LaVague一个开源的浏览器自动化操作Agents
通过提供一个将自然语言查询转化为 Selenium 代码的引擎,LaVague 可让用户或其他人工智能轻松实现自动化,轻松表达网络工作流程并在浏览器上执行。
通过提供一个将自然语言查询转化为 Selenium 代码的引擎,LaVague 可让用户或其他人工智能轻松实现自动化,轻松表达网络工作流程并在浏览器上执行。
Human to Humanoid (H2O)由卡内基梅隆大学的研究团队开发,它允许人们通过一个简单的RGB摄像头让机器人实时模仿人的全部动作。
在你输入的指令后面加上 –cref URL,URL是你选择的角色图像的链接。
你还可以用 –cw 来调整参照的“强度”,范围从100到0。
默认的强度是100 (–cw 100),这时会参考人物的脸部、发型和衣着。
如果设置为强度0 (–cw 0),那么系统只会关注脸部(这对于更换服饰或发型很有帮助)。
能够通过文字提示创造出适用于各种场景的声音和音效
如游戏中的射击和跳跃声音、动画中的雨声环境以及视频中的地铁到站声音等。
基于 Llama2,从头开始训练。
许可 – 开源。
优化在 CPU 上运行。 🔥
高度可控,可选择节奏、和弦进行、小节范围等等!
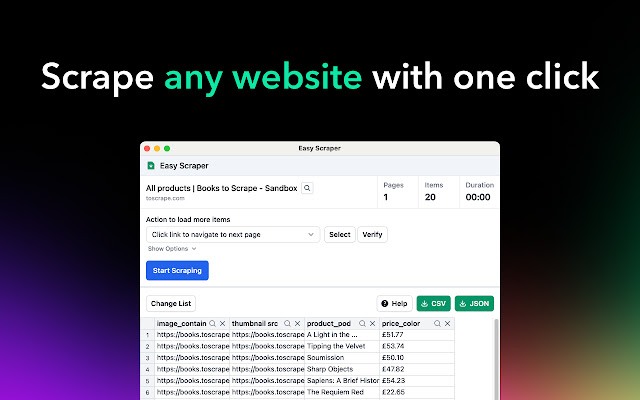
Easy Scraper:一个在Chrome扩展,只需点击一下即可抓取任何网站的内容
支持导出CSV或JSON格式可以直接丢到ChatGPT里面进行简单分析,也可以作为GPTs的知识库。
这个工具目前完全免费,原因是开发者将在整个三月份参加沉默冥想闭关,没有时间添加付费计划。
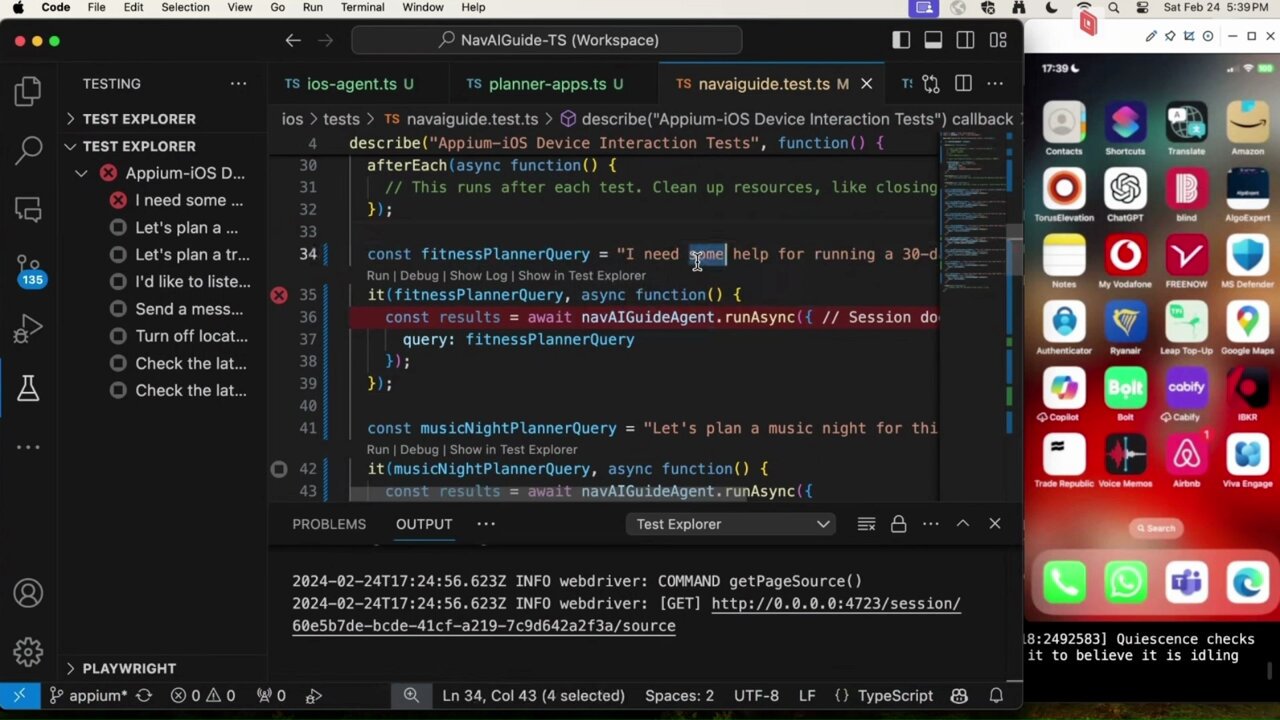
这证明了 GPT-4V 作为通用移动 AI 代理的出色程度 – 无需任何微调或基础,仅通过与启用 JSON 模式的文本模型集成即可。
建议观看此演示,了解(可能)令人惊叹的因素以及使用 NavAIGuide 在 iOS 17 上的结果,
NavAIGuide 是 LLMs 的移动和 Web 导航代理框架
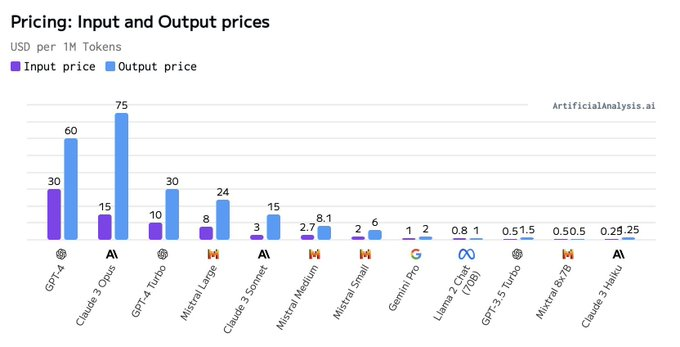
Anthropic太牛了。Claude-3 发布的两件事:
领域专家基准。我对饱和的 MMLU 和 HumanEval 不那么感兴趣。Claude特别挑选了金融、医学和哲学作为专家领域并报告性能。我建议所有 LLM 模型卡都遵循这一点,这样不同的下游应用程序就会知道该期待什么。
拒绝率分析。LLMs’对无辜问题过于谨慎的回答正在成为一种流行病。Anthropic 通常处于极端安全的一端,但他们认识到了这个问题,并强调了他们在这方面的努力。好极了!
OpenReplay是一个自托管的会话回放和分析开源工具
可以让开发人员像看电影一样回看用户如何与你的产品互动,包括他们点击了什么,输入了什么,甚至在遇到问题时他们的屏幕上发生了什么。
帮助你优化用户体验和提高产品性能。
设置好语音,点击播放按钮,可以自动朗读GPT生成的内容
ChatGPT 的数据分析Data Analysis 将升级到V2 版本,功能更加强大!
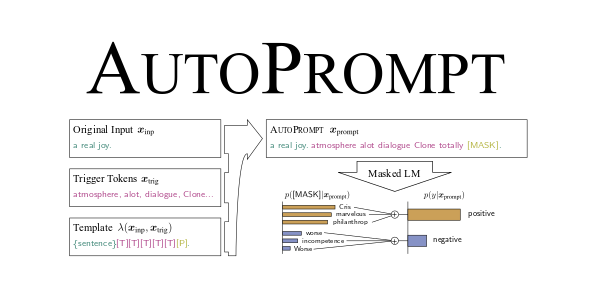
专为优化提示而设计的框架,通过不断的迭代过程,AutoPrompt 构建了一个包含各种挑战性边缘案例的数据集,用于测试和优化提示。
它能根据用户的具体意图自动生成定制化的提示,确保生成的提示能够精准地满足用户的需求。