蘋果公司於12月14日發布了名為Ferret的多模式大型語言模型,該模型不僅可以準確識別圖像並描述其內容。
它還可以識別和定位圖像中的元素,無論您如何描述它,Ferret都可以在圖像中準確地找到和識別它。
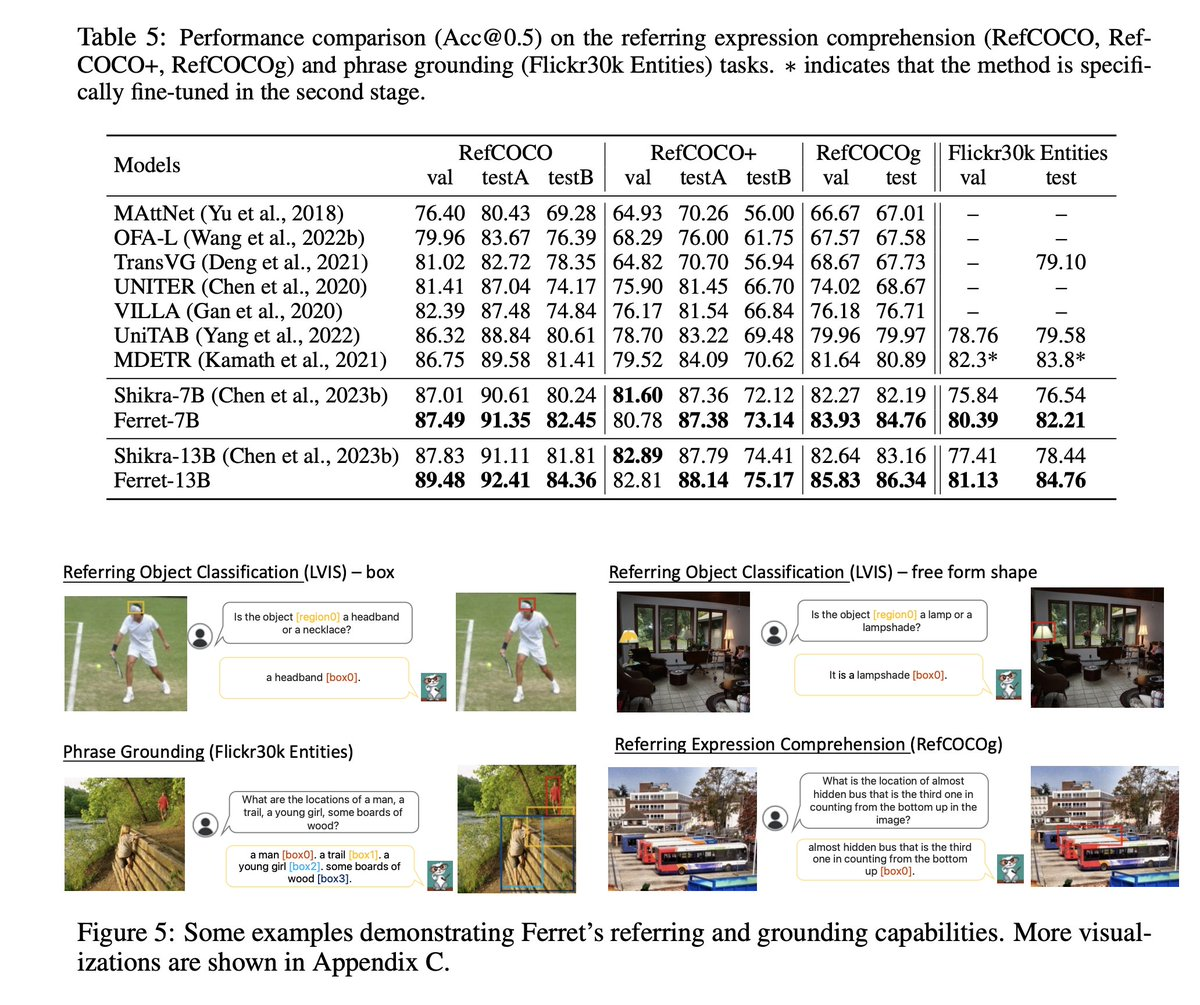
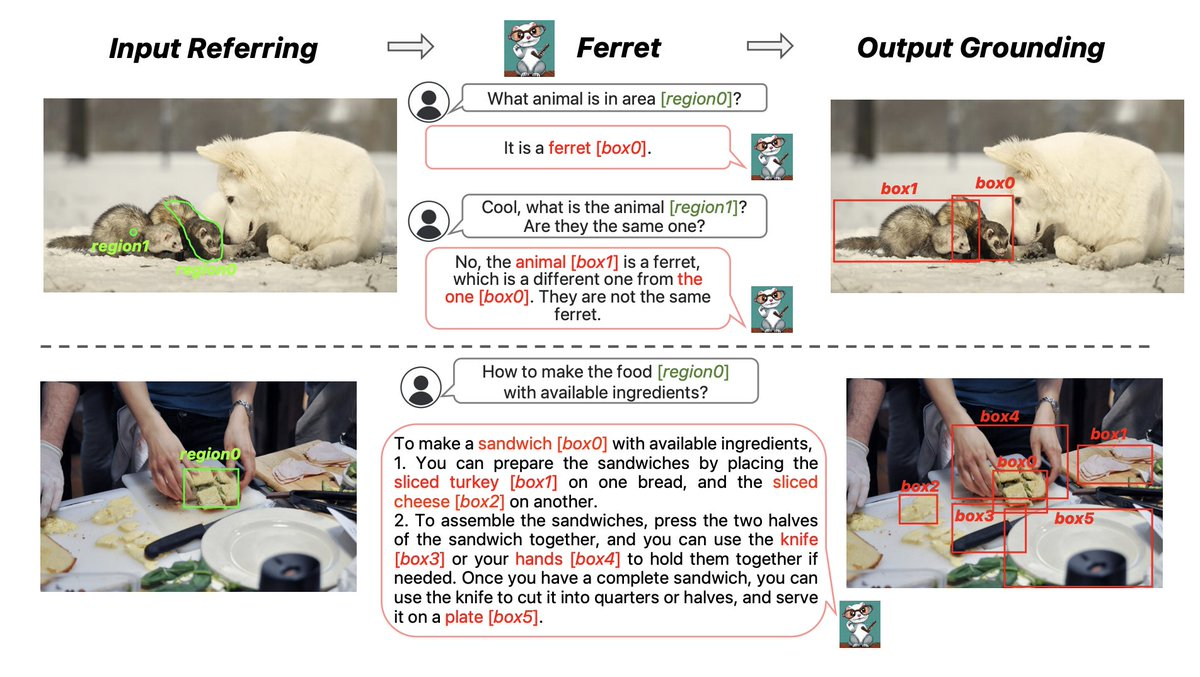

Ferret有兩個版本(7 B、13 B),為了增強Ferret模型的功能,蘋果收集了GRIT數據集。它包含110萬個樣本,包含豐富的分層空間知識。
主要功能和特點:
Ferret能夠理解和處理圖像和文本之間的複雜關係。這個模型的特別之處在於它能夠識別和定位圖像中的各種元素,無論它們的形狀或大小如何。
例如,在對話中引用圖像的特定部分或基於文本描述在圖像中查找特定對象。
Ferret就像一個智能系統,可以理解圖片和文字並將它們連接起來。無論您在文本中提到圖像的哪個部分,也無論您如何描述它,Ferret都會在圖像中準確地找到並識別它。
1.多模式理解:Ferret能夠處理和理解圖像(視覺信息)和文本(言語信息),這使得它能夠在許多不同的模式之間建立聯繫。
2.空間參考理解:它能夠識別和理解圖像中特定區域的含義,即使這些區域的形狀和大小不同。例如,如果文本提到圖像的特定部分,Ferret可以識別該部分指的是什麼。
3.理解複雜的文本描述:Ferret能夠理解各種類型的文本描述,無論是具體的還是抽象的。例如,「圖像中一輛紅色車輛旁邊的小狗」或「圖像右上角的笑臉」。
4.開放詞彙描述精確定位:根據這些文本描述,Ferret可以準確地在提供的圖像中找到並標記相應的對象或區域。例如,它可以識別並指出圖像中「小狗」或「笑臉」的確切位置。無論用戶如何描述他們想在圖像中找到什麼,Ferret都會理解並做出回應。
5.混合區域表示:Ferret使用創新的表示方法來處理圖像中的區域。此表示將離散坐標(例如點或邊界框的位置)與連續特徵(例如區域的視覺內容)相結合。這使得模型能夠理解和處理各種形狀和大小的區域,從而改善對圖像的空間理解。
6.空間感知視覺採樣器:為了處理不同形狀的區域,Ferret引入了空間感知視覺採樣器。該採樣器能夠根據區域的形狀和稀疏度提取視覺特徵,使模型能夠處理各種形狀的區域,從簡單點到複雜多邊形。
7.多樣的區域輸入:Ferret具有識別和理解圖像中各種類型區域的能力。
它可以處理以下類型的區域輸入:
點:Ferret能夠識別圖像中的特定點,例如用戶指定的特定位置。
邊界框:它可以識別和理解圖像中的邊界框,通常用於標記圖像中的對象或特定區域。
自由形式:Ferret還可以處理更複雜的自由形式,例如手繪輪廓、不規則形狀或任意多邊形。該功能允許更精確地識別和理解圖像中的複雜區域。
這種處理不同區域輸入的能力使Ferret在圖像理解方面具有高度靈活性和強大性,能夠適應各種應用場景和用戶需求。無論用戶提供簡單的點標記、規則的邊界框還是複雜的自由形狀,Ferret都可以準確地識別和處理它們。
8. GRIT數據集:GRIT數據集專門收集用於訓練和增強Ferret,包含110萬個樣本。
該數據集包含豐富的分層空間知識,這意味著它涵蓋了從簡單對象到複雜空間關係的一切內容。包含95 K難以攜帶的樣本,這些樣本是專門設計的具有挑戰性的樣本,旨在提高模型在困難情況下的穩健性和準確性。
主要表現:
1. Ferret-Bench評估:Ferret-Bench是為評估Ferret而引入的一系列新任務,包括參考描述、參考推理和對話中的定位。在這些任務上,與可用的最佳多模式大型語言模型(MLLM)相比,Ferret平均提高了20.4%。這一結果表明,Ferret在處理更複雜、更接近現實世界應用程式的任務方面具有顯著優勢。
2.改善物體錯覺:Ferret可以減少描述圖像細節時的錯誤或虛構內容,這在自動圖像描述和分析領域尤其重要。
它緩解了對象幻覺問題,從而減少了生成文本描述時對不存在對象的誤引用,提高了描述的準確性和可靠性。
3. Ferret不僅擅長傳統的參考和定位任務,而且可以更準確地理解和處理圖像中的空間信息和語義。它在需要引用/定位、語義、知識和推理的任務中也表現出色。
Ferret能夠更準確地描述圖像細節,從而減少生成文本時不存在對象的錯覺。通過其創新的方法和技術,它為空間理解和本地化的多模式語言模型提供了新的可能性,特別是在處理複雜的圖像和文本交互時。
適合廣泛的應用:
由於其強大的圖像和文本處理能力,Ferret適合廣泛的應用,包括圖像搜索、自動圖像注釋、交互式媒體探索等。
GitHub:https://github.com/apple/ml-ferret
論文: https://arxiv.org/abs/2310.07704