IT/AI知识库: 跟踪最新的IT/AI类资讯
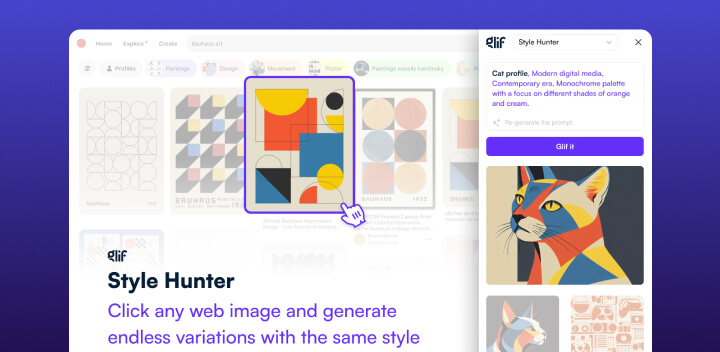
Glif StyleHunter:一个Chrome浏览器扩展
只需右键点击图像并输入你的提示词,就能将该图像风格直接应用到你想要创造的新图像上,无论是模仿那个风格,还是将其与其他风格结合创造出全新的作品。

谷歌在Bard谷歌地图和Imagen-2升级
谷歌在Bard谷歌地图和Imagen-2升级,亚马逊推出了人工智能购物助手“Rufus”
此外,亚马逊、Sam Altman、佐治亚理工学院、Meta、Arc 和 Anthropic 在人工智能方面取得了巨大进展。

Midjourney发布了Niji-v6
在创作疯狂的动漫图像和视频
在 Midjourney V6 中测试了新的 Niji 风格,并使用 Domo AI 对其进行了动画处理。
动漫武士超级英雄和恶棍!
使用 @runwayml #AI 视频工具和 Midjourney 新发布的 Niji v6 创建。



Media2Face:通过语音合成3D面部画面
Media2Face能够根据声音来生成与语音同步的、表现力丰富的3D面部动画。
同时允许用户对生成的面部动画进行更细致的个性化调整,如情感调整,“快乐”或“悲伤”等。
它还能理解多种类型的输入信息(音频、文本、图像),并将这些信息作为生成面部动画的指引。

机器人技术即将迎来它的ChatGPT时刻
机器人初创公司@Figure_robot 发布了一段视频
他们家的Figure-01机器人现在可以自己煮咖啡了
这是一个使用了端到端的人工智能系统,仅通过观察人类制作咖啡的录像,10小时内学会了制作咖啡的技能。

OpenAI 和微软正在洽谈支持人形机器人公司Figure
报道披露了 OpenAI 和微软与人形机器人公司 Figure 的融资谈判。
此轮融资对Figure的估值接近$2B。


马斯克人机接口 Neuralink 相关视频
想象一下,仅凭你的思维就能与亲人交流、上网浏览、甚至玩游戏的愉悦体验。
这一切,得益于在你大脑负责规划动作的区域植入一个既微小又不易察觉的装置。



Bard与GeminiPro在 Arena上超越了GPT-4
将其与 Google Sheets 结合起来,实现数据处理的自动化。
向您展示如何使用 Bard 来管理没有公式的电子表格:

人工智能广告,它们即将成为大事件
使用人工智能制作了一部戏剧、一部动作喜剧、一部纪录片和音乐视频。接下来:“Fragrance by Elle”,一个商业广告。
使用 @midjourney v6、@runwayml gen2、@Magnific_AI 高档制作。

Adept Fuyu-Heavy是专为数字代理设计的新型多模态模型
宣称是世界上第三大能力超强的多模态模型,仅次于GPT4-V和Gemini Ultra。
它特别擅长理解用户界面,这意味着可以解释和操作各种软件和应用程序的界面。
能够帮助用户执行各种任务,如自动化流程、响应查询、提供信息等。