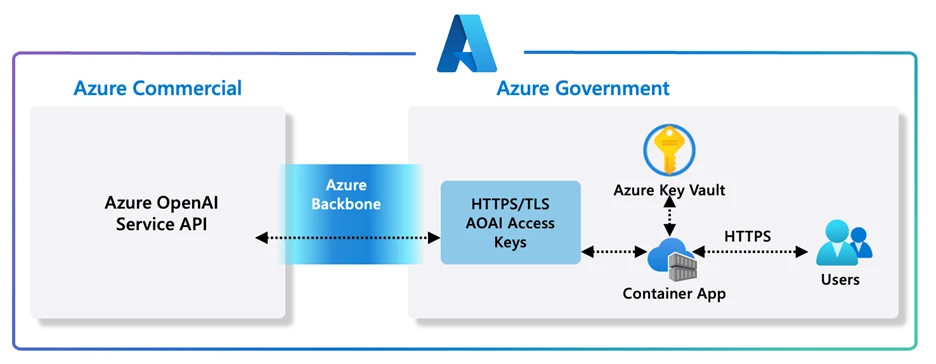
AzureOpenAIService宣布了一系列新功能
包括公开预览的Assistants API、新的文本到语音(TTS)功能、即将推出的GPT-4 Turbo和GPT-3.5 Turbo模型更新、新的嵌入模型以及微调API的更新。
与之前的聊天完成API相比,Assistants API能够记住之前的对话内容,创建持久化和无限长的线程。
Assistants API 是一项由 Azure OpenAI 提供的新服务,它旨在帮助开发者在他们的应用程序中更容易地创建高质量的人工智能助手体验。
包括公开预览的Assistants API、新的文本到语音(TTS)功能、即将推出的GPT-4 Turbo和GPT-3.5 Turbo模型更新、新的嵌入模型以及微调API的更新。
与之前的聊天完成API相比,Assistants API能够记住之前的对话内容,创建持久化和无限长的线程。
Assistants API 是一项由 Azure OpenAI 提供的新服务,它旨在帮助开发者在他们的应用程序中更容易地创建高质量的人工智能助手体验。
该机器人能够完全独立地执行任务,无需人类远程操控或通过预设脚本。
所有动作都是实时通过神经网络计算得出。
机器人基于视觉的端到端神经网络直接从图像中学习如何控制其动作,包括驾驶、操纵手臂和抓取器、控制躯干和头部等。
注册时可以选择退出训练数据
Gemini Ultra 中 Imagen 2 生成的所有图像都应用了数字水印(但你看不到它)
Ultra 比 Gemini Pro 更能胜任复杂任务,例如编码、逻辑推理以及遵循更长/更详细的指令。
Vercel为AI应用提供了丰富的产品基础设施,从增强客户服务流程的聊天机器人到带有语义搜索的推荐系统、检索增强生成(RAG)和生成图像服务…
为了让这一切更加简单,Vercel还
提高了长格式音频的生成效率,克服了固定大小输出的限制,允许生成可变长度的音频。
通过潜在扩散模型和时间条件化,实现了对生成音频长度的精细控制,同时保持了计算效率。
通过驾驶舱进行直接操控,用户可以打开舱盖,进入驾驶舱,与机器人合为一体进行操控。
26个关节自由度,有机器人 / 车辆两种模式。
驾驶舱内部设有四面显示屏,用于显示机器人外部的摄像头画面。
它能够自动识别和定位图像中的各种对象
YOLO-World在速度和准确性方面都优于许多最先进的方法。
零样本检测能力,无需训练即可进行实时目标检测,即便某些物品之前没有见过。
卡内基梅隆大学和苏黎世联邦理工学院的研究人员正在帮助机器人变得敏捷、快速和安全。
新框架允许以近 7 英里/小时的速度在杂乱的空间中导航而不会发生碰撞。
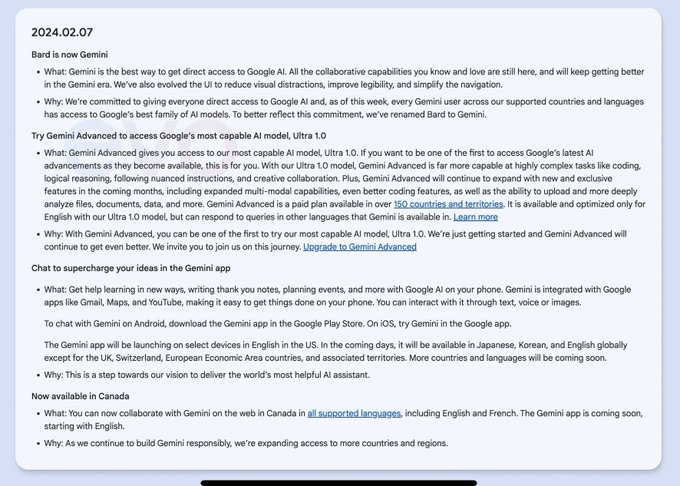
Google的Gemini Ultra模型将在2月7号上线,同时Google聊天机器人Bard将更名为Gemini。
Gemini将开启付费计划:Gemini Advanced
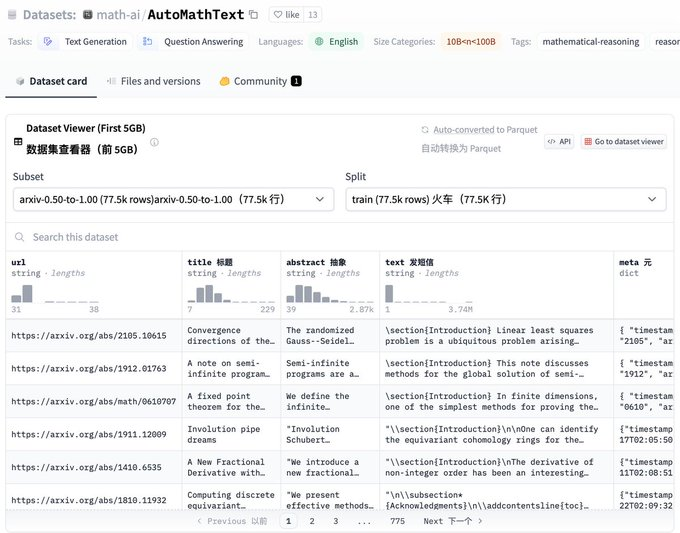
数据集包含来自不同来源的数据,如arXiv的科学论文、编程代码片段以及网页数据,数据已经经过特定的过滤和处理,以适应数学推理、推理训练和微调等多种应用场景。
支持文本生成和问答等任务,特别适合用于开发和测试能够理解和生成数学相关内容的模型。
1、物体的准确放置:确保新插入的物体在视频中的位置看起来自然、合理,与视频场景的其他元素和空间布局协调一致。
2、光照和阴影的真实模拟:通过分析和模拟视频中的光照条件及其对物体的影响,生成看起来自然的阴影和光照效果,增强物体与环境的整合度。
3、风格一致性:应用风格转换技术,调整和优化视频的视觉效果,使得插入的物体在色彩、纹理等方面与背景视频保持一致,进一步提升整个视频的真实感和观感质量。
模型有1.2亿个参数,经过了10万小时的语音数据训练。
专注英语情感演讲
跨语言语音克隆
支持美国和英国声音的零样本克隆
支持长篇内容语音合成
它提供了一个拖放式的界面,允许用户轻松地创建复杂的图像处理工作流,无需编写任何代码。
你只根据需要将不同的功能块(如图像编辑功能和AI模型)组合在一起,即可实现个性化的图像自动化处理。
该工具主要解决在电商领域遇到的批量处理图片问题。