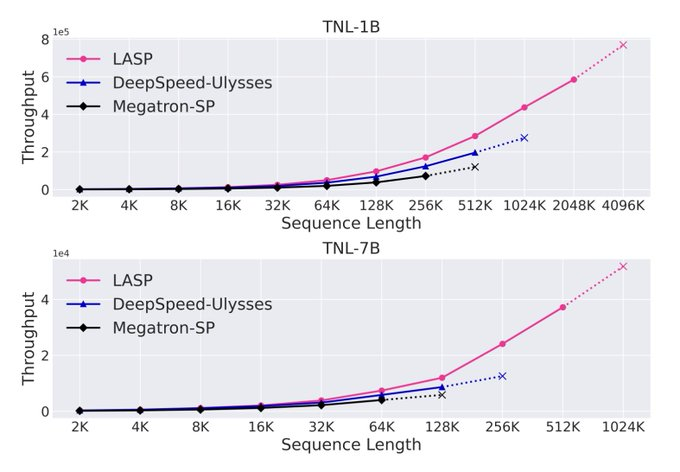
上海人工智能实验室和 TapTap 的研究人员提出了线性注意序列并行 (LASP) 技术,该技术优化了线性 Transformer 上的序列并行性。它采用点对点 (P2P) 通信在节点内或节点间的 GPU 之间进行有效的状态交换。 LASP 最大限度地利用了线性注意力中的右积核技巧。重要的是,它不依赖于注意力头分区,使其适用于多头、多查询和分组查询注意力。
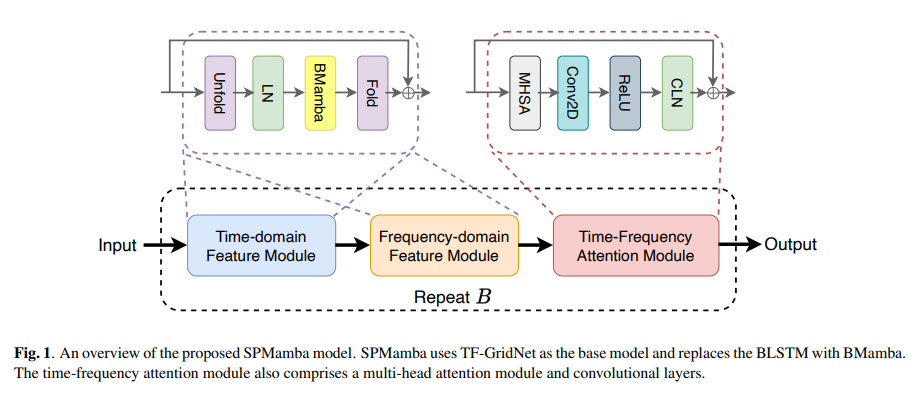
清华大学BNRist计算机科学与技术系的研究人员介绍了SPMamba,这是一种植根于SSM原理的新颖架构。通过引入平衡效率和效果的创新模型,围绕语音分离的讨论得到了丰富。 SSM 体现了这种平衡。通过巧妙地整合 CNN 和 RNN 的优势,SSM 满足了对能够在不影响性能的情况下高效处理长序列的模型的迫切需求。
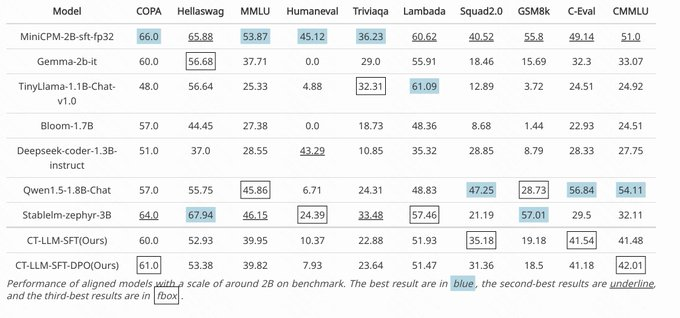
CT-LLM从头开始构建,与传统方法不同,它主要包含中文文本数据,利用了总量高达1200亿Token的庞大语料库,其中800亿是中文Token,300亿是英文Token,还有100亿是代码Token。

VAR首次使GPT风格的AR模型在图像生成上超越了Diffusion transformer。
同时展现出了与大语言模型观察到的类似Scaling laws的规律。
在ImageNet 256×256基准上,VAR将FID从18.65大幅提升到1.80,IS从80.4提升到356.4,推理速度提高了20倍

准备数据并训练3DGS模型。我们使用 NeRF 和 Mip-NeRF 360 提供的 Blender、LLFF 和 360° 场景数据集评估了我们的方法。您可以从各自的项目页面下载它们。
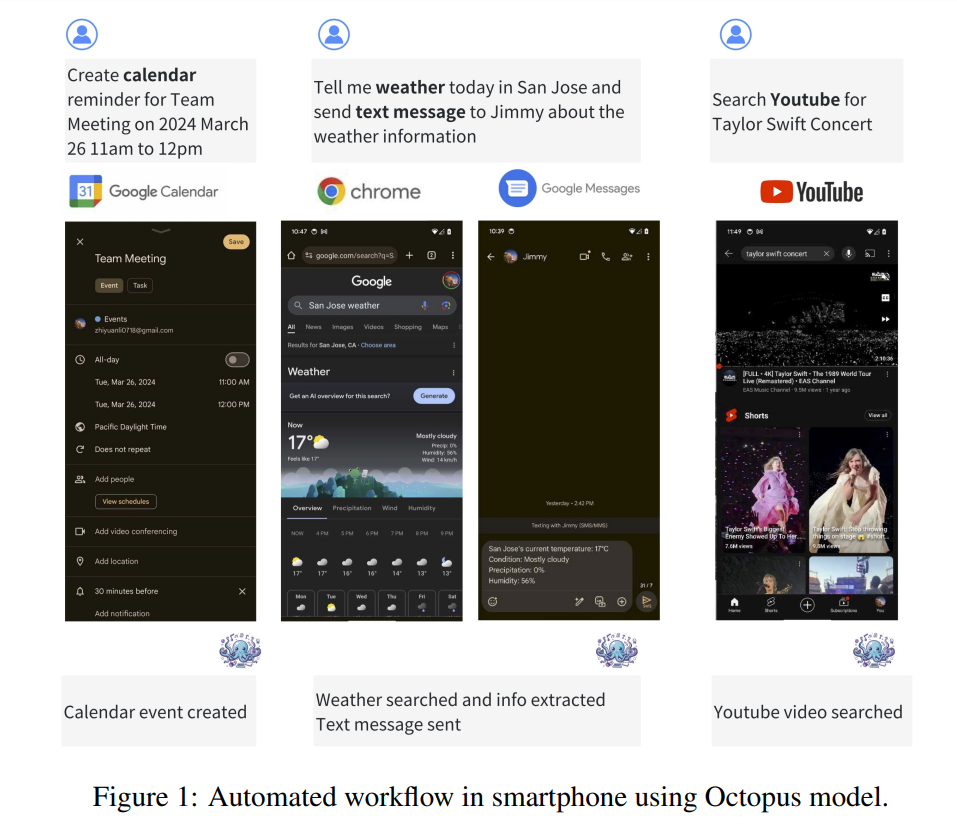
斯坦福大学的研究人员推出了 Octopus v2,这是一种先进的设备上语言模型,旨在解决与当前LLM应用程序相关的普遍存在的延迟、准确性和隐私问题。与之前的型号不同,Octopus v2 显着减少了延迟并提高了设备上应用程序的准确性。其独特之处在于通过功能标记进行微调的方法,可以实现精确的函数调用,在效率和速度上超越GPT-4,同时将上下文长度大幅削减95%。

来自 Google DeepMind、麦吉尔大学和 Mila 的研究人员推出了一种突破性的方法,称为深度混合 (MoD),它不同于传统的统一资源分配模型。 MoD 使 Transformer 能够动态分配计算资源,重点关注序列中最关键的标记。该方法代表了管理计算资源的范式转变,并有望显着提高效率和性能。

Octopus-V2-2B是由斯坦福大学Nexa AI开发专为Android API的功能调用定制。
采用了一种独特的功能性标记策略,超越了基于RAG的方法,特别适用于边缘计算设备。
比Llama7B + RAG方案快36倍,性能优于 GPT-4,延迟时间小于 1 秒。

允许模型与外部系统和数据进行交互
使用Tool use (function calling)功能,Claude不仅能够生成文本或回答问题,还能实际调用外部定义的函数或工具来执行特定操作,如获取当前的天气信息、执行数学计算等。

模型是基于光级数据构建的 Relightable Hands 的高保真通用先验。它概括为新颖的观点、姿势、身份和照明,从而可以通过手机扫描进行快速个性化

WAS26:这个模型是在Banodoco Discord平台分享的艺术作品中挑选出来进行训练的。
Smoooth:专门针对那些动作流畅的视频进行训练。
LiquidAF:这个模型则是在液体模拟的基础上训练的