以下內容由原文翻譯而來
Florence-2是微軟在麻省理工學院許可下開源的輕量級視覺語言模型。該模型在字幕、對象檢測、接地和分割等任務中展示了強大的零樣本和微調能力。
儘管尺寸很小,但它的結果與大很多倍的型號(例如Kosmos-2)相當。該模型的優勢不在於其複雜的架構,而在於其大規模的LDA-5 B數據集,該數據集包含1.26億張圖像和54億個全面的視覺注釋。
您可以通過HF Space或Google Colab嘗試此模型。
統一表示
視覺任務多種多樣,空間層次和語義粒度各不相同。實例分割提供有關圖像中對象位置的詳細信息,但缺乏語義信息。另一方面,圖像字幕可以更深入地理解對象之間的關係,而不必參考它們的實際位置。
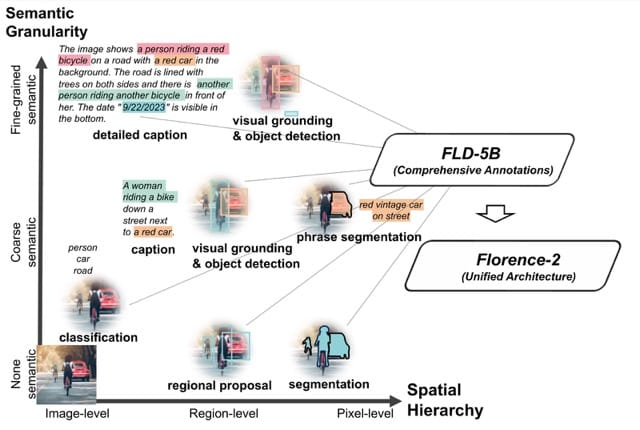
Florence-2的作者決定,他們不會訓練一系列能夠執行單個任務的個體模型,而是統一它們的表示並訓練一個能夠執行10多個任務的單個模型。然而,這需要一個新的數據集。
構建全面的數據集
不幸的是,目前沒有可用的大型統一數據集。現有的大規模數據集僅涵蓋單個圖像的有限任務。SA-1B是用於訓練Segment Anything(Sam)的數據集,僅包含掩蔽。COCO雖然支持更廣泛的任務,但規模相對較小。
欲了解更多信息,請參閱本視頻下方的文本描述中的原文、原始連結
感謝您觀看此視頻。如果您喜歡,請訂閱並點讚。謝謝
原文:https://blog.roboflow.com/florence-2/
阿爾西夫:https://arxiv.org/abs/2311.06242
擁抱臉:https://huggingface.co/microsoft/Florence-2-large
輸油管: