IT/AI知识库: 跟踪最新的IT/AI类资讯



适用于任何分辨率特征的模型无关框架
深层特征是计算机视觉研究的基石,它捕获图像语义并使社区即使在零样本或少样本情况下也能够解决下游任务。
然而,这些功能通常缺乏空间分辨率来直接执行分割和深度预测等密集预测任务,因为模型会积极地池化大区域的信息。

可以直接通过文字描述让任何静态图动起来
而且能做各种动作,跳舞什么的都是小case…
最牛P的是,他们的模型能能理解真实世界的物理运动原理,所以出来的视频很真实。
不仅如此,它还能直接文字生成视频,进行各种角色混合和动作替换…

令人兴奋的新研究警报-𝐏𝐢𝐱𝟐𝐏𝐢𝐱-𝐓𝐮𝐫𝐛𝐨
这些条件 GAN 能够采用文本到图像模型(例如 SD-Turbo),通过一步(A100 上为 0.11 秒,A6000 上为 0.29 秒)进行配对和不配对图像转换。尝试我们的代码和 @Gradio 演示。

Creatie这个AI-UI设计工具
有点强啊,做的相当完整,基本上可以当做一个加上了 AI 功能的 FIgma。
而且全部都是免费的,AI 能力也很强,选择区域输入需求直接就会展示对应备选的组件,你可以自己拼装和修改,还能使用自己的设计系统。


Open-Sora开源了
包括完整的文本到视频模型训练过程、数据处理、训练细节和模型检查点。
该项目由@YangYou1991 团队开发 这是 OpenAI Sora 在视频生成方面的开源替代方案。
可以在仅仅3天的训练后生成2~5秒的512×512视频。

基于真实果蝇行为训练的人工智能模型
通过结合解剖学精确的模型、物理模拟器和基于真实果蝇行为训练的人工智能模型
@HHMIJanelia 和 @GoogleDeepMind
的科学家创造了一种计算机化昆虫,它能够像真实果蝇一样,在复杂的轨迹上行走和飞行。

OpenRouter:大语言模型“路由器”
Openrouter提供了一个统一的接口,通过这个接口,你可以直接访问和使用几十种AI模型
你可以使用这个接口对各种模型进行测试和比价,选择最适合自己的,避免了东奔西跑
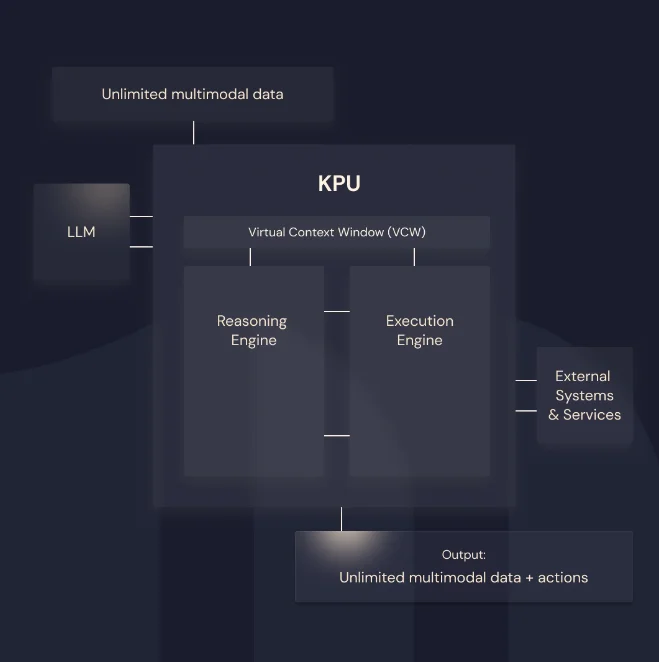
Maisa推出的一种新型技术框架:KPU
通过将推理与数据处理分开,优化和提升了大语言模型处理复杂任务的能力。
使用KPU后,在多个基准测试和推理任务中GPT-4 、Claude 3 Opus等模型等能力得到大幅提升,都超越了没有使用KPU的原模型本身!


Google也弄了一个:一张照片+音频即可生成会说话唱歌的视频的项目
Google也弄了一个:一张照片+音频即可生成会说话唱歌的视频的项目
VLOGGER:基于文本和音频驱动,从单张照片生成会说话的人类视频

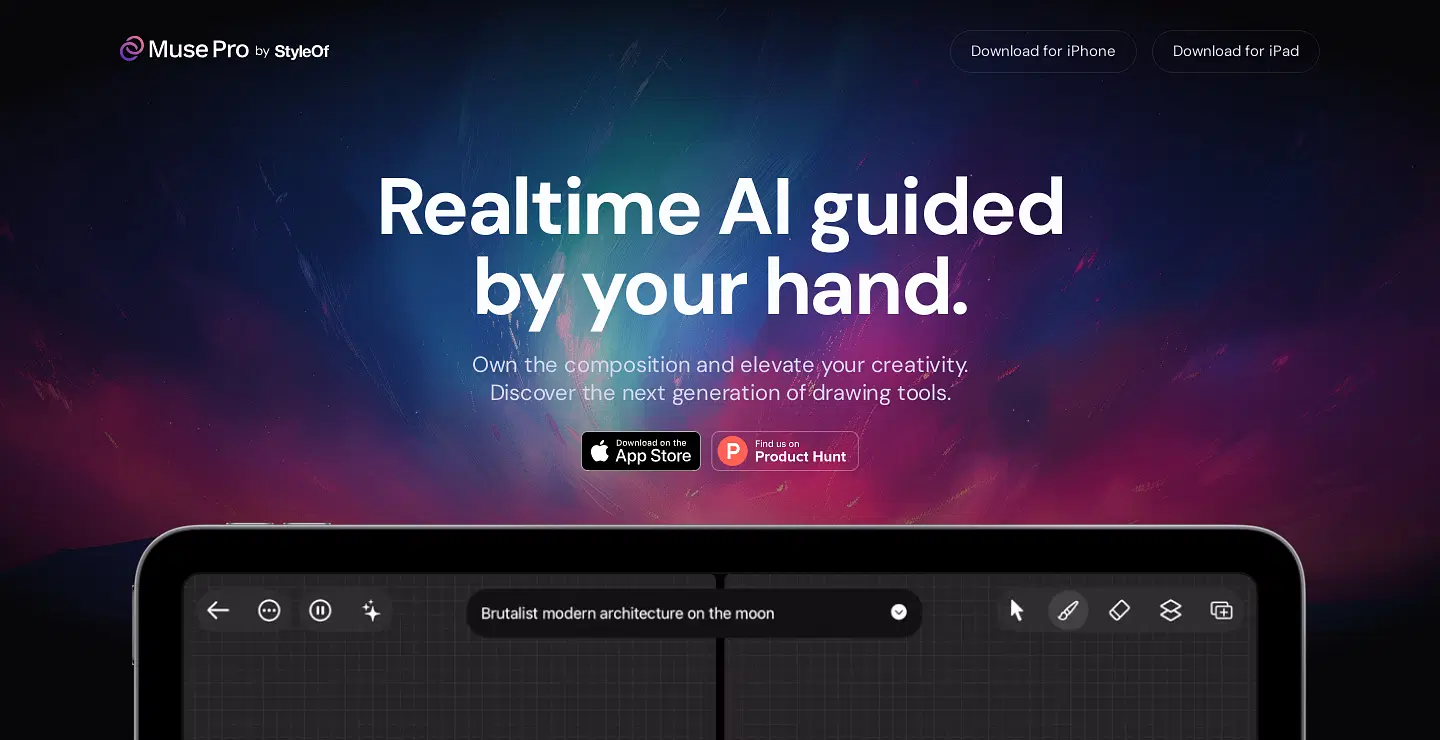
Musepro这个iPad应用看起来是真的可用
与其他画笔快速生成图片的尴尬应用不同,Musepro这个iPad 应用看起来是真的可用。借助 iPad 搭配的 Apple Pencil以及内置的丰富笔刷,应该可以极大的提高画图效率。

DexCap开源版经济版的Optimus
成本大约 $3,600,可以用来记录真人手指的动作来训练机器人进行灵活的操作。
并且不是遥控操作,它有一对特制的手套,通过各种传感器捕捉手部运动的精确数据。与传统基于视觉的运动捕捉技术相比,这些手套不会因为视线遮挡而失效,更适合在日常活动中使用。